三级数据库知识点学习(三)
文章目录
- 一、B/S架构和C/S架构
-
- 1.架构
- 2.B/S架构
- 3.C/S架构
- 二、RAID 10、RAID 5
-
- 1.RAID
- 2.RAID 0
- 3.RAID 1
- 4.RAID 10
- 5.RAID 5
- 6.RAID 10与RAID 5的共同点与区别
- 三、类图的4种箭头表示
- 四、Case when语句用法
- 五、标量函数
-
- 1.定义
- 2.创建标量函数的语法
- 六、SQL Sever Agent
- 七、差异备份
- 八、关联规则
- 九、元数据
- 十、差操作
一、B/S架构和C/S架构
1.架构
架构是形成单个命名空间的数据库实体的集合。架构与用户的关系是一对多的关系。架构相当于数据库对象的容器,在同一数据库中架构不能重名。架构是数据库中的逻辑命名空间,同一数据库中的不同架构中可以存在同名表。在同一架构中可以定义表、视图等不同数据库对象。
2.B/S架构
在上一篇中已经提到过B/S结构了,这里是为了加深对此知识点的理解而写的。
- 基本概念
B/S是Browser/Server,即浏览器/服务器架构。Browser指的是Web浏览器,极少数事务逻辑在前端实现,但主要事务逻辑在服务器端实现。 - B/S三层体系结构
B/S三层体系结构可以定义为
(1)客户机上的表示层
(2)中间的web服务器层
(3)中间的数据库服务器层
3.C/S架构
- 基本概念
C/S是Client/Server,即客户端/服务器端架构,一种典型的两层架构。客户端包含一个或多个在用户的电脑上运行的程序。服务器端有两种,一种是数据库服务器端,客户端通过数据库连接访问服务器端的数据;另一种是Socket服务器端,服务器端的程序通过Socket与客户端的程序通信。 - 优点
界面和操作可以很丰富
安全性能可以很容易保证,实现多层认证也不难
由于只有一层交互,因此响应速度较快 - 缺点
适用面窄,通常用于局域网中
用户群固定,由于程序需要安装才可使用,因此不适合面向一些不可知的用户
维护成本高,发生一次升级,则所有客户端的程序都需要改变
二、RAID 10、RAID 5
1.RAID
RAID, 磁盘阵列,是一种将若干物理硬盘组合成一个新的存储设备,同时提供额外的备份和纠错功能的技术。用于解决单个磁盘访问速度慢,容量小,安全性不够的传统缺陷。
2.RAID 0
RAID 0是最简单的RAID模式,同时也是RAID 10、RAID 50、RAID 60等复杂模式的基础。
RAID 0 的最小存储单位是条带,多块磁盘分解成若干条带,再从逻辑上组合成一块连续的虚拟硬盘。因此 RAID 0 具备并发的操作能力。
- 优点
写速度通常会高于单块磁盘。 - 缺点
据安全性不够,任意一块磁盘掉线后整个设备不可用,数据安全性最差。
3.RAID 1
RAID 1 是多副本模式,同时使用两块或两块以上的磁盘存储同一份数据。写入时,数据同时写入所有磁盘;读取时,选择任意磁盘读取。读取速度与单块硬盘一致。
- 优点
可以容忍任意磁盘掉线,只要最终还能剩下一个盘,数据就可用。所以 RAID 1 模式下数据安全性非常强。 - 缺点
写入速度比较慢,因为需要同时写入多个副本。
4.RAID 10
RAID 10 模式是 RAID 1 和 RAID 0 顺序嵌套组合。
RAID 10 是所有磁盘先用 RAID 1 组合起来,再用 RAID 0 模式组成一个虚拟磁盘设备。如果 RAID 1 的副本数量是 n,那么设备容量是所有磁盘总容量的 1/n。这个模式兼顾了 RAID 0 无限扩容和 RAID 1 数据镜像备份的优点。最小能容忍 n-1 个磁盘掉线,最大能接受总磁盘数量的 (n-1)/n 磁盘掉线。
因为 RAID 0 带条并行分布的特点,RAID 10 的读写速度会比 RAID 1 快。
相应的还有 RAID 01 模式。RAID 01 的组成方式和 RAID 10 相反,先用 RAID 0 将所有磁盘组合成两组磁盘,再把两组磁盘用 RAID 1 组合成一个带备份的磁盘。这个模式的优点是数据读写速度更快,缺点是数据安全性不佳,一块硬盘掉线就会导致整个 RAID 0 磁盘组掉线,极端情况下两块硬盘就可以导致所有数据丢失。
5.RAID 5
RAID 5 是带数据校验的模式。
- 校验原理
把所有数据以条带为单位,均匀的分割成若干个小块,比如 A1, A2 … An 。然后把所有数据块累加,得到校验数据块EA,某个数据块可以由其他数据块和校验数据块计算生成AM。
因此任意一个数据块消失,都可以通过校验数据恢复。
实际操作中,加法有进位的问题,校验数据块会大于普通数据块,不利与数据的均匀分布。 - 实际校验
在实现校验算法的时候,RAID 5 用的是布尔操作的异或运算:
E = A1 ^ A2 … An
校验公式就变成了:
Am = EA ^ A1 ^ A2 … An
由校验算法的原理可知,RAID 5 最多允许一块磁盘掉线。如果掉线的数据盘,相应数据由其他数据盘和校验盘计算生成;如果掉线的是校验盘,则数据盘正常对外提供读写功能。
所以如果磁盘总量是 n 的话,RAID 5 的可用磁盘空间是总磁盘容量的 (n-1)/n 。
和 RAID 10 一样,RAID 5 也能和 RAID 10 嵌套组合起来,做成 RAID 50 模式。
6.RAID 10与RAID 5的共同点与区别
- RAID 10比RAID 5在写数据上更稳定。
- RAID 10 和 RAID 5 都是常用的 RAID 模式。
- RAID 10 是一个安全性极佳的存储方案,优点是读取速度极高,数据安全性极好,结构简单,故障后重建速度快。缺点是磁盘利用率低,成本高,写入效率低。
- RAID 5 提供了一个开销比较小的安全存储方案。优点是磁盘冗余度低,存储成本低。缺点是需要额外计算校验值,所以写入速度极慢,CPU 开销大;同时只能允许一块磁盘掉线,数据安全性不如 RAID 10 ;故障后重建也非常比多副本模式长很多。
三、类图的4种箭头表示
- 类的UML表示:空心三角实线

表示轿车和跑车都是汽车。 - 接口的UML表示:空心三角虚线

表示汽车具有驾驶接口。 - 聚合关系的UML表示:空心菱形实线
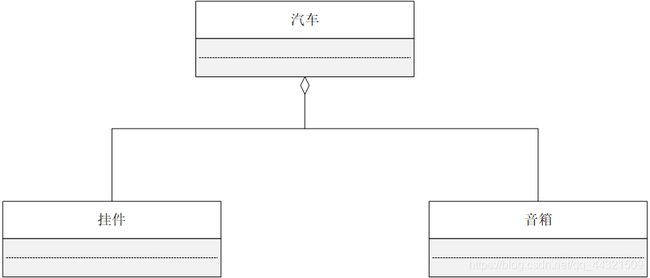
表示汽车可以拥有挂件和音箱。 - 合成关系的UML表示:实心菱形实线

表示车轮和车窗都是汽车不可缺少的一部分。
四、Case when语句用法
Case when 语句是赋值查询。
如简单的赋值查询数据库表示性别,1表示男,2表示女。
Case sex
When ‘1’ then ‘男’
When ‘2’ then ‘女’
Else ‘其他’
End
如果查询内包含判断式。在查询成绩时,希望将成绩按“优”、“良”、“中”、“及格”和“不及格”形式显示。
Case
When grade between 90 and 100 then ‘优’
When grade between 80 and 89 then ‘良’
When grade between 70 and 79 then ‘中’
When grade between 60 and 69 then ‘及格’
Else ‘不及格’
End
五、标量函数
1.定义
SQL Server标量函数接受一个或多个参数并返回单个值。
标量函数可帮助简化代码。 例如,可能有许多查询中出现的复杂计算。可以创建一个标量函数来封装公式并在查询中使用它,而不是在每个查询中包含公式。
2.创建标量函数的语法
CREATE FUNCTION [schema_name.]function_name (parameter_list)
RETURN data_type AS
BEGIN
statements
RETURN value
END
其中
- schema_name:架构名称,可自行定义,如果没有明确指定它,SQL sever默认使用dbo。
- function_name:函数名称,可自行定义。
- parameter_list:指定参数列表。
- data_type:指定返回值的数据类型,如int。
- 在函数主题内,即BEGIN内,必须包含一个RETURN语句来返回一个值。
(ps:这里作者也不太理解,仅仅记住了语法而已,因为做到过一道题就是考察标量函数的语法的)
六、SQL Sever Agent
SQL Sever Agent是一个任务规划器和警报管理器。
在实际应用和环境下,您可以将那些周期性的活动定义成一个任务,而让其在SQL Server Agent的帮助下自动运行;假如您是一名系统管理员,则可以利用SQL Server Agent向您通知一些警告信息,来定位出现的问题从而提高管理效率。
SQL Sever Agent主要包括以下几个组件:
- 作业
- 警报
- 操作
七、差异备份
差异备份指备份自上次完全备份之后有变化的数据。
- 全量备份:
备份所有文件 - 增量备份:
备份自上一次备份后的全部改动和新文件
差异备份相比较全量备份和增量备份,在备份速度、恢复速度、空间要求三个方面都是居中的。
| 全量备份 | 增量备份 | 增量备份 | |
|---|---|---|---|
| 备份速度 | 最慢 | 最快 | 较快 |
| 恢复速度 | 最快 | 最慢 | 较快 |
| 空间要求 | 最多 | 最少 | 较多 |
八、关联规则
关联规则是形如X→Y的蕴涵式,其中,X和Y分别称为关联规则的先导和后继。
关联规则挖掘过程主要包含两个阶段:第一阶段必须先从资料集合中找出所有的高频项目组,第二阶段再由这些高频项目组中产生关联规则。
关联规则的强度可以用它的支持度(s)和置信度(c)度量。
- 支持度:确定规则可以用于给定数据集的频繁程度。
支持度计算公式:s(X->Y)=σ(X∪Y)/N - 置信度:确定Y在包含X的事物中出现的频繁程度。
置信度计算公式:c(X->Y)=σ(X∪Y)/σ(X)
实例:
设有如下所示的某商场购物记录集合,每个购物篮中包含若干商品
| 购物篮编号 | 商品 |
|---|---|
| 1 | 面包,牛奶 |
| 2 | 面包,啤酒,鸡蛋,尿布 |
| 3 | 牛奶,啤酒,尿布,可乐 |
| 4 | 面包,牛奶,啤酒,尿布 |
| 5 | 面包,牛奶,尿布,可乐 |
现要基于该数据集进行关联规则挖掘。如果设置最小支持度为60%,最小置信度为80,则如下关联规则中,符合条件的是()
A.啤酒->尿布
B.(面包,尿布)->牛奶
C.面包->牛奶
D.(面包,啤酒)->尿布
从题目中可看出事务总数N是5,A的{啤酒、尿布}支持数σ(X∪Y)是3,{啤酒}的支持数σ(X)是3,所以s=0.6,c=1。同理得B:s=04,c=2/3,C:s=0.6,c=0.75,D:s=0.4,c=1。所以答案A为正确答案。
九、元数据
元数据是关于数据的数据,即描述数据信息的数据。
作用:
- 解释数据的属性
- 描述数据的内容和含义
举例:
数据库中的数据字典、数据表结构说明文档都是元数据。
生活中如:姓名、身高、年龄、体重这些解释数据的属性、描述数据的内容和含义的都是元数据。
十、差操作
集合操作主要包括并操作union、交操作intersect和差操作expect。
这里介绍差操作的使用方法。
人们经常会查询一个对象拥有而另一个对象不拥有的属性,
如查询C01顾客购买过但是C02顾客没有购买过的商品,语句可写为
Select 商品号 from 购买表 where顾客号= ’C01’
Expect select 商品号 from 购买表 where 顾客号= ‘C02’;
此处需注意参加集合操作的各查询结果的列数必须相同,对应项的数据类型也必须相同。
(PS:感谢各位读者对作者的支持,上一篇文章三级数据库知识点学习(二)访问量再创新高。作者作为萌新,什么都还不懂,一直在向各位大佬学习,你们的访问就是对我最大的支持。这是作者坚持写文章的第四周,如果文章中有什么错误的或者大佬们有更好的见解的地方,请赐教~愚定多加学习改正!)