【Python爬虫】-从入门到入门-个人技术经验汇总-【爬虫和数据】
文章目录
- 一、为什么要做爬虫,Python的优势在何处?
-
- (一)首先请问:都说现在都是“大数据时代”,那么数据从何而来?
- 二、爬虫是什么?
-
- (一)爬虫定义(面试点)
- (二)爬虫分类
-
- 1、通用爬虫
-
- 1.1 什么是搜索引擎?
- 1.2 通用搜索引擎(Search Engine)工作原理:
- 1.3 通用性搜索引擎存在着一定的局限性(面试):
- 2、聚焦爬虫
- (三)爬虫工程师的进阶之路
- 三、Request简介-让HTTP服务人类
-
- (一)requests库简介
- (二)安装方式
- 四、Requests模块 get请求
-
- (一)网络请求
- (二)使用 requests 发送 get 请求
-
- 1、浏览器请求http过程(面试)
- 2、请求失败分析
- (三)response 对象的属性
-
- 1、字符串响应内容
- 2、二进制响应内容
- 3、json 响应内容
- 4、响应状态码
- 5、响应头
- 6、页面内容乱码问题(面试)
- (四)案例 1:爬取百度产品网页.py
- (五)案例 2:爬取新浪新闻.py
- (六)案例 3:批量爬取百度贴吧.py
- (七)案例 4:爬取百度
- 五、Request模块 post请求
-
- (一)最基本的Post请求使用方法
- (二)案例 5:重写百度翻译.py
- 六、项目总结

一、为什么要做爬虫,Python的优势在何处?
1)网站后端程序员:使用它单间网站,后台服务比较容易维护。如:Gmail、Youtube、知乎、豆瓣
2)自动化运维:自动化处理大量的运维任务
3)数据分析师:快速开发快速验证,分析数据得到结果
4)游戏开发者:一般是作为游戏脚本内嵌在游戏中
5)自动化测试:编写为简单的实现脚本,运用在Selenium/lr中,实现自动化。
6)网站开发:借助django,flask框架自己搭建网站
7)爬虫获取或处理大量信息:批量下载美剧、运行投资策略、爬合适房源、系统管理员的脚本任务等
8)在包装其他语言程序:Python又叫胶水语言,它可以用混合编译的方式使用c/c++/java等语言的库。“树莓派”作为微型电脑,使用python为主要开发语言。
作者:梦捷者
链接:https://www.jianshu.com/p/93f2840c2449
(一)首先请问:都说现在都是“大数据时代”,那么数据从何而来?

(1)企业生产的用户数据
百度指数:http://index.baidu.com/
阿里指数:http://alizs.taobao.com/
新浪微博指数:http://data.weibo.com/index
(2)数据平台购买数据:
数据堂:https://www.datatang.com/
国云数据市场:http://www.moojnn.com/data-market/
贵阳大数据交易所:http://trade.gbdex.com/trade.web/index.jsp
(3)政府/机构公开的数据:
中华人民共和国国家统计局数据:http://data.stats.gov.cn/index.html
世界银行公开数据:http://data.worldbank.org.cn/
联合国数据:http://data.un.org/
纳斯达克:http://www.nasdaq.com/zh
(4)数据管理咨询公司:
麦肯锡:http://www.mckinsey.com.cn/
埃森哲:http://www.accenture.com/cn-zh/
艾瑞咨询:http://www.iresearch.com.cn/
以上为数据来源,皆为商业化,或者一种实时数据,公开数据
一个简单的例子:
比如,小王新建一个公司,关于火锅餐饮,如果需要此数据,上述四种方式,未必有
那么?小王想要在该A地,发展自己的店,不知道当地的人喜欢什么菜品,什么口味?
那该如何办呢?数据公司无法提供参考?
如果需要的数据市场上没有,或者不愿意购买,那么可以选择招/做一名爬虫工程师, 自己动手丰衣足食。
因此爬虫工程师因此而生
二、爬虫是什么?
(一)爬虫定义(面试点)
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
简单地说:就是用事先写好的程序去抓取网络上所需的数据,这样的程序就叫网络爬虫。
编写网络爬虫的程序员叫做爬虫工程师。
通俗点:模拟浏览器获取数据
在这里插入代码片
(二)爬虫分类
根据使用场景,网络爬虫可分为通用爬虫和聚焦爬虫两种。
1、通用爬虫
通用网络爬虫是捜索引擎抓取系统(Baidu、Google、Yahoo 等)的重要组成部分。主要目 的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索 引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优 劣直接影响着搜索引擎的效果。
通用网络爬虫工作流程图:

通用网络爬虫工作流程图:

1.1 什么是搜索引擎?
搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程 序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相 关的信息展示给用户的系统。
1.2 通用搜索引擎(Search Engine)工作原理:
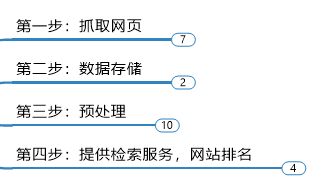
第一步:抓取网页 ,
搜索引擎网络爬虫的基本工作流程如下:
首先选取一部分的种子 URL,将这些 URL 放入待抓取 URL 队列; 取出待抓取 URL,解析 DNS 得到主机的 IP,并将 URL 对应的网页下载下来,存储进已下 载网页库中,并且将这些 URL 放进已抓取 URL 队列。
分析已抓取 URL 队列中的 URL,分析其中的其他 URL,并且将 URL 放入待抓取 URL 队列,从而进入下一个循环…
搜索引擎如何获取一个新网站的 URL:
1.新网站向搜索引擎主动提交网址:(如 http://zhanzhang.baidu.com/linksubmit/url)
2.在其他网站上设置新网站外链(尽可能处于搜索引擎爬虫爬取范围)
3.搜索引擎和 DNS 解析服务商(如 DNSPod 等)合作,新网站域名将被迅速抓取。但是搜索引擎系统的爬行是被输入了一定的规则的,它需要遵从一些命令或文件的内 容,如标注为 nofollow 的链接,或者是 Robots 协议。
第二步:数据存储
搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库。其中的页面数据与用户浏览器得到的 HTML 是完全一样的。(其实就是静态页面.html)
搜索引擎爬虫在抓取页面时,也做一定的重复内容检测,一旦遇到访问权重很低的网站 上有大量抄袭、采集或者复制的内容,很可能就不再爬行。
第三步:预处理
搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理。
提取文字
中文分词
消除噪音(比如版权声明文字、导航条、广告等……)
索引处理
链接关系计算
特殊文件处理
等等。。。。一些处理方法
除了 HTML 文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件 类型。
但搜索引擎还不能处理图片、视频、Flash 这类非文字内容,也不能执行脚本和程序。
第四步:提供检索服务,网站排名
搜索引擎在对信息进行组织和处理后,为用户提供关键字检索服务,将用户检索相关的 信息展示给用户。
同时会根据页面的 PageRank 值(链接的访问量排名)来进行网站排名,这样 Rank 值高的 网站在搜索结果中会排名较前,当然也可以直接使用 Money 购买搜索引擎网站排名,简单 粗暴。
1.3 通用性搜索引擎存在着一定的局限性(面试):
- 通用搜索引擎所返回的结果都是网页,而大多情况下,网页里 90%的内容对用户来说都是无用的。
- 不同领域、不同背景的用户往往具有不同的检索目的和需求,搜索引擎无法提供针对具体某个用户的搜索结果。
- 万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体 等不同数据大量出现,通用搜索引擎对这些文件无能为力,不能很好地发现和获取。
- 通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询,无 法准确理解用户的具体需求。
- 针对这些情况,聚焦爬虫技术得以广泛使用。
2、聚焦爬虫
聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于:
聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的 网页信息。
(三)爬虫工程师的进阶之路

初级爬虫工程师:
1、web 前端的知识:HTML、CSS、JavaScript、 DOM、 DHTML 、Ajax、jQuery、 json 等;
2、正则表达式,能提取正常一般网页中想要的信息,比如某些特殊的文字、链接信息、 知道什么是懒惰,什么是贪婪型的正则;
3、会使用 XPath 等获取一些 DOM 结构中的节点信息;
4、知道什么是深度优先和广度优先的抓取算法及实践中的使用规则;
5、能分析简单网站的结构, 会使用 urllib 或 requests 库进行简单的数据抓取。
中级爬虫工程师:
1、了解什么是 HASH,会简单地使用 MD5,SHA1 等算法对数据进行 HASH 一遍存储
2、熟悉 HTTP 和 HTTPS 协议的基础知识,了解 GET 和 POST 方法,了解 HTTP 头中 的信息,包括返回状态码、编码、user-agent、cookie 和 session 等。
3、能设置 user-agent 进行数据爬取,设置代理等。
4、知道什么是 Request,什么是 response,会使用 Fiddler 等工具抓取及分析简单地网 络数据包;对于动态爬虫,要学会分析 ajax 请求,模拟制造 post 数据包请求,抓取客户端 session 等信息,对于一些简单的网站,能够通过模拟数据包进行自动登录。
5、对于一些难搞定的网站学会使用 phantomjs+selenium 抓取一些动态网页信息
6、并发下载,通过并行下载加速数据爬取;多线程的使用。
高级爬虫工程师:
1、能进行网页的验证码破解
2、能破解网站的数据加密。
3、会使用常用的数据库进行数据存储、查询。比如 MongoDB 和 Redis。学习如何通过 缓存避免重复下载的问题。
4、能使用一些开源框架 Scrapy ,Scrapy -Redis 等分布式爬虫,能部署掌控分布式爬虫 进行大规模数据爬取。
三、Request简介-让HTTP服务人类

(一)requests库简介
Urllib 和 Requests 模块是发起 http 请求最常见的模块。
(但是Urllib 库是较早出的,一些功能并没有requests强大,使用)
虽然 Python 的标准库中 urllib 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,
而 Requests 自称 “http for Humans”,说明使用更简洁方便。
Requests 继承了 urllib 的所有特性。Requests 支持 http 连接保持和连接池,支持使用 cookie 保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。
requests 的底层实现其实就是 urllib3(urllib2 的升级版---python2 支持)
Requests 的文档非常完备,中文文档也相当不错。Requests 能完全满足当前网络的需求, 支持 Python 2.6—3.6.
开源地址:http://github.com/kennethreitz/requests
中文文档 API:http://2.python-requests.org/zh_CN/latest/
(二)安装方式
利用 pip 安装 或者利用 easy_install 都可以完成安装:$ pip install requests
四、Requests模块 get请求

(一)网络请求
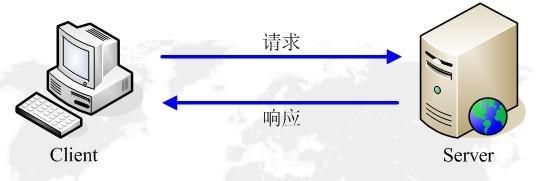
当我们在客户端输入一个 url,获取 url 所对应的页面内容时,其过程如下图所示。
客户 端发送一个请求,服务器收到这个请求后就会将请求所对应的响应返回给客户端,客户端收 到这个响应将其显示出来。
我们使用 requests 模块其实就是在模仿客户端和服务器的这个过程。
客户端发送请求主要有两种请求方法—get和post。get请求主要是从服务器去获取内容, 大多数的请求都是 get 请求,post 请求是向服务器提交一些内容,比如表单等。
请求和响应模型:
(二)使用 requests 发送 get 请求
基本使用语法格式:
import requests #导入模块
response = requests.get(
url = 请求 url 地址,
headers = 请求头字典,
params=请求参数字典,
)
get参数:url、headers、params
爬虫其实和web是相反思路
爬虫的基本思想:自动抓取万维网数据的脚本或程序
1、浏览器请求http过程(面试)
- 当用户在浏览器的地址栏中输入一个URL并按回车键之后,浏览器会向http请求。http请求主要分为‘Get’和‘Post’两种方法。
- 当我们在浏览器输入URL:http://www.baidu.com的时候,浏览器发送一个Request请求去获取http://www.baidu.com的html文件服务器把Response文件对象发送回给浏览器
- 浏览器分析Response 中的HTML,发现其中应用了很多其他文件,比如images文件,CSS文件,JS文件。浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
- 当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
2、请求失败分析
爬虫是模仿浏览器进行数据的获取。
如果响应数据有误,就是模仿的不到位。主要的错误位置就是请求头有问题。、
请求:user-agent:最重要,是反爬的第一步。
(三)response 对象的属性

1、字符串响应内容
response.text 响应为字符串
当我们使用 response.text 来获取页面内容的时候,Requests 会自动解码来自服务器的内 容,response.text 获取的是页面字符串内容。Requests 模块其实是根据 response.encoding 编码格式,将内容服务器返回的数据编码成字符串的。
打印的是整个url指定的页面html (没有定位解析情况下) 字符串格式
2、二进制响应内容
response.content 二进制格式
Requests 会自动为你解码 gzip 和 deflate 传输编码的响应数据。
打印的是整个url指定的页面html 二进制格式
3、json 响应内容
response.json()
Requests 中也有一个内置的 JSON 解码器,助你处理 JSON 数据。
如果 JSON 解码失败, response.json() 就会抛出一个异常。
例如,响应内容是 401 (Unauthorized),尝试访 问 response.json() 将会抛出 ValueError: No JSON object could be decoded 异常。
4、响应状态码
response.status_code
通过 response.status_code 我们可以获取响应的状态码
如果发送了一个错误请求(一个 4XX 客户端错误,或者 5XX 服务器错误响应),我们可以通过 Response.raise_for_status() 来抛出 HTTPError 异常。
5、响应头
response.headers
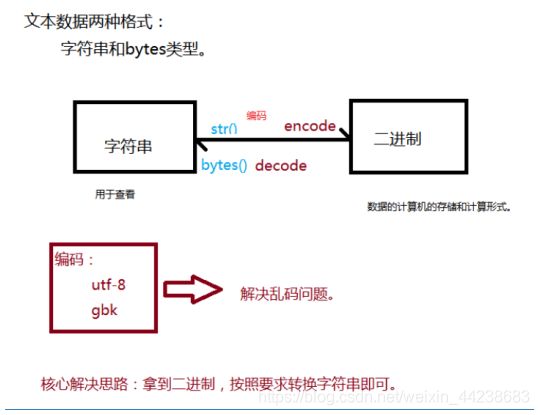
6、页面内容乱码问题(面试)
乱码问题主要原因就是编解码不一致,通常我们在使用 requests 模块发送请求后获取到 响应 response,我们想要打印响应内容,可以使用 response.text 方法。但是有时候通过这种 方法打印出来的页面内容时乱码,这时候我们可以通过以下两种方法来解决乱码问题。
方法一:
设置方法是给 response.encoding 设置一个正确的编码,requests 模块会自动根据设置的 编码来将服务器相应的内容按照这个编码成字符串,这时候我们通过 response.text 字段就可 以获取正确的页面内容了。
response_str = response.content.decode(encoding='utf-8')
放方二:
方法来将二进制内容按照提供的编码方式 编码成 unicode 字符串,进而正确显示
response.encoding = 'utf-8'
response.text是通过response.ecoding这个属性设置的值来进行编程字符串。
response.ecoding是通过resquests模块自动识别的。(基本识别都对的。)
(四)案例 1:爬取百度产品网页.py
版本一:(包含解析详细步骤)

点击下面链接
https://blog.csdn.net/weixin_44238683/article/details/107425790
版本二:


(五)案例 2:爬取新浪新闻.py
版本一:
(内容详细步骤)
点击下面链接
https://blog.csdn.net/weixin_44238683/article/details/107426530
版本二:
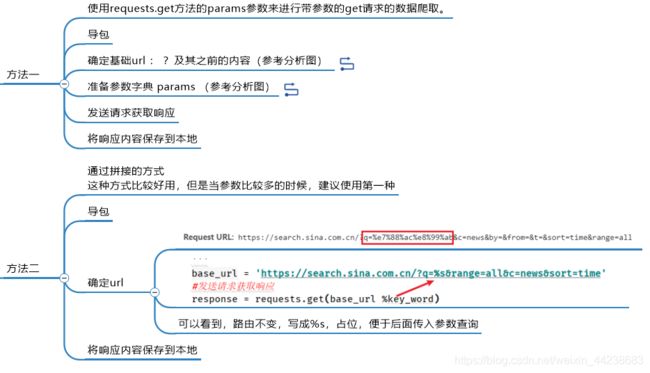
新浪新闻路由分析
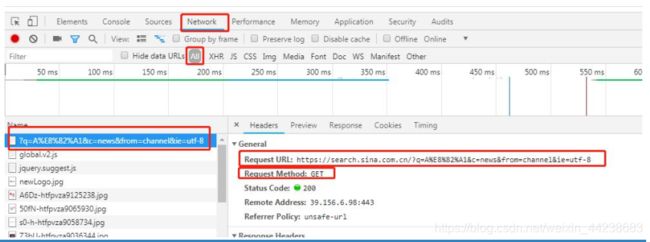
输入 A 股,分析检查返回的页面,如图所示(新浪页面开发者工具截图):

请求的是:http://search.sina.com.cn/?q=A%E8%82%A1&c=news&from=channel&ie=utf-8
请求方式是:get 请求。
携带的参数是:有四个,其中一个参数是中文,请求的时候需要编码。

(六)案例 3:批量爬取百度贴吧.py
项目需求:用户输入要搜索的贴吧名,进入贴吧,然后分页获取每一个贴吧的html保存
从需求可以知道一个问题,如果需要分页获取,那么一定要观察params,传入如第一页,第二页参数信息。
版本一:
(内含详细步骤)

点击下面链接
https://blog.csdn.net/weixin_44238683/article/details/107427995
版本二:

代码:

(七)案例 4:爬取百度
需求:之前爬取网页,都不需要headers参数,现在爬取,get,不带headers发现爬取的网页,不完整,使用headers伪装浏览器
这个案例开始往后,逐渐体会到了 user-agent的重要性
版本一:
(内含详细步骤)

点击下面链接
https://blog.csdn.net/weixin_44238683/article/details/107428312
版本二:

代码

五、Request模块 post请求

在前面的案例中,使用的非传传参式请求,get
并且知道了两种爬取方法
方法一:拼接url参数
方法二:使用params
另外就是,如果页面数据爬取不到,需要伪装浏览器headers user-agent 客户端标识
从后面开始默认都要加上这个浏览器客户标识
(一)最基本的Post请求使用方法
(1)导入request 模块
import requests
(2)发送请求,获取响应
response = requests.post(
url=请求 url 地址,
headers = 请求头字典,
data=请求数据字典,
)
(二)案例 5:重写百度翻译.py
基本分析:

版本一:
(内容详细)

点击下面链接
https://blog.csdn.net/weixin_44238683/article/details/107428530
版本二:
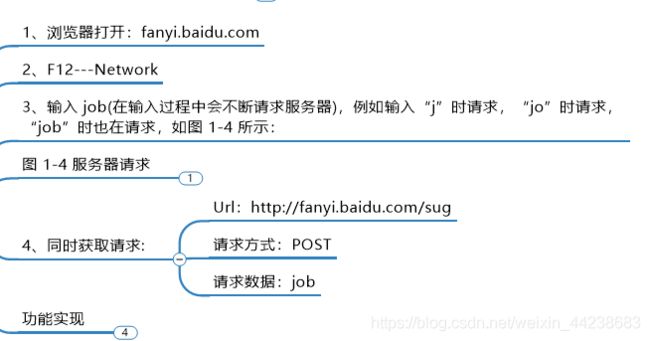
1、浏览器打开:fanyi.baidu.com
2、F12—Network
3、输入 job(在输入过程中会不断请求服务器),例如输入“j”时请求,“jo”时请求, “job”时也在请求,如下图所示:
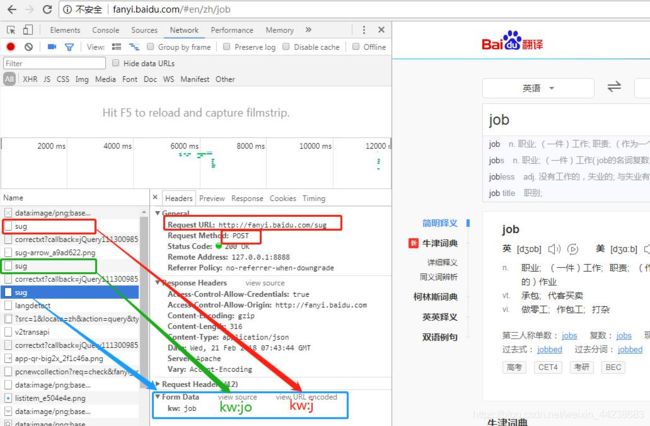
4、同时获取请求:
Url:http://fanyi.baidu.com/sug
请求方式:POST
请求数据:job
方式一:

方式二:

(三)补充案例,金山词霸翻译
import requests
import json
def translate_word(word):
# 确定路由
base_url = 'http://fy.iciba.com/ajax.php?a=fy'
# 准备参数
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
data = {
'f': 'auto',
't': 'auto',
'w': word,
}
# 获取响应参数
response = requests.post(base_url, headers=headers, data=data)
print(response.json())
result = ''
for data in response.json()['content']['word_mean']:
result += data
return result
def main():
# 1、确定翻译内容
word = input('请求输入单词:')
# 2、翻译
result = translate_word(word)
# 3、显示
print(result)
if __name__ == '__main__':
main()
六、项目总结
