十亿级表和亿级表join不动的解决方案
在开发中遇到问题
表t_dmp_idfa_bundle_country_array_middle_tbl (后面简称表1)一个分区的数据量是40亿
临时表t_ifa_tbl (后面简称表2)数据量3亿条数据
表1 left join 表2 ,直接就挂掉了
错误一般是
类似于如下的错误
BlockManagerMasterEndpoint: No more replicas available for
查看博客 博客上说是内存不够
集群的配置如下:
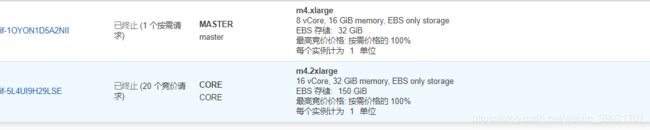
自认为集群还是配置挺给力的
现在遇到的问题就两种解决办法
1.提高集群配置
优点:立竿见影,速度快,不用慢慢调优,也不用想解决方案
缺点:集群的配置高了,因为公司比较穷,用的spot模式(竞价模式),高端机器比较稀 缺,很可能在跑任务途中,集群被回收导致任务失败
2.方案2.双表hash 再join,join完以后在union
具体原理如图:
优化前的局部代码如下:
//注册临时表t_ifa_tbl数据量3亿
ss.sql("set spark.sql.shuffle.partitions=3800")
val sql =
s"""
|SELECT ifa
|from
|dmp.t_dmp_idfa_bundle_country_array_middle_tbl a
|left semi join
|(
|select ifa from dmp.t_dmp_idfa_bundle_every_tbl
|UNION
|select ifa from dmp.t_dmp_idfa_country_every_tbl
|) t on a.day= '$OneDayAgo' and a.ifa = t.ifa
""".stripMargin
val ifaResult = ss.sql(sql).persist(StorageLevel.MEMORY_AND_DISK_SER)
println("ifaResult.count::::::"+ifaResult.count())
// ifaResult.createOrReplaceGlobalTempView("t_ifa_tbl")
ifaResult.createOrReplaceTempView("t_ifa_tbl")
//这里是40亿表dmp.t_dmp_idfa_bundle_country_array_middle_tbl
//和临时表t_ifa_tbl join
var finalDf = ss.sql("select ifa,bundles,countrys,updateday from dmp.t_dmp_idfa_bundle_country_array_middle_tbl where 1=0")
// for(routeCode <- 0 to 1){
val unActiveDf= ss.sql(
s"""
|select
|a.ifa as ifa, bundles,countrys,updateday
|from
|dmp.t_dmp_idfa_bundle_country_array_middle_tbl a
|left join
|t_ifa_tbl b
|on day='$OneDayAgo' and 0=getRouteCode(a.ifa) 0=getRouteCode(b.ifa) and a.ifa=b.ifa and b.ifa is null
""".stripMargin)
finalDf= finalDf.union(unActiveDf)//.union(unActiveDf)
直接join动
优化后的代码
//注册临时表
ss.sql("set spark.sql.shuffle.partitions=3800")
val sql =
s"""
|SELECT ifa
|from
|dmp.t_dmp_idfa_bundle_country_array_middle_tbl a
|left semi join
|(
|select ifa from dmp.t_dmp_idfa_bundle_every_tbl
|UNION
|select ifa from dmp.t_dmp_idfa_country_every_tbl
|) t on a.day= '$OneDayAgo' and a.ifa = t.ifa
""".stripMargin
val ifaResult = ss.sql(sql).persist(StorageLevel.MEMORY_AND_DISK_SER)
println("ifaResult.count::::::"+ifaResult.count())
// ifaResult.createOrReplaceGlobalTempView("t_ifa_tbl")
ifaResult.createOrReplaceTempView("t_ifa_tbl")
//上面的没有优化,下面的代码是优化过得
var finalDf = ss.sql("select ifa,bundles,countrys,updateday from dmp.t_dmp_idfa_bundle_country_array_middle_tbl where 1=0")
/*---------begin--------*/
ss.sql("set spark.sql.shuffle.partitions=3800")
ss.sql("set spark.sql.hive.caseSensitiveInferenceMode=NEVER_INFER")
// val routeCode = 0
for(routeCode <- 0 to 7){
val hashSql =s"""
select
ifa, bundles,countrys,updateday
from
dmp.t_dmp_idfa_bundle_country_array_middle_tbl
where
day='$OneDayAgo'
and
$routeCode=getRouteCode(ifa)
"""
println(hashSql)
val hashTblDf =ss.sql(hashSql)
println(s"start write t_dmp_idfa_bundle_country_array_tbl_$routeCode tbl")
val hashTblPath = s"s3://xiandmpdata.yeahtargeter.com/hive_dataware/dmp/t_dmp_idfa_bundle_country_array_tbl_$routeCode"
FileSystem.get(new URI("s3://xiandmpdata.yeahtargeter.com"), ss.sparkContext.hadoopConfiguration).delete(new Path(hashTblPath), true)
hashTblDf.write.format("orc").save(hashTblPath)
println(s"write t_dmp_idfa_bundle_country_array_tbl_$routeCode success")
//今日不活跃uv
val unActiveDf= ss.sql(
s"""
|select
|a.ifa as ifa, bundles,countrys,updateday
|from
|dmp.t_dmp_idfa_bundle_country_array_tbl_0 a
|left join
|t_ifa_tbl b
|on $routeCode=getRouteCode(b.ifa) and a.ifa=b.ifa and b.ifa is null
""".stripMargin).persist(StorageLevel.MEMORY_AND_DISK_SER)
finalDf= finalDf.union(unActiveDf)
unActiveDf.unpersist(true)
}
/*---------end---------*/
注册udf的代码如下:
//为了把40亿的数据打散join
ss.udf.register("getRouteCode",(routeKey:String) => {
val routeCode: Int =routeKey match {
case null|""=> 99
case _=> {
(routeKey.hashCode() & Integer.MAX_VALUE) % 8
}
}
routeCode
})
致此优化完成,join可以顺利完成!
唯一的问题是数据量有点问题,正在排查逻辑