生产环境各组件调优总结
[ HDFS]
dfs.datanode.du.reserved 100g (计算方法 磁盘总容量*0.05+50g)其中50g适量即可
其他参数指定一些日志目录和datanode目录
rebalance阈值 2
不启用hdfs权限
启用zookeeper
还有一些进程的内存限制大小
记得配置HA
dfs.datanode.handler.count=30
dfs.namenode.handler.count=70
开启Service RPC端口
在默认情况下,service RPC端口是没有使用的,client和DataNode汇报,zkfc的健康检查都会公用RPC Server,当client的请求量比较大或者DataNode的汇报量很大,会导致他们之间相互影响,导致访问非常缓慢,开启之后,DN的汇报和健康检查请求都会走Service RPC端口,避免了因为client的大量访问影响,影响服务之间的请求,在HA集群中,可以在hdfs-site.xml中设置
【Hbase】
服务端
1.hbase.regionserver.handler.count:rpc请求的线程数量,默认值是10,生产环境建议使用100,也不是越大越好,特别是当请求内容很大的时候, 比如scan/put几M的数据,会占用过多的内存,有可能导致频繁的GC,甚至出现内存溢出。
2.hbase.master.distributed.log.splitting:默认值为true,建议设为false。关闭hbase的分布式日志切割,在log需要replay时,由master来负责重放
3.hbase.regionserver.hlog.splitlog.writer.threads:默认值是3,建议设为10,日志切割所用的线程数
4.hbase.snapshot.enabled:快照功能,默认是false(不开启),建议设为true,特别是对某些关键的表,定时用快照做备份是一个不错的选择。
5.hbase.hregion.max.filesize:默认是10G, 如果任何一个column familiy里的StoreFile超过这个值, 那么这个Region会一分为二,因为region分裂会有短暂的region下线时间(通常在5s以内),为减少对业务端的影响,建议手动定时分裂,可以设置为60G。
6.hbase.hregion.majorcompaction:hbase的region主合并的间隔时间,默认为1天,建议设置为0,禁止自动的major主合并,major合并会把一个store下所有的storefile重写为一个storefile文件,在合并过程中还会把有删除标识的数据删除,在生产集群中,主合并能持续数小时之久,为减少对业务的影响,建议在业务低峰期进行手动或者通过脚本或者api定期进行major合并。
7.hbase.hregion.memstore.flush.size:默认值128M,单位字节,一旦有memstore超过该值将被flush,如果regionserver的jvm内存比较充足(16G以上),可以调整为256M。
8.hbase.hregion.memstore.block.multiplier:默认值2,如果一个memstore的内存大小已经超过hbase.hregion.memstore.flush.size * hbase.hregion.memstore.block.multiplier,则会阻塞该memstore的写操作,为避免阻塞,建议设置为5,如果太大,则会有OOM的风险。如果在regionserver日志中出现”Blocking updates for ‘’ on region : memstore size <多少M> is >= than blocking <多少M> size”的信息时,说明这个值该调整了。
9.hbase.hstore.compaction.min:默认值为3,如果任何一个store里的storefile总数超过该值,会触发默认的合并操作,可以设置5~8,在手动的定期major compact中进行storefile文件的合并,减少合并的次数,不过这会延长合并的时间,以前的对应参数为hbase.hstore.compactionThreshold。
10.hbase.hstore.compaction.max:默认值为10,一次最多合并多少个storefile,避免OOM。
11.hbase.hstore.blockingStoreFiles:默认为7,如果任何一个store(非.META.表里的store)的storefile的文件数大于该值,则在flush memstore前先进行split或者compact,同时把该region添加到flushQueue,延时刷新,这期间会阻塞写操作直到compact完成或者超过hbase.hstore.blockingWaitTime(默认90s)配置的时间,可以设置为30,避免memstore不及时flush。当regionserver运行日志中出现大量的“Region has too many store files; delaying flush up to 90000ms”时,说明这个值需要调整了
12.hbase.regionserver.global.memstore.upperLimit:默认值0.4,regionserver所有memstore占用内存在总内存中的upper比例,当达到该值,则会从整个regionserver中找出最需要flush的region进行flush,直到总内存比例降到该数以下,采用默认值即可。
13.hbase.regionserver.global.memstore.lowerLimit:默认值0.35,采用默认值即可。
14.hbase.regionserver.thread.compaction.small:默认值为1,regionserver做Minor Compaction时线程池里线程数目,可以设置为5。
15.hbase.regionserver.thread.compaction.large:默认值为1,regionserver做Major Compaction时线程池里线程数目,可以设置为8。
16.hbase.regionserver.lease.period:默认值60000(60s),客户端连接regionserver的租约超时时间,客户端必须在这个时间内汇报,否则则认为客户端已死掉。这个最好根据实际业务情况进行调整
17.hfile.block.cache.size:默认值0.25,regionserver的block cache的内存大小限制,在偏向读的业务中,可以适当调大该值,需要注意的是hbase.regionserver.global.memstore.upperLimit的值和hfile.block.cache.size的值之和必须小于0.8。
18.dfs.socket.timeout:默认值60000(60s),建议根据实际regionserver的日志监控发现了异常进行合理的设置,比如我们设为900000,这个参数的修改需要同时更改hdfs-site.xml
19.dfs.datanode.socket.write.timeout:默认480000(480s),有时regionserver做合并时,可能会出现datanode写超时的情况,480000 millis timeout while waiting for channel to be ready for write,这个参数的修改需要同时更改hdfs-site.xml
jvm和垃圾收集参数:
export HBASE_REGIONSERVER_OPTS=”-Xms31g -Xmx31g -Xmn1g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=15 -XX:CMSInitiatingOccupancyFraction=70 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:/data/logs/gc-$(hostname)-hbase.log”
Client端
1.hbase.client.write.buffer:默认为2M,写缓存大小,推荐设置为5M,单位是字节,当然越大占用的内存越多,此外测试过设为10M下的入库性能,反而没有5M好
2.hbase.client.pause:默认是1000(1s),如果你希望低延时的读或者写,建议设为200,这个值通常用于失败重试,region寻找等
3.hbase.client.retries.number:默认值是10,客户端最多重试次数,可以设为11,结合上面的参数,共重试时间71s
4.hbase.ipc.client.tcpnodelay:默认是false,建议设为true,关闭消息缓冲
5.hbase.client.scanner.caching:scan缓存,默认为1,避免占用过多的client和rs的内存,一般1000以内合理,如果一条数据太大,则应该设置一个较小的值,通常是设置业务需求的一次查询的数据条数
如果是扫描数据对下次查询没有帮助,则可以设置scan的setCacheBlocks为false,避免使用缓存;
6.table用完需关闭,关闭scanner
7.限定扫描范围:指定列簇或者指定要查询的列,指定startRow和endRow
8.使用Filter可大量减少网络消耗
9.通过Java多线程入库和查询,并控制超时时间。后面会共享下我的hbase单机多线程入库的代码
10.建表注意事项:
开启压缩
合理的设计rowkey
进行预分区
开启bloomfilter
ZooKeeper调优
1.zookeeper.session.timeout:默认值3分钟,不可配置太短,避免session超时,hbase停止服务,线上生产环境由于配置为1分钟,如果太长,当regionserver挂掉,zk还得等待这个超时时间(已有patch修复),从而导致master不能及时对region进行迁移。
2.zookeeper数量:建议5个或者7个节点。给每个zookeeper 4G左右的内存,最好有独立的磁盘。
3.hbase.zookeeper.property.maxClientCnxns:zk的最大连接数,默认为300,无需调整。
4.设置操作系统的swappiness为0,则在物理内存不够的情况下才会使用交换分区,避免GC回收时会花费更多的时间,当超过zk的session超时时间则会出现regionserver宕机的误报
【HIVE】:
hive.exec.reducers.bytes.per.reducer =1g
hive.merge.mapredfiles = true //输出合并
hive.merge.smallfiles.avgsize = 64m //输出合并
hive.fetch.task.conversion = more
hive.exec.compress.output=true (如果impala需要访问结果表,可以不压缩)
mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec(与上条结合使用)
hive.exec.compress.intermediate = true
hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec(与上条结合使用)
hive.map.aggr=true
hive.exec.parallel =true
mapred.max.split.size=256000000 //输入合并
mapred.min.split.size.per.node=100000000 //输入合并
mapred.min.split.size.per.rack=100000000 //输入合并
hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat //输入合并
【yarn】
yarn.app.mapreduce.am.resource.mb=2000
AM最大堆堆栈 1.5g
NM最大堆内存 2g
RM最大堆内存 4g
jobhistory server最大堆内存 2g
客户端java堆内存 1.5g
mapreduce.map.memory.mb=4000
mapreduce.reduce.memory.mb=8000
mapreduce.map.java.opts.max.heap=3435973837
mapreduce.reduce.java.opts.max.heap=6871947674
yarn.nodemanager.resource.memory-mb=300g //单个nm全部可分配给容器的最大内存
yarn.nodemanager.resource.cpu-vcores=40//单个nm可分配给容器的最多cpu
yarn.scheduler.minimum-allocation-mb=2000 //最小容器内存
yarn.scheduler.increment-allocation-mb=1000//容器内存增量
yarn.scheduler.maximum-allocation-mb=8000 //最大容器内存
yarn.scheduler.maximum-allocation-vcores=4 //最大容器核数
yarn.nodemanager.vmem-check-enabled=false
mapreduce.shuffle.port=23526
【内存配置】
YARN以及MAPREDUCE所有可用的内存资源应该要除去系统运行需要的以及其他的hadoop的一些程序,总共保留的内存=系统内存+HBASE+es内存。
可以参考下面的表格确定应该保留的内存:

计算每台机子最多可以拥有多少个container,可以使用下面的公式:
containers = min (2CORES, 1.8DISKS, (Total available RAM) / MIN_CONTAINER_SIZE)
通过上面的计算,YARN以及MAPREDUCE可以这样配置:
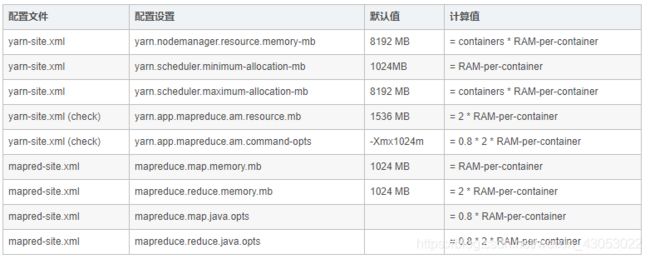
【IMPALA】
mem_limit = -1b
【KAFKA】
broker_max_heap_size = 2g
【KUDU】
memory_limit_hard_bytes=200g
block_cache_capacity_mb = 2g
maintenance_manager_num_threads = 2
-max_clock_sysn_error_usec=120000000
【OOZIE】
oozie.processing_timezone=GMT+0800
【SPARK】
spark.kryoserializer.buffer.max = 2047m
spark.network.timeout = 6000s
spark.executor.extraJavaOptions=-XX:MaxDirectMemorySize=4096m
num-executors
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
executor-memory
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:每个Executor进程的内存设置4G8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,就代表了你的Spark作业申请到的总内存量(也就是所有Executor进程的内存总和),这个量是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的总内存量最好不要超过资源队列最大总内存的1/31/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
driver-memory
参数说明:该参数用于设置Driver进程的内存。
参数调优建议:Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
spark.default.parallelism
参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
spark.storage.memoryFraction
参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
spark.shuffle.memoryFraction
参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
资源参数的调优,没有一个固定的值,需要同学们根据自己的实际情况(包括Spark作业中的shuffle操作数量、RDD持久化操作数量以及spark web ui中显示的作业gc情况),同时参考本篇文章中给出的原理以及调优建议,合理地设置上述参数。
【sqoop】
export HADOOP_COMMON_HOME=/opt/cloudera/parcels/CDH/lib/hadoop
export HAOOP_MAPRED_HOME=/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce
export HBASE_HOME=/opt/cloudera/parcels/CDH/lib/hbase
export HIVE_HOME=/opt/cloudera/parcels/CDH/lib/hive
export ZOOCFGDIR=/opt/cloudera/parcels/CDH/lib/zookeeper
export HIVE_CONF_DIR=/opt/cloudera/parcels/CDH/lib/hive/conf/
export HADDOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/cloudera/parcels/CDH/lib/hive/lib/*
【ZOOKEEPER】
maxSessionTimeout=240000
minSessionTimeout=12000
tickTime=6000
zookeeper server的java堆栈大小 10g