solr7的安装配置以及调试(增量导入,修改导入等)
关于solr的相对完整配置教程 本人在网络上搜罗许久,许多的博文没有比较全面的描述,今天在这里和大家分享一下solr的安装配置以及调试的文章,文章是网络多篇博文整理而来,文章最后有地址,若有侵权立即删除。
Solr是一个独立的企业级搜索应用服务器,官网地址:https://lucene.apache.org/solr/
从域名我们不难看出,solr是基于lucene的,同时属于apache旗下的组件,今天我们一起学习了解一下solr7.5的安装、使用和java基础调用。
Solr 教程要求
要遵循本教程,您将需要达到以下要求:
- 满足如下的系统要求:
- Apache Solr 在 Java 8 或更高的版本上运行。
- 建议始终使用 Java VM 的最新更新版本,因为错误可能会影响到 Solr,您可以在 http://wiki.apache.org/lucene-java/JavaBugs 上找到已知的 JVM 错误的概述。
- 对于所有 Java 版本,强烈建议不要使用实验性的 XX JVM 选项。
- CPU、磁盘和内存要求是基于在实现 Solr 时所做的许多选择 (文档大小、文档数量和检索到的名称数)。基准页面有一些与特定平台上的性能有关的信息。
为了获得最佳效果,请运行显示的浏览器和 Solr 服务器在同一台机器上,以便教程能够正确引导您的 Solr配置。
一、下载
进入官网下载页:http://www.apache.org/dyn/closer.lua/lucene/solr/7.5.0
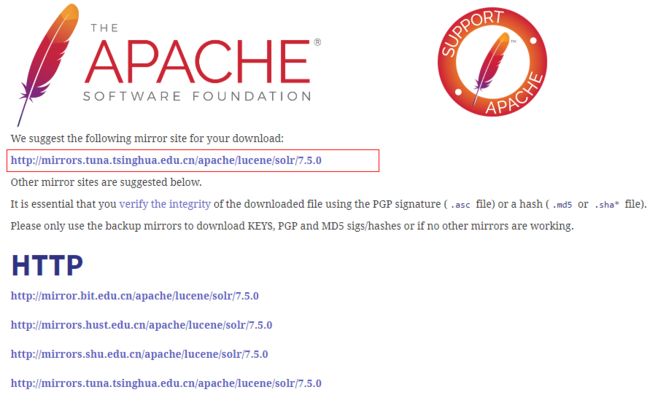
直接下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/7.5.0/
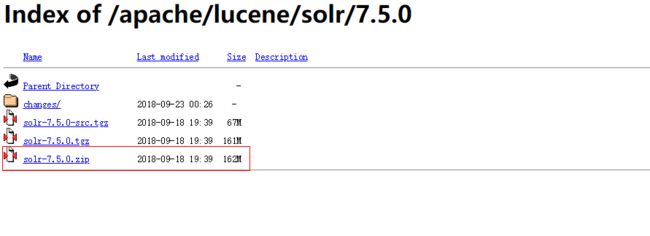
目前最新版本7.5,我们就以这个为安装实例。
下载之后,我们得到一个安装包solr-7.5.0.zip,本示例以windows为例。
二、安装
1.把solr-7.5.0.zip安装文件解压到指定目录
我们可以看到是这样一个目录结构:

bin:启动命令
dist:jar包
example:示例
server:solr的服务相关配置
7.5的solr是自带jetty容器的,我们都不需要tomcat,直接用自带的jetty即可。
当然如果你有更多定制化需求,也可以用tomcat做容器。
三、启动
解压了我们就可以直接通过/solr-7.5.0/bin 下的solr进行启动了。
在window下我一般是通过cmd来启动。
打开cmd,进入到对应的bin目录下,执行:
solr start当你看到如下提示,表示启动成功:
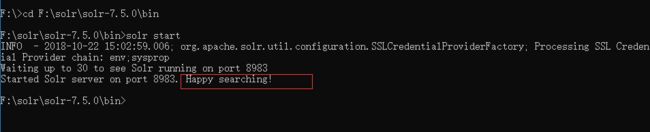
此时我们就可以通过http://127.0.0.1:8983/solr/#/ 访问solr的管理界面了。
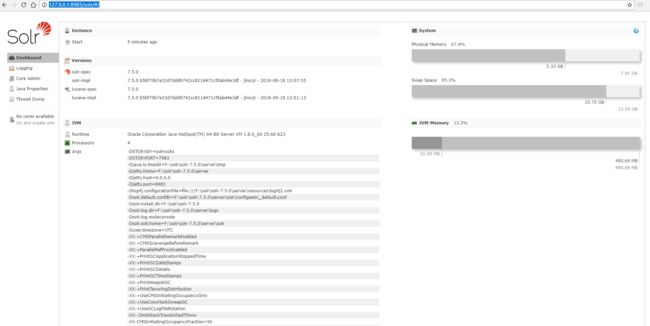
是不是觉得太简单了,是的没有比这更简单的了。
但是此时高兴还为时过早。
三、配置
配置主Core
初始化的sorl服务是没有core的,我们需要新建一个。
点击Core Admin,进入以下界面:

默认界面如下,定义你的core名称,点击Add core。
会报一个错误:
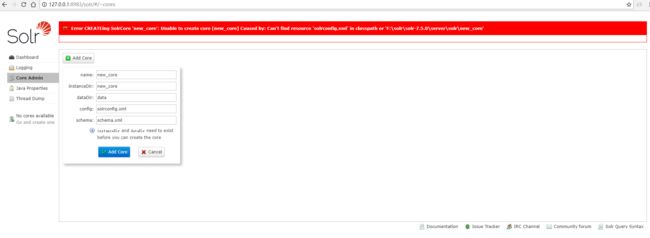
莫要惊慌,此时我们去安装目录(F:\solr\solr-7.5.0\server\solr)下,可以看到已经新建了一个core目录。
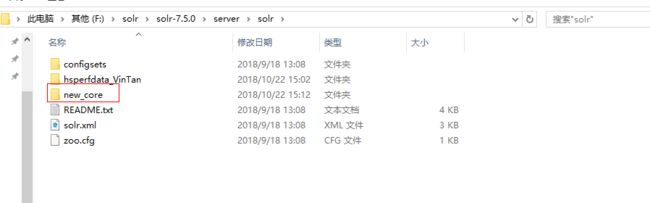
报错是因为需要的配置文件不存在,我们去拷贝过来即可。
进入F:\solr\solr-7.5.0\example\example-DIH\solr\db的conf文件夹。把conf文件夹copy到
F:\solr\solr-7.5.0\server\solr\new_core 目录下,然后再执行Add core。
然后等待1-2s,会进入以下界面:
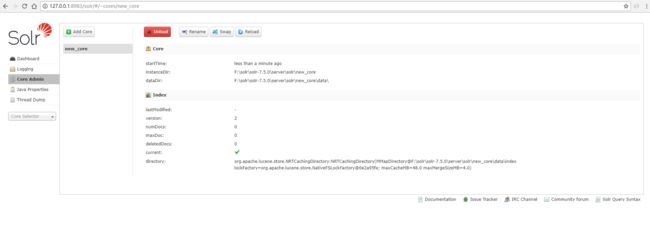
此时说明我们的core已经创建成功。
选择新建的core,我们就进入到solr的主要管理界面了。
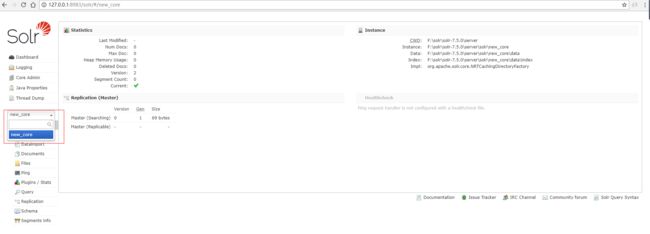
到此,我们已经成功的搭建好了solr的基本服务。
四、数据库配置
完成以上步骤,我们经历了一个solr服务的从0到有,但是实际上,我们大部分情况下是需要连接数据库来对数据进行索引,然后极大提升我们的查询效率。
如何通过solr连接数据库,把数据索引到solr服务中,我们接着说。
1.JAR包准备
1.1 准备mysql连接驱动包,mysql-connector-java-5.1.29.jar,直接maven私服下载或者从自己的项目中获取,这个使用率应该是特别高的。
2.1 找到solr-dataimporthandler-7.5.0.jar和solr-dataimporthandler-extras-7.5.0.jar 。这2个jar在solr安装目录下有,F:\solr\solr-7.5.0\dist
把这3个jar包复制到F:\solr\solr-7.5.0\server\solr-webapp\webapp\WEB-INF\lib 目录下,熟悉java的朋友其实看一眼就明白,这其实是一个标准的web项目目录。
2.配置文件准备
在conf目录下,我们可以看到很多配置文件如下:
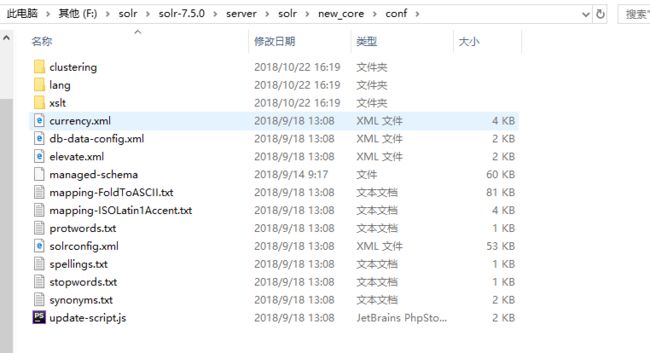
2.1 修改db-data-config.xml
初始化的配置文件如下,这是一个数据库连接池的配置文件,我们需要配置自己的数据库地址和查询sql。
以本地Mysql数据库为例,修改配置文件如下:
配置说明:
dataSource-->数据库连接,用户名密码配置
entity-->sql定义
field-->字段定义,column对应数据库字段,name对应solr的索引字段名
本地数据库如下:
CREATE TABLE `student` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`code` varchar(20) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;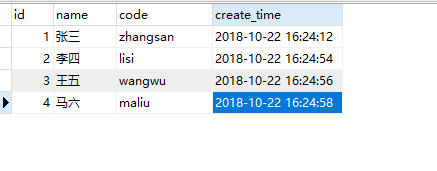
2.2 修改managed-schema
进入该配置文件,这个配置文件主要用于配置索引字段。我们在配置文件中增加field,要求一一对应。
注意:我们copy来的配置文件中有一些关键字已经配置了,如id,name,那就不需要重新配置field,只需要配置没有的。
如果你的表主键id不是叫id,那么你定义的field需要指定required="true",并把默认的id的required="true"属性去掉,
并把
说明:因为只是做个基础的搜索业务,没有精细该schema文件,精益求精的小伙伴可以把冗余字段都干掉试试。
到此,配置完成,接下来我们操作导入数据。
五、数据导入
以上配置完成后,需要重启solr服务。
打开cmd,进入到对应的bin目录下,执行:solr stop -p 8983
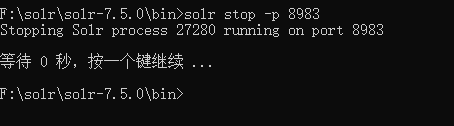
服务停止后,我们再执行启动命令:solr start
1.数据导入
启动成功后进入http://127.0.0.1:8983/solr/#/new_core/dataimport//dataimport
或者在主界面点击Dataimport
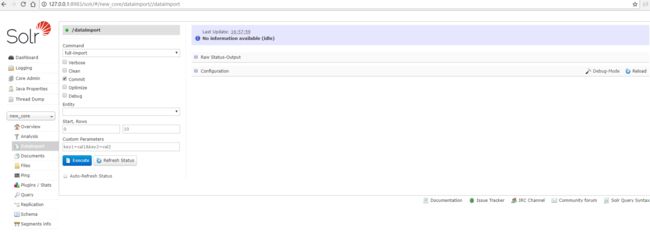
点击Entity,我们发现有我们配置的student,勾选中
最后勾选Auto-Refresh Status,点击Excute,
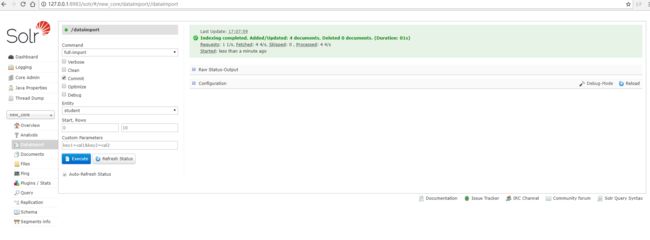
右边会显示执行结果,如图所示,导入了4条数据。
进入到Query菜单,执行查询,如图所示,结果如下:
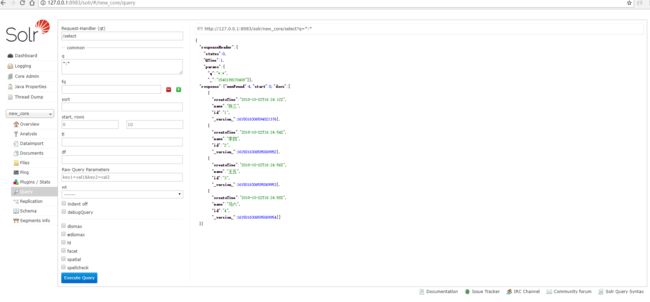
和我们数据库的数据是刚好对应的。
说明:solr中的索引字段名取决于你在managed-schema中如何配置定义。
另外,大家配置的时候注意,不需要进行索引或者存储的字段要配置成false,节省资源空间。
如创建时间,我们不需要进行查询索引,indexed配置成false即可。
2.数据清空
进入solr主页,进入Documents模块,如图所示,选择XML类型
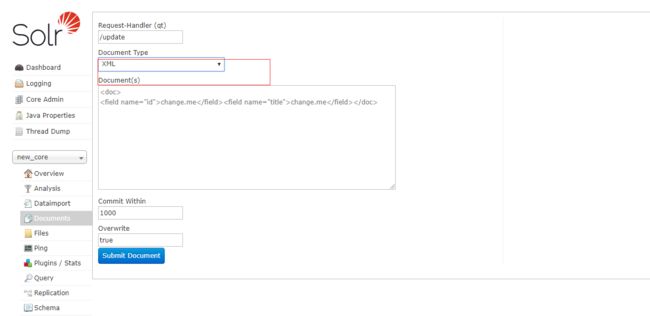
输入xml
*:* 点击Submit Document,结果如下:

此时再去查询,就看到数据都已经清空。
六、增量更新索引
大家发现没,solr是"一步一个坑",弄完这个,你又得弄另外一个。
我们有了数据导入,那数据库变化了怎么同步数据?难道每次手动点一点?
答案当然是NO,所以接下来,我们一起了解下如何配置增量更新索引。
增量更新索引,顾名思义就是在原有的数据基础上进行索引更新,不会对已有的数据再进行一次索引。
1.准备JAR包
这个jar包挺坑的,搜罗了很久,最终也是花积分下载的,本着"天下没有免费的JAR包"的原则,所以大家如果需要该jar包,
请点击下载:
下载了jar包后,把jar包复制放到F:\solr\solr-7.5.0\server\solr-webapp\webapp\WEB-INF\lib 目录下
2.修改web.xml配置
F:\solr\solr-7.5.0\server\solr-webapp\webapp\WEB-INF
打开web.xml文件,增加监听器配置
org.apache.solr.handler.dataimport.scheduler.ApplicationListener
这个监听器源码就是来自上面的jar包中,我确认过了。
3.增加dataimport.properties配置
增加增量导入配置文件,注意,目录!目录!目录!
这个文件在F:\solr\solr-7.5.0\server\solr\new_core\conf 有一个,但是,我们不是配置到这里!敲黑板,划重点!
我们需要在F:\solr\solr-7.5.0\server\solr 目录下,新建一个conf文件夹,注意啦,这个文件夹是我们手动新建的,如果没操作这一步,你就是操作不当。
然后在conf目录下,新建dataimport.properties 文件。
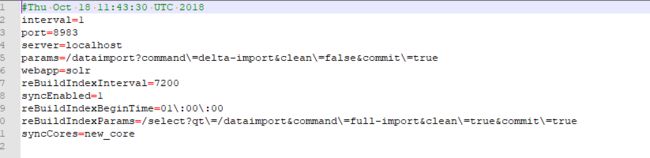
文件内容如下(以下文件来源于网络):
#################################################
# #
# dataimport scheduler properties #
# #
#################################################
# to sync or not to sync
# 1 - active; anything else - inactive
syncEnabled=1
# which cores to schedule
# in a multi-core environment you can decide which cores you want syncronized
# leave empty or comment it out if using single-core deployment
# 修改成你所使用的core
syncCores=my_core
# solr server name or IP address
# [defaults to localhost if empty]
server=localhost
# solr server port
# [defaults to 80 if empty]
# 安装solr的端口
port=8983
# application name/context
# [defaults to current ServletContextListener's context (app) name]
webapp=solr
# URL params [mandatory]
# remainder of URL
# 这里改成下面的形式,solr同步数据时请求的链接
params=/dataimport?command=delta-import&clean=false&commit=true
# schedule interval
# number of minutes between two runs
# [defaults to 30 if empty]
#这里是设置定时任务的,单位是分钟,也就是多长时间你检测一次数据同步,根据项目需求修改
# 开始测试的时候为了方便看到效果,时间可以设置短一点
interval=1
# 重做索引的时间间隔,单位分钟,默认7200,即5天;
# 为空,为0,或者注释掉:表示永不重做索引
reBuildIndexInterval=7200
# 重做索引的参数
reBuildIndexParams=/select?qt=/dataimport&command=full-import&clean=true&commit=true
# 重做索引时间间隔的计时开始时间,第一次真正执行的时间=reBuildIndexBeginTime+reBuildIndexInterval*60*1000;
# 两种格式:2012-04-11 01:00:00 或者 01:00:00,后一种会自动补全日期部分为服务启动时的日期
reBuildIndexBeginTime=01:00:00自己修改一下配置,改成自己的。
这个文件说的挺详细的,建议存档理解。因为运行一次之后,这个文件会变成酱紫了,but,我们并不需要care了
4.修改db-data-config.xml配置
总算来到"终极BOSS关",我们只需要再配置2个脚本,就KO了,再坚持一下吧。
直接上配置代码吧,简单粗暴一点。
说明:
主要增加了deltaImportQuery和deltaQuery 2个属性,其实这个就是作为增量时的操作sql,solr默认读取这个key值的sql语句。
${dataimporter.delta.id} 这个东东,我没找到具体的定义在哪,但是如果你的主键id配置的不叫id,如叫studentId,那么,这个取变量就应该写成${dataimporter.delta.studentId}
${dataimporter.last_index_time} 固定写法,更新的判断条件,上一次的修改时间需要大于上一次索引的更新时间。
比较重要的两点就是:
①`create_time`是我在数据库中创建的一个标记字段,用来判断是否需要增量导入;大家需要在数据库中自己创建一个这样的一个字段,否则增量导入是无效的。数据库中必须要有这样的一个可以与${dataimporter.last_index_time} 比较的字段。
②两条增量导入的sql语句需要小心设计,稍有不细心就会配置出错。导致 solr主页的loging中报错。
这个参数会自动更新在F:\solr\solr-7.5.0\server\solr\new_core\conf 下的dataimport.properties文件中
这个文件长这样,了解一下:
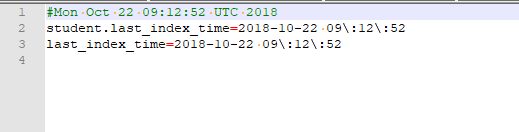
(没错,和前面配置的那个是同名文件,我也不太理解为啥不能共用这一个)
5.重启验证
嗷嗷嗷,总算配置完成,那么赶紧重启一波,验证一把呗。
验证步骤1:重启完服务后,观察solr日志
验证步骤2:去数据库中新建或者修改数据,静静等待你配置的增量时间
数据库修改数据:

等待.........
验证步骤3:查询结果,观察数据是否已经同步
当你看到出现出现如下日志:(日志目录-->F:\solr\solr-7.5.0\server\logs\solr.log)
2018-10-22 10:05:18.234 INFO (Thread-17) [ ] o.a.s.h.d.DataImporter Starting Delta Import
2018-10-22 10:05:18.235 INFO (Timer-0) [ ] o.a.s.h.d.s.BaseTimerTask [new_core] Response message OK
2018-10-22 10:05:18.235 INFO (Timer-0) [ ] o.a.s.h.d.s.BaseTimerTask [new_core] Response code 200
2018-10-22 10:05:18.235 INFO (Timer-0) [ ] o.a.s.h.d.s.BaseTimerTask [new_core] Disconnected from server localhost
2018-10-22 10:05:18.236 INFO (Timer-0) [ ] o.a.s.h.d.s.BaseTimerTask [new_core] Process ended at ................ 22.10.2018 10:05:18 235 说明增量同步已经执行...
查询solr:
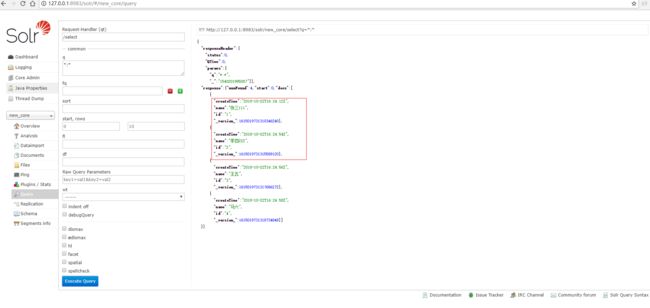
至此,增量同步配置完成!
拓展:每一次修改之后也可以进行自动导入,但是一定要记得修改时间标记字段。大家还可以可以自己在配置文件中国修改刷新检查数据库数据的频次来减小系统开销。
七、分词技术
分词技术说难不难,说简单吧,感觉有时候又达不到你的需求。
分词我研究的很肤浅,包括权重这块,我都没有太深入,采取的基本配置。
分词,我用的是IK分词器,这个jar包很久没人维护了,索性,在solr7中也是适用的。
1.下载IK分词器jar包
这里也方便大家下载,在我的公号(tanjava)中回复"分词"即可获得分词jar包的百度网盘下载链接。
下载解压后,把ik-analyzer-solr5-5.x.jar 放到F:\solr\solr-7.5.0\server\solr-webapp\webapp\WEB-INF\lib 目录下。
2.修改managed-schema文件
修改F:\solr\solr-7.5.0\server\solr\new_core\conf 目录下的managed-schema 文件。
增加分词器的fieldType定义:
name="text_ik",分词器名称,在后面的filed定义的时候,可以直接引用。
如,type定义为"text_ik",则代表该字段将进行分词索引
3.查看
进入solr主页,进入Analysis,输入一段汉字,选择text_ik,点击分析可以看到如下结果:
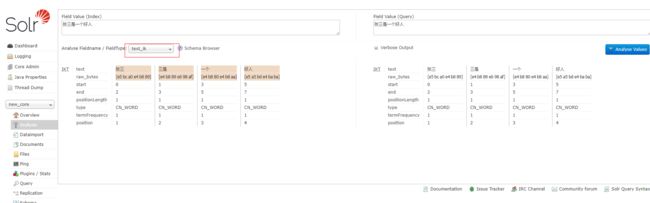
如上,说明分词成功。
八、小结
至此,solr服务就全部搭建完成了。
简单回顾一下。
下载安装文件->配置solr->启动。
其实关键在于配置环节,其实个人觉得配置这块如果能界面化,相信solr更容易上手了。
九、Java调用接口
solr服务搭建完成,那么如何提供出接口请求访问?
solr有提供java的api,说透了也很简单了。
1.引入pom依赖
org.apache.solr
solr-solrj
7.5.0
2.写一个solr的工具类
以下是核心方法,从solr查询的数据都会封装在SolrDocumentList返回。
public void solrQuery() throws IOException, SolrServerException {
String solrUrl = "http://127.0.0.1:8983/solr/new_core";
HttpSolrClient solrClient = new HttpSolrClient.Builder(solrUrl).build();
// 创建搜索对象
SolrQuery query = new SolrQuery();
// 设置搜索条件
query.set("q","name:张三是好人");
// 分页参数
query.setStart(0);
// 设置每页显示多少条
query.setRows(10);
//发起搜索请求
QueryResponse response = solrClient.query(query);
// 查询结果
SolrDocumentList docs = response.getResults();
// 查询结果总数
long count= docs.getNumFound();
System.out.println("总条数为"+count+"条");
for (SolrDocument doc : docs) {
System.out.println("id:"+ doc.get("id") + ",name:"+ doc.get("name") + ",uuid:"+ doc.get("uuid"));
}
solrClient.close();
}
OK,到此,我们的solr从安装,到配置以及最终的到调用,都呈现出来了。
十、相关文章推荐:
本文借鉴多数文章,大体参照:https://my.oschina.net/gmupload/blog/2250836
其他文章推荐:https://www.cnblogs.com/Zhong-Xin/p/5500599.html