【深入理解Hadoop原理】Hadoop 读写文件源码分析
Hadoop 读文件源码分析

1.客户端调用FileSystem对象读取希望读取的文件,FileSystem对象是分布式文件系统的一个实例
FSDataInputStream in = fileSystem.open(file.getPath());
FileSystem对象有方法:
/**
* Opens an FSDataInputStream at the indicated Path.
* @param f the file to open
*/
public FSDataInputStream open(Path f) throws IOException {
return open(f, getConf().getInt("io.file.buffer.size", 4096));
}
DistributedFileSystem对象有:
@Override
public FSDataInputStream open(Path f, final int bufferSize)
throws IOException {
statistics.incrementReadOps(1);
Path absF = fixRelativePart(f);
return new FileSystemLinkResolver() {
@Override
public FSDataInputStream doCall(final Path p)
throws IOException, UnresolvedLinkException {
final DFSInputStream dfsis =
dfs.open(getPathName(p), bufferSize, verifyChecksum);
return dfs.createWrappedInputStream(dfsis);
}
@Override
public FSDataInputStream next(final FileSystem fs, final Path p)
throws IOException {
return fs.open(p, bufferSize);
}
}.resolve(this, absF);
}
注意其中doCall方法:
调用了DFSClient对象的open方法
dfs.open(getPathName(p), bufferSize, verifyChecksum);
DFSClient 的open是去获取block所在的DataNode
看源码:
/**
* Create an input stream that obtains a nodelist from the
* namenode, and then reads from all the right places. Creates
* inner subclass of InputStream that does the right out-of-band
* work.
*/
public DFSInputStream open(String src, int buffersize, boolean verifyChecksum)
throws IOException, UnresolvedLinkException {
checkOpen();
// Get block info from namenode
TraceScope scope = getPathTraceScope("newDFSInputStream", src);
try {
return new DFSInputStream(this, src, verifyChecksum);
} finally {
scope.close();
}
}
/**
* Create an input stream that obtains a nodelist from the
* namenode, and then reads from all the right places. Creates
* inner subclass of InputStream that does the right out-of-band
* work.
*/
public DFSInputStream open(String src, int buffersize, boolean verifyChecksum)
throws IOException, UnresolvedLinkException {
checkOpen();
// Get block info from namenode
TraceScope scope = getPathTraceScope("newDFSInputStream", src);
try {
return new DFSInputStream(this, src, verifyChecksum);
} finally {
scope.close();
}
}
DFSInputStream 根据读取
DFSInputStream(DFSClient dfsClient, String src, boolean verifyChecksum
) throws IOException, UnresolvedLinkException {
this.dfsClient = dfsClient;
this.verifyChecksum = verifyChecksum;
this.src = src;
synchronized (infoLock) {
this.cachingStrategy = dfsClient.getDefaultReadCachingStrategy();
}
openInfo();
}
再次 调用DFSClient创建inputStream
/**
* Wraps the stream in a CryptoInputStream if the underlying file is
* encrypted.
*/
public HdfsDataInputStream createWrappedInputStream(DFSInputStream dfsis)
throws IOException {
final FileEncryptionInfo feInfo = dfsis.getFileEncryptionInfo();
if (feInfo != null) {
// File is encrypted, wrap the stream in a crypto stream.
// Currently only one version, so no special logic based on the version #
getCryptoProtocolVersion(feInfo);
final CryptoCodec codec = getCryptoCodec(conf, feInfo);
final KeyVersion decrypted = decryptEncryptedDataEncryptionKey(feInfo);
final CryptoInputStream cryptoIn =
new CryptoInputStream(dfsis, codec, decrypted.getMaterial(),
feInfo.getIV());
return new HdfsDataInputStream(cryptoIn);
} else {
// No FileEncryptionInfo so no encryption.
return new HdfsDataInputStream(dfsis);
}
}
最终返回一个读取block所在的DataNode流
FSDataInputStream
2. 获得了FsDataInputStream 流对象, 客户端用这个流对象 调用 read方法 可以读取DataNode中的数据
栗子:
in = fileSystem.open(file.getPath());
br = new BufferedReader(new InputStreamReader(in));
String line = null;
while (null != (line = br.readLine())) {
if (!StringUtil.isEmpty(line)) {
data.add(line);
}
}
查看BufferedReader源码 的readLine方法
/**
* Reads a line of text. A line is considered to be terminated by any one
* of a line feed ('\n'), a carriage return ('\r'), or a carriage return
* followed immediately by a linefeed.
*
* @return A String containing the contents of the line, not including
* any line-termination characters, or null if the end of the
* stream has been reached
*
* @exception IOException If an I/O error occurs
*
* @see java.nio.file.Files#readAllLines
*/
public String readLine() throws IOException {
return readLine(false);
}
再看BufferedReader 的方法
/**
* Reads a line of text. A line is considered to be terminated by any one
* of a line feed ('\n'), a carriage return ('\r'), or a carriage return
* followed immediately by a linefeed.
*
* @param ignoreLF If true, the next '\n' will be skipped
*
* @return A String containing the contents of the line, not including
* any line-termination characters, or null if the end of the
* stream has been reached
*
* @see java.io.LineNumberReader#readLine()
*
* @exception IOException If an I/O error occurs
*/
String readLine(boolean ignoreLF) throws IOException {
StringBuffer s = null;
int startChar;
synchronized (lock) {
ensureOpen();
boolean omitLF = ignoreLF || skipLF;
bufferLoop:
for (;;) {
if (nextChar >= nChars)
fill();
if (nextChar >= nChars) { /* EOF */
if (s != null && s.length() > 0)
return s.toString();
else
return null;
}
boolean eol = false;
char c = 0;
int i;
/* Skip a leftover '\n', if necessary */
if (omitLF && (cb[nextChar] == '\n'))
nextChar++;
skipLF = false;
omitLF = false;
charLoop:
for (i = nextChar; i < nChars; i++) {
c = cb[i];
if ((c == '\n') || (c == '\r')) {
eol = true;
break charLoop;
}
}
startChar = nextChar;
nextChar = i;
if (eol) {
String str;
if (s == null) {
str = new String(cb, startChar, i - startChar);
} else {
s.append(cb, startChar, i - startChar);
str = s.toString();
}
nextChar++;
if (c == '\r') {
skipLF = true;
}
return str;
}
if (s == null)
s = new StringBuffer(defaultExpectedLineLength);
s.append(cb, startChar, i - startChar);
}
}
}
再看写HDFS源码:
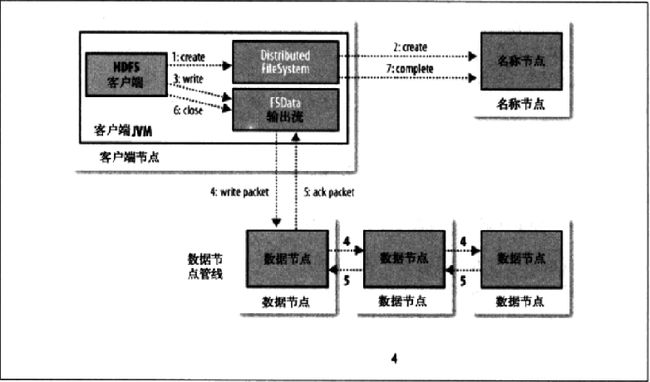
写文件栗子:
FileSystem fs = null;
FSDataOutputStream output = null;
try {
fs = path.getFileSystem(conf);
output = fs.create(path); // 创建文件
for(String line : contents) { // 写入数据
output.write(line.getBytes("UTF-8"));
output.flush();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
output.close();
} catch (IOException e) {
e.printStackTrace();
}
}
1. 客户端使用DistributedFileSystem端的create方法创建一个文件输出流
@Override
public FSDataOutputStream create(final Path f, final FsPermission permission,
final EnumSet cflags, final int bufferSize,
final short replication, final long blockSize, final Progressable progress,
final ChecksumOpt checksumOpt) throws IOException {
statistics.incrementWriteOps(1);
Path absF = fixRelativePart(f);
return new FileSystemLinkResolver() {
@Override
public FSDataOutputStream doCall(final Path p)
throws IOException, UnresolvedLinkException {
final DFSOutputStream dfsos = dfs.create(getPathName(p), permission,
cflags, replication, blockSize, progress, bufferSize,
checksumOpt);
return dfs.createWrappedOutputStream(dfsos, statistics);
}
@Override
public FSDataOutputStream next(final FileSystem fs, final Path p)
throws IOException {
return fs.create(p, permission, cflags, bufferSize,
replication, blockSize, progress, checksumOpt);
}
}.resolve(this, absF);
}
然后继续调用DFSClient 的
createWrappedOutputStream
/**
* Wraps the stream in a CryptoOutputStream if the underlying file is
* encrypted.
*/
public HdfsDataOutputStream createWrappedOutputStream(DFSOutputStream dfsos,
FileSystem.Statistics statistics, long startPos) throws IOException {
final FileEncryptionInfo feInfo = dfsos.getFileEncryptionInfo();
if (feInfo != null) {
// File is encrypted, wrap the stream in a crypto stream.
// Currently only one version, so no special logic based on the version #
getCryptoProtocolVersion(feInfo);
final CryptoCodec codec = getCryptoCodec(conf, feInfo);
KeyVersion decrypted = decryptEncryptedDataEncryptionKey(feInfo);
final CryptoOutputStream cryptoOut =
new CryptoOutputStream(dfsos, codec,
decrypted.getMaterial(), feInfo.getIV(), startPos);
return new HdfsDataOutputStream(cryptoOut, statistics, startPos);
} else {
// No FileEncryptionInfo present so no encryption.
return new HdfsDataOutputStream(dfsos, statistics, startPos);
}
}DistributedFileSystem通过远程RPC调用NameNode,HDFS NameSpace创建一个Entry,该条目下没任何的Block
最后返回一个 可以对DataNode进行写操作的流
FSDataOutputStream
2. 通过FSDataOutputStream对象,对DataNode进行写数据 write方法
public void write(int b) throws IOException {
out.write(b);
position++;
if (statistics != null) {
statistics.incrementBytesWritten(1);
}
}
3. 文件写完之后关闭FSDataOutputStream流
public void close() throws IOException {
// ensure close works even if a null reference was passed in
if (out != null) {
out.close();
}
}