4 向量、SIMD和GPU体系结构中的数据级并行
文章目录
- 4.1 引言
- 4.2 向量体系结构
- 4.2.1 VMIPS
- 4.2.2 向量处理器如何工作:一个示例
- 4.2.3向量执行时间
- 4.2.7内存组:为向量載入/存储单元提供带宽
- 4.4 图形处理器
- 4.4.1 GPU编程
- 4.4.2 NVIDIA GPU计算结构
- 4.4.3 NVIDA GPU指令集体系结构
- 4.4.4 GPU中的条件分支
- 4.4.5 NVIDA GPU存储器结构
- 图4-12是NVIDIA GPU的存储器结构。
- 每个多线程SIMD处理器本地的片上存储器称为本地存储器。
- 整个GPU和所有线程块共享的片外DRAM称为GPU存储器。
- 主机的系统处理器可读或写GPU存储器。
- GPU不依赖大型缓存来包含应用程序的整个工作集,
- 尽管隐藏存储器延迟是一种优选方法,但注意,最新的GPU和向量处理器都已经添加缓存。
- 为提高存储器带宽、降低开销,
- 参考链接
4.1 引言
- SMID体系结构(1章介绍)
- 人们总问一问题:有多少应用程序拥有大量的DLP
- 50年后,答案不只包含科学运算中的矩阵计算,还包括媒体图像和声音处理。
- 单条指令可启动许多数据运算,so SIMD在能耗效率方面要比MIMD更高效
- MIMD每进行一次数据运算都需要提取和执行一条指令。
- 这两个答案使SIMD对于个人移动设备极吸引力。
- SIMD与MIMD比的最大优势:
- 由于数据操作是并行的,所以程序员可以采用顺序思维方式但却能获得并行加速比。
- 本章介SIMD的3变体:向量体系结构、多媒体SIMD指令集扩展和GPU
- 第一种变体要比其他两早30年
- 它实际上就是以流水线形式来执行许多数据操作。
- 与其他变体比,向量体系结构更易理解和编译,但过去对于微处理器来说太贵,这看法直到最近才变。
- 此体系结构的成本,一部分用在晶体管上,另一部分用于提供足够的DRAM带宽,
- 它依赖缓存来满足传统徽处理器的存储器性能要求。
- 二变借用SIMD名称来表示基本同时进行的并行数据操作,
- 在今天支持多媒体应用程序的大多数指令集体系结构中都可以找到这种变体。
- x86的SIMD指令扩展是在1996年以MMK开始的,接下来的10年间出现了几个SSE(流式SIMD
扩展)版本,到今天的AVX(高级向量扩展)。 - 为使x86计算机达到最高计算速度,
- 需要用这些SIMD指令,特别对浮点
- 3变来自GPU社区
- 它的潜在性能高于当今多核计算机
- GPU的一些特征与向量体系同,
- 但有自己的一些独特特征,部分原因在于它们的发展生态系统。
- 在GPU的发展环境中,除了GPU及其图形存储器之外,还有系统处理器和系统存储器。
- 为辦识这些差别,GPU社区将这种体系结枃称为异类。
- 对大量DLP的问题,
- 这三种SIMD变体都有一个共同的好处:
- 与经典的并行MIMD编程相比,
- 程序员更轻松。
- 为对比SDMD与MIMD的重要性,
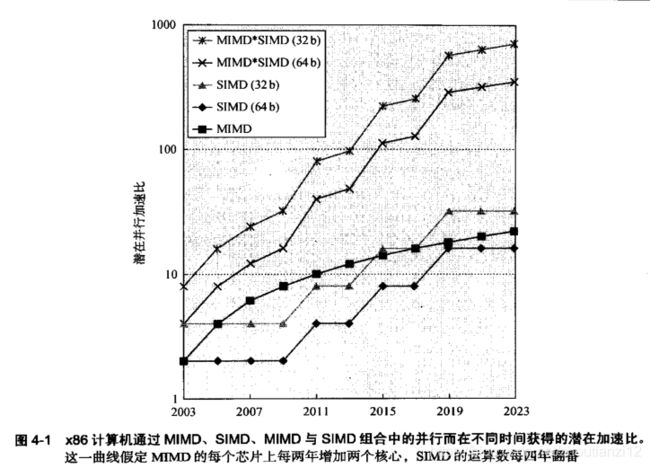
- 图4-1
- x86中MIMD的核数与SIMD模式中每个时钟周期的32位及64位运算数随时间的变化
- 对x86,
- 预期每芯片上每两年加两核,SIMD的宽度四年翻一番
- 给定这些假设,
- 在接下来10年,由SIMD并行获得的潜在加速比为MIMD并行的两倍。
- MIMD并行最近受到的关注要多得多,但理解SIMD并行与理解MIMD并行ー样重要。
- 对同时具有数据级并行和线程级并行的应用程序,2020年的潜在加速比将比今天的加速比高一个数量级
- 让架构师理解向量为什么比多媒体SIMD更具一般
- 向量与GPU体系结构之间的相似与区别。
- 由于向量体系结构是多媒体SIMD指令的超集(包括一个更好的编译模型),
- 且GPU与向量体系结构有一些相似性,
- 所以先从向量体系结构人手,
- 下节介向量体系结构,
- 附录G对这一主题的讨论要深人多。
4.2 向量体系结构
- 向量体系结构获得在存储器中散布的数据元素集,
- 将它们放在一些大型的顺序奇存器堆中
- 对这些寄存器堆中的数据进行操作,然后将结果放回存储器中。
- 一条指令对数据向量执行操作,从而会对独立数据元素进行数十个“寄存器一寄存器”操作。
- 这些大型寄存器堆相当于由编译器控制的缓冲区,
- 用于隐藏存储器延迟、充分利用存储器带宽。
- 向量载入和存储是尝试流水化的,
- 所以这个程序仅在每个向量载人或存储操作中付出较长的存储器延迟时间,
- 而不需在每个元素时耗费这一时间,
- 这一延迟时间分散在如64个元素
- 向量程序尽力使存储器保持繁忙
4.2.1 VMIPS
- 先看一个向量处理器,由图4-2的主要组件组成。
- 这个处理器大体以Cay-1为基础,是本节讨论的基础。
- 将这种指令集体系结构称为VMIPS;它的标量部分为MIPS,它的向量部分是MIPS的逻辑向量扩展。
- 这一小节的其他部分研究 VMIPS的基本体系结构与其他处理器有什么关系。
- VMIIPS指令集体系结构的主要组件如下所示。
- 向量寄存器
- 每个向量寄存器都是一个固定长度的寄存器组,保存一个向量。
- VMIPS有8个,每个保留64个元素,元素的宽度为64。
- 向量寄存器堆霑要提供足够的端口,向所有向量功能单元馈送数据。
- 这些端口允许将向量操作高度重叠,发送到不同向量寄存器。
- 利用一对交又交换器将读写端口(至少共有16个读取端口和8个写入端口)连接到功能单元的输入或输出。
- 向量功能单元
- 每个单元都完全实现流水化,可在每个时钟周期开始一个新操作。
- 需有个控制单元来检测冒险,
- 既包括功能单元的结构性冒险,又包括关于寄存器访问的数据冒险。
- 4-2显示有5个功能单元。
- 为简,仅关注浮点功能单元。
- 向量载入/存储单元
- 这个向量存储器单元从存储器中载入向量或者将向量存储到存储器中。
- VMIPS向量载入与存储操作是完全流水化的,所以在初始延迟之后,可以在向量寄存器与存储器之间以每个时钟周期一个字的带宽移动字。
- 这个单元通常还会处理标量载入和存储。
- 标量寄存器集合
- 供数据,作为向量功能单元的输入,计算传送给向量载人存储单元的地址。
- MIPS的32个通用和32个浮点
- 在从标量寄存器堆读取标量值时,向量功能单元的一个输入会闩锁住这些值。
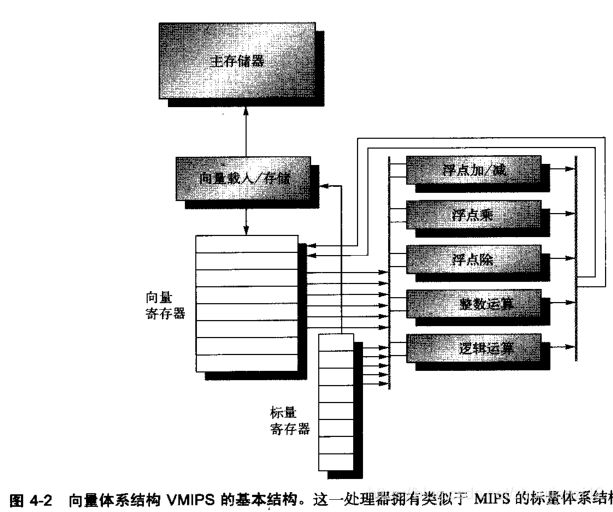
- VMPS的基本结构。
- 拥有类似于MIPS的标量体系结构。
- 有8个64元素向量寄存器,所有功能单元都是向量功能单元。
- 这一章为算术和存储器访问定义了特殊的向量指令。
- 图中显示用于逻辑运算与整数运算的向量单元,所以VMPS看起来像是一种通常包含此类单元的标准向量处理器;
- 但我们不会讨论这些单元。
- 这些向量与标量寄存器有大量读写端口,允许同时进行多个向量运算。
- 一组交叉交换器(粗灰线)将这些端口连接到向量功能单元的输人和输出
- 表4-1列出VMIPS向量指令。
- 向量运算的名字与标量MIPS指令相同,但后面加“vv"。
- ADDVV.D就是两个双精度向量的加法。
- 向量指令的输入
- 一对向量寄存器(AW.D),
- 一个向量和一个标量,附加“VS来标识(ADDVS.D)。
- 后种情况下,所有操作使用标量寄存器的相同值来作为一个输人:将向量寄存器中的每个元素都加上标量寄存器的内容。
- 向量功能单元在发射时获得标量值的一个副本。
- 多数向量运算有一个向量目标寄存器,一些会产生标量值,这个值将存储在标寄中。
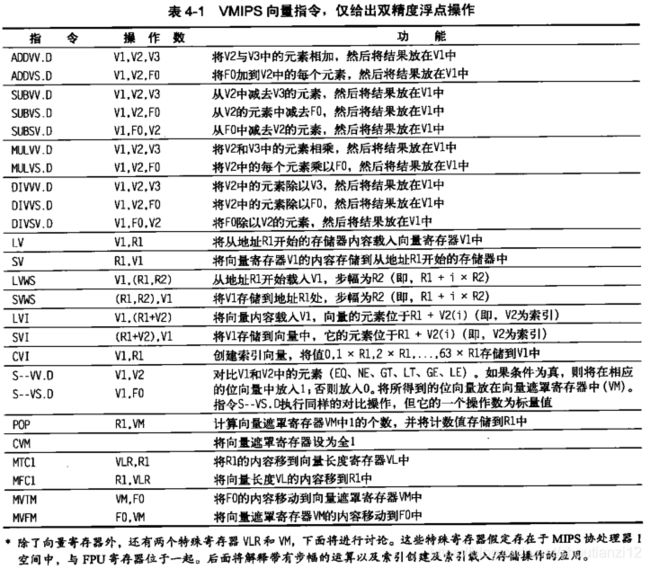
- LV和SV:向量载入和向量存储,载入或存储整个双精度数据向量。
- 载人或存储的向寄,MIPS通寄,是该向量在存储器中的起始地址。
- 还需要两个通用寄存器向量长度寄存器和向量遮罩寄存器。
- 向量长度不是64时,
- 循环中涉及IF语句时。
- 功率瓶颈使架构师看重具有以下特点的体系结构:能够提供高性能,又不要高度乱序超标量处理器的能耗与设计复杂度。
- 向量指令天生就与这一趋势吻合,架构师可用它们来提高简单循序标量处理器的性能,又不会显著增大能耗要求和设计复杂度
- 实践中,开发人员可采用向量指令的方式来表达许多程序,
- 数据级并行可以高效地在复杂乱序设计中运行, Kozyrakis和 Paterson[2002]证明了这点。
- 用向量指令,系统可采用许多方式对向量数据元素进行运算,包括对许多元素同时操作。
- 因为有了这种灵活性,向量设计可以采用慢而宽的执行单元,以较低功率获得高性能。
- 向量指令集中各个元素是相互独立,不要成本高昂的相关性检查就能调整功能单元,
- 而超标量处理器是需要进行检查
- 向量本身就可容纳不同大小的数据。
- 如果一个向量寄存器可以容纳64个64位元素,同样可容纳128个32位、256个16位,甚至512个8位。
- 向量体系结构既能用于多媒体应用,又能用于科学应用,就是因为具备这种硬件多样性
4.2.2 向量处理器如何工作:一个示例
- 查看VMIPS的向量循环,可更好地理解向量处理器。
- 看一个典型的向量问题SAXPY或 DAXPY循
环,它们构成了 Linpack基准测试的内层循环。 - SAXPY(single-- precision a x X plus Y);
- DAXPYdouble precision a xX plus Y)。
- Linpack是一组线性代数例程, Linpack基准测试包括执行高斯消去法的例程
- 现假定向量寄存器的元素数或者说其长度为64,
- 与我们关心的向量运算长度匹配。(稍后取消这一限制)
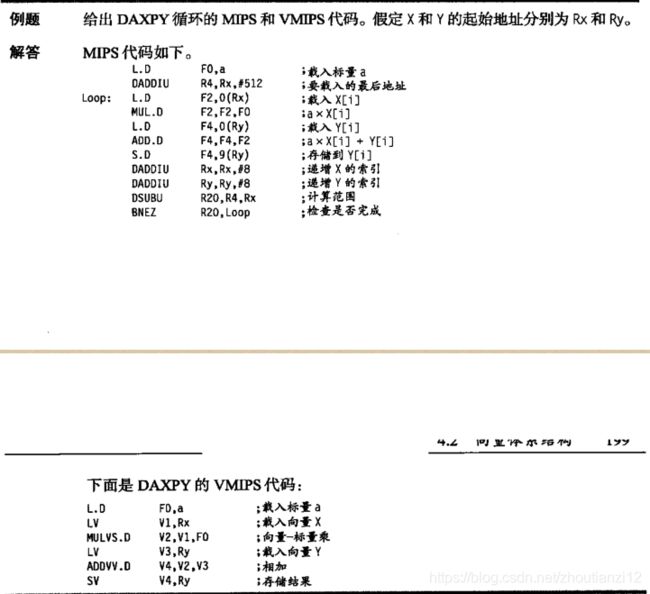
- 向量处理器大幅缩减动态指令带宽,仅执6条,而MIPS600。
- 向量运算对64个元素执行,MIPS中差不多占据一半循环的开销指令在VMPS中不存在。
- 当编译器为这样一个序列生成向量指令时,所得到的代码会将大多数时间花费在向量运行模式中,将这种代码称为已向量化或可向量化。
- 如果循环的迭代之间没有相关性(这种相关被称为循环间相关,见4.5节),那么这些循环就可以向量化。
- 另一个区别是流水线互锁的频率。
- MIPS中,每个ADD.D都必须等待MUL.D,每个S.D都等AOD.D。
- 向量中,每个向量指令只会因为等待每个向量的第一个元素停顿,后续元素会沿着流水线顺畅流动。
- 因此,每条向量指令仅需要一次流水线停顿,而不是每个向量元素需一次。
- 向量架构师将元素相关操作的转发称为链接( chaining),因为这些相关操作是被“链接”在一起的。
- 例子中,MIPS中的流水线停顿頻率比VMPS高64。
- 软件流水线或循环展开(见附录H)可减少MPS中的流水线停顿,但难缩减指令带宽方面的差別。
4.2.3向量执行时间
here!!!
4.2.7内存组:为向量載入/存储单元提供带宽
- 载入存储向量单元比算术功能单元的行为复杂。
- 载入操作的开始时间
- 它从存储器向寄存器中载入第一个字的时间。
- 如果在无停顿情况下提供向量的其他元素,那么向量初始化速率就等于提取或存储新字的速度。
- 这一初始化速率不一定是一个时钟周期,因为存储器组的停顿可能降低有效吞吐量,这一点不同于较简单的功能单元
- 一般情况,载入存储单元的起始代价要高于算术单元的这一代价
- 在许多处理器中要多于100周期。
- 对于 VMIPS,我们假定起始时间为12周期,与Cray-1相同。
- 最近的向量计算机使用缓存来降低向量载入与存储的延迟
here!!!
4.4 图形处理器
这儿没写
4.4.1 GPU编程
- CPU程序员的挑战在GPU上获得出色性能,
- 还协调系统处理器与GPU上的计算调度、
- 系统存储器与GPU存储器间的数据传输
- 本节后面将看到,
- GPU几乎拥有所有可以由编程环境捕获的并行类型:
- 多线程、MIMD、SIMD,甚至还有指令级并行。
- GPU几乎拥有所有可以由编程环境捕获的并行类型:
- NVIDIA开发与C类似的语言和编程环境,通过克服异质计算及多种并行带来的双重挑战来提高GPU程序员的效率
- “计算统一设备体系结构”( Compute Unified Device Architecture)
- CUDA为系统处理器(主机)生成C/C++,
- 为GPU(CUDA中的D)生成C和C++方言
- 类似的编程语言是OPENGL,几家公司共同开发,
- 为多种平台提供一种与供应商无关的语言
- NVIDIA认为这些并行形式的统一主题就是CUDA线程
- 以这种最低级别的并行作为编程原型,编译器和硬件可将数千CUDA线程聚合在一起,利用CPU中的各种并行类型:
- 多线程、MIMD、SIMD和指令级并行
- 因此, NVIDIA将CUDA编程模型定义为“单指令多线程”(SIMT)
- 这些线程进行分块,执行时32个线程一组,称线程块
- 将执行整个线程块的硬件称为多线程SIMD处理器
每个线程块是32个线程,这32个线程可以用一条指令搞完,每个16个车道的东西就是一个SIMD处理器
- GPU(设备)与系统处理器(主机)
- device__或__global,用__host__后者
- 被声明为__device__或 __global__functions的CUDA变量被分配给GPU存储
- 供所有多线程SIMD处理器访问
- GPU内核函数
- name<<
- 代码大小(块)
- 块的大小(线程)
- name<<
- 块识别符(blockIdx)和每个块的线程识别符(threadIdx)
- CUDA还为每个块的线程数提供了一个关键字(blockDim),
- 等于每个块里面的线程个数啊
- CUDA还为每个块的线程数提供了一个关键字(blockDim),
所有的SIMD处理器都可以搞到GPU内存上取东西
每个线程的下标:blockDim*blockIdx+threadIdx,但是下面人家写的是blockDim.x * blockIdx.x+threadIdx.x
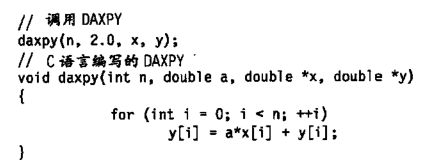
- 在一个多线程SIMD处理器中启动n个线程
- 每个向量元素一个线程,
- 每个线程块256个CUDA线程
- 根据块ID、
- 每个块的线程数
- 线程ID来计算相应的元素索引

- 所有迭代都
- 与其他迭代相独立
- 每个循环迭代都是个独立线程
- 向量化编译器也要求循环的迭代间无相关性,
- 这种相关被称为循环间相关,4.5节介绍
- 明确指定
- 网格大小及每个SIMD处理器中线程数
- dimGrid和线程块里的thread数!
- 明确指出CUDA中的并行
- 由于为每个元素都分配了一个线程
- so在向存储器中写结果时不要在线程间实行同步
每个内核都是一个格子,格子由块组成,块里面有很多thread
- 行执行和线程管理由GPU硬件负责,不由应用程序或OS
- 为简化硬件处理的排程,
- CUDA要求线程块能按任意顺序独立执行
- 尽管不同的线程块可用
- 全局存储器中的原子存储器操作进行协调
- 但它们之间不能直接通信
每个线程块独立干活
- 许多GPU硬件概念在CUDA中不明显。
- 生产效率来看,好事,
- 但重视性能的程序员用CUDA编程时须时刻惦记GPU硬件。
- 知道需将控制流中的32个线程分为一组
- 以从多线程SIMD处理器中获得最佳性能,
- 并在每个多线程SIMD处理器中另外创建许多线程,
- 以隐藏访问DRAM的延迟,稍后将解释原因
- 它们还需要将数据地址保持在一个或一些存储器块的局部范围内,
- 以获得所期望的存储器性能。
还需要将一些数据放在一些特定范围,这样还可以获得存储器性能啊
- 和许多并行系统一样,CUDA在生产效率和性能间折中
- 提供一些本身固有的功能,让程序员能显式控制硬件
- 一方面是生产效率,另一方面是使程序员能够表达硬件所能完成的所有操作,并行计算中,这两方面经常竞争
- 了解编程语言在这著名的生产效率与性能大战中如何发展,
- 了解CUDA是否能够在其他GPU或者其他类型的体系结构中变得普及
- 将非常有意义
4.4.2 NVIDIA GPU计算结构
- 为什么GPU有自己的体系结构类型,为什么有与CPU独立的专门术语
- 理解GPU的一个障碍就是术语,有些词汇的名称甚至可能导致误解
- 克服这一障碍的难度很大,这章多次重写就是例证
- 既能理解GPU体系结构,
- 又能学习许多采用非传统定义的GPU术语,
- 最终的解决方案是用CUDA术语来描述软件
- 用更具描述性的术语来介绍硬件,有时还借用OpenCL的术语
- 在用我们的术语解释GPU体系结构之后,
- 再将它们对应到NVIDIA GPU的官方术语
- 本节使用的一些更具描述性的术语、主流计算中的最接近术语、官方 NVIDIA GPU术语,以及这些术语的简短描述。
- 本节后续用该表左侧描述性术语来解释GPU徽结构
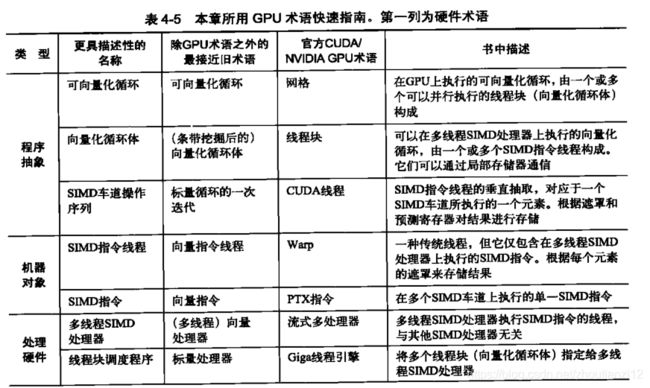
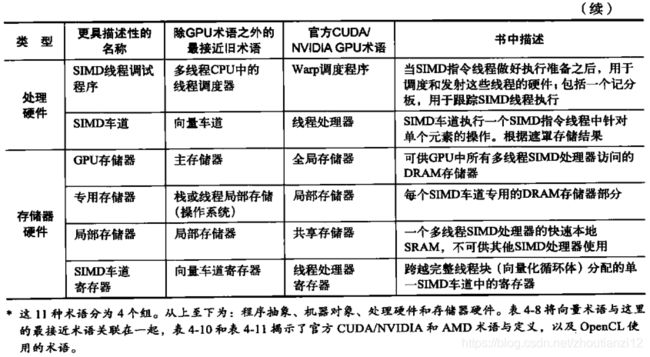
- 用上面CUDA并行编程语言的术语,以Fermi体系结构为例(见4.7节)
- 和向量体系结构一样,GPU只能很好解决数据级并行
- 这两种类型都拥有集中-分散数据传送和遮罩寄存器,
- GPU的寄存器比向量处理器更多
- 由于它们没有一种接近的标量处理器,
- 所以GPU有时会在运行时以硬件实现一些功能
- 而向量计算机通常是在编译时用软件来实现这些功能
- 与大多数向量体系结构不同,
- GPU还依靠单个多线程SIMD处理器中的多线程来隐藏存储器延迟(见2和3章)。
- 想为向量体系结构和GPU编写出高效代码,还需要考虑SIMD操作分组
多线程SIMD处理器指的是SIMD处理器
- 网格是在GPU上运行、由一组线程块构成的代码
- 表4-5:网格与向量化循环、线程块与循环体(已进行了条带挖掘,所以它是完整的计算循环)之间的相似
- 希望把两个向量乘在一起,每个向量8192
- 图4-8给出了这个示例与前两个GPU术语之间的关系
- 执行所有8192个元素乘法的GPU代码被称为网格(或向量化循环)
- 为了将它分解为更便于管理的大小,网格由线程块(或向量化循环体)组成,每个线程块最多512元素
- 一条SIMD指令次执行32个元素
- 向量有8192个元素,所以有16个线程块(16=8192÷512)。
- 网络和线程块是在GPU硬件中实现的编程抽象,帮助程序员组织自己的CUDA代码
- 线程块类似于一个向量长度为32的条带挖掘向量循环。
例子中每个线程块含16个SIMD线程,每个SIMD线程处理32个数 线程块调度程序把每个块调度给SIMD处理器,不管你有几个SIMD处理器,我有这个线程块调度程序那我分配起来就很灵活啊 虽然软件写起来是CUDA线程,但硬件干起来的处理对象是SIMD 指令线程,他是一个线程,只不过指令都是SIMD指令 所以你知道了,GPU由两种硬件调度程序:线程块调度程序和SIMD内部的SIMD线程调度程序 一条SIMD指令可以处理32个元素,但是只有16个SIMD车道哈哈哈。 每个SIMD线程有2048个32位寄存器 怪不得16x2048=32768呢 添加链接描述 添加链接描述




意思是每个处理器上最多16个线程吗??
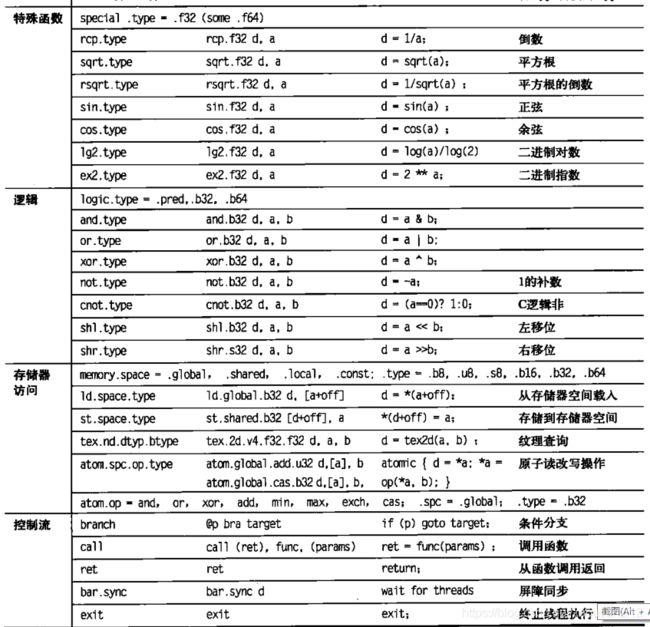
4.4.3 NVIDA GPU指令集体系结构
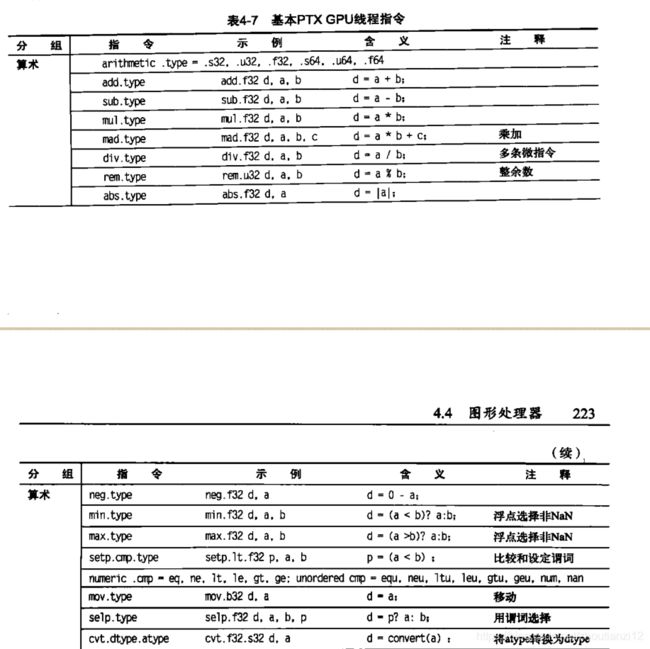

4.4.4 GPU中的条件分支
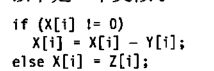

4.4.5 NVIDA GPU存储器结构
图4-12是NVIDIA GPU的存储器结构。
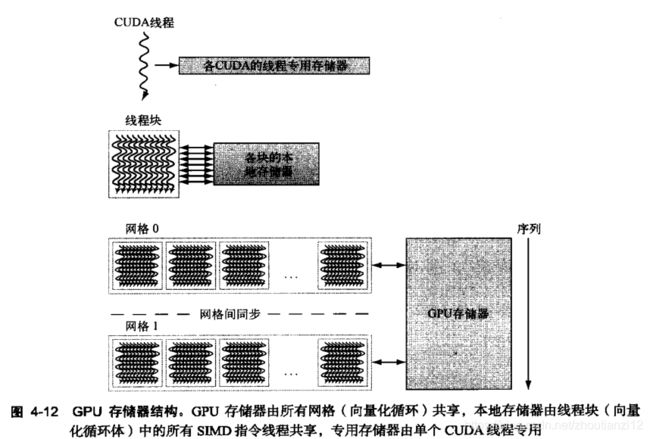
每个多线程SIMD处理器本地的片上存储器称为本地存储器。
整个GPU和所有线程块共享的片外DRAM称为GPU存储器。
主机的系统处理器可读或写GPU存储器。
GPU不依赖大型缓存来包含应用程序的整个工作集,
尽管隐藏存储器延迟是一种优选方法,但注意,最新的GPU和向量处理器都已经添加缓存。
为提高存储器带宽、降低开销,
参考链接