自然语言处理-文本分类入门
文章目录
-
- 一、基于特征的分类
-
-
- 1.获取特征
-
- 文本预处理
- 分词
- 特征构建
- 2.喂给算法
- 3.调试算法参数
-
- 二、端到端的分类
-
-
- 1.fasttext文本分类
- 2.CNN文本分类
- 3.RNN文本分类
- 4.组合模型
- 5.HAN分类
- 6.更强大的词向量
-
在NLP任务中,文本分类算是最常见的应用。入门的自然语言处理\机器学习任务大都讲到垃圾邮件识别,而这就是一个文本分类任务。文本分类常见的应用包含情感分析、分类标签获取、新闻分类等等。
对于分类和聚类问题(或者说大部分机器学习任务), 都是3步走
- 获取特征,
- 喂给机器学习算法,
- 评测、调试算法参数。
本文, 我们基于特征的不同 按照两种思路来说:基于特征的方法 和 端到端的方法。
一、基于特征的分类
1.获取特征
在机器学习任务中,特征绝对是解决任务的关键(下文代码即可以看到机器学习模型套用确实很简单), 处理特征的过程也即特征工程。
而文本数据结构相对单一(仅仅包含字符串), 因此在不增加额外特征的情况下,特征工程也相对单一,一般使用向量空间模型来表示文本。
文本预处理
文本预处理主要是对文本内容进行清洗,去除不相关的内容。最基础的清洗就是 对爬取数据非正文内容的清洗( 那些前端html语言字符串肯定对于网页文本分类相关行是不大的,只会增加数据的噪音),或者在分词之后对停用词的去除。
停用词指的是出现频繁而与任务不相关的词语,比如说 "你 我 他 这 那 "这些词语。 但是停用词也是和任务极其相关的:在新闻分类中,"好 坏"就算停用词; 而在情感分析中"好 坏"绝对算关键特征词语。
分词
将文本字符串处理为单个词语列表的过程就是分词。最基础的分词方法即调用jieba进行分词。
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
## 他, 来到, 了, 网易, 杭研, 大厦
jieba的github上对其使用算法描述如下:
基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
按照我浅显的理解,jieba分词是结合词典和HMM模型进行分词。详细可见博客
对于常见类型文本, jieba分词的效果已经较好,而且分词速度相比其他几个工具也有优势。但是对于特定领域的文本(比如说军事,金融)其分词效果和分词粒度不一定是我们想要的。分词本身也是一个NLP基本任务,我们可以构建自己的分词数据集(大量人工)并搭建自己的分词工具。
常见的分词方法包括: HMM,CRF,LSTM ,BI-LSTM-CRF,BERT+BI-LSTM+CRF。现在真实应用场景下最常见的就是BI-LSTM-CRF。
当然: 一般来说, 我们只需要使用jieba自定义词典就可以基本上达到按照我们的想法分词,而这个工作量也远远小于自己重新做分词工具。
特征构建
如果每个词语就是我们的一个特征,那么并非每个词语都是我们需要的特征。这里存在三个问题:
- 选择哪些词语作为特征
- 每个特征的权重是多少
- 能不能增加额外的特征
问题1
一般根据某个指标独立的对原始特征项进行评分排序,从中选择得分较高的一些特征(词语)。常见的指标一般包含:(统计自然语言处理-宗成庆 第13章)
- 文档频率: 统计词语在文档中出现的频率,去除出现频率太高或者太低的词语。出现频率太高,每篇文档都出现, 不能区别各个类别的各个文档;出现频率太低, 词语如果只出现一次那么其肯定也是不能代表其出现文档所在类别的,另外增加了特征维度却没有提供足够信息。
- 互信息: 统计各个词语是否出现和文档类别的互信息。留下互信息大的。
- 信息增益: 统计各个词语是否出现对文档类别信息增益。留下信息增益大的。
- x2统计: 统计各个词语是否出现和文档类别的互信息。留下相关性打的。
其实 互信息、信息增益、x2统计都是统计训练集中词语和文档类别的相关性,如果在训练集中词语和文档类别相关性小,由于训练测试集合同分布,那么该词语和测试集中的文档类别相关性也小,所以我们就不关心该词语。在机器学习的特征编码中,目标编码感觉也是类似的思路。
问题2
前面选择了部分词语作为特征, 接下来应该确认各个特征的权重了。
常用的作为权重的有:
- 词频: 词语在该文章中出现的频率
- TF-IDF值: TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
问题3
除了前面的基础特征, 我们也可以增加一些额外特征,比如说文章长度、文章来源、甚至文章是否出现大写字母.(感觉由于向量空间模型的维度比较大,其实添加部分特征的效果是不显著的)
也可以添加一些其他特征: 比如说句法分析的信息。
最最最基础实现:
# 数据来源为 https://github.com/skdjfla/toutiao-text-classfication-dataset
def load_dataset(filepath: str = 'data/头条分类数据.txt', sample: bool or int = False) -> Tuple:
texts, labels = [], []
with open(filepath, 'r') as f:
for i, line in enumerate(f):
if sample and i == sample:
break
_, _, label, text, _ = line.split('_!_')
text = ' '.join(jieba.cut(text))
texts.append(text)
labels.append(label)
return texts, labels
def apply(instance, train, test):
""" 对train和test分别处理"""
train = instance.fit_transform(train)
test = instance.transform(test)
return train, test
texts, labels = load_dataset(sample=True)
trainDF = pandas.DataFrame()
trainDF['text'] = texts
trainDF['label'] = labels
# 划分训练集,测试集
X_train, X_test, y_train, y_test = train_test_split(trainDF['text'], trainDF['label'], test_size=0.05, stratify=labels,
random_state=0)
# 标签列处理
label_encoder = preprocessing.LabelEncoder()
y_train, y_test = apply(label_encoder, y_train, y_test)
# 数据列处理
count_vectorizer = CountVectorizer()
tfidf_transformer = TfidfTransformer()
X_train, X_test = apply(count_vectorizer, X_train, X_test)
X_train, X_test = apply(tfidf_transformer, X_train, X_test)
2.喂给算法
通过前文的处理, 文本数据已经完全处理成算法可以轻松处理的数值型特征了。近乎所有的分类算法都可以处理这类数据, 具体如下:
class ModelTest():
def __init__(self, X_train, y_train, X_test, y_test):
self.X_train, self.y_train, self.X_test, self.y_test = X_train, y_train, X_test, y_test
def eval(self, classifier):
"""测试模型"""
classifier.fit(self.X_train, self.y_train)
predictions = classifier.predict(self.X_test)
score = metrics.f1_score(predictions, self.y_test, average='weighted')
print('weighted f1-score : %.03f' % score)
def apply(self, instance):
""" 对train和test分别处理"""
self.X_train = instance.fit_transform(self.X_train)
self.X_test = instance.transform(self.X_test)
modeltest = ModelTest(X_train, y_train, X_test, y_test)
models = OrderedDict([
('KNN', neighbors.KNeighborsClassifier()),
('logistic回归', linear_model.LogisticRegression()),
('svm', svm.SVC()),
('朴素贝叶斯', naive_bayes.MultinomialNB()),
('决策树', tree.DecisionTreeClassifier()),
('决策树bagging', BaggingClassifier()),
('随机森林', RandomForestClassifier()),
('adaboost', AdaBoostClassifier()),
('gbdt', GradientBoostingClassifier()),
('xgboost', XGBClassifier()),
])
for name, clf in models.items():
modeltest.eval(clf)
3.调试算法参数
前面可以看到使用sklearn进行机器学习确实很简单,前面也仅仅列举了部分机器学习算法。但是有两个问题:
- 哪个算法是在当前任务上效果最好
- 该算法的参数如何设定
问题1
哪类问题使用何种算法这个需要任务经验加上说对算法的理解。按照我的理解朴素贝叶斯应该是解决文本分类最经典的做法, 而xgboost又是kaggle竞赛的一大神器,但是并不清楚谁能做到最好,唯一可以肯定的是KNN应该不是最好的做法。
问题2
算法参数如何调试?一个一个试就知道了。sklearn包含了网格参数搜索和随机搜索的工具(感觉自己写也挺快的)
参考代码
parameters = {
'gamma': [0.001, 0.01, 0.1, 1], 'C':[0.001, 0.01, 0.1, 1,10]}
gs = GridSearchCV(SVC(), parameters, refit = True, cv = 5, verbose = 1, n_jobs = -1)
gs.fit(X,y)
print('最优参数: ',gs.best_params_)
print('最佳性能: ', gs.best_score_)
对于算法收敛很快,数据集小的情况, 网格搜索确实可以获取到自定义参数空间的最优参数,但是对于算法耗时、数据量大而自定参数空间比较大的时候,随机搜索往往可以更快的挖掘到最优效果。所以一般先使用随机搜索找出关键性参数, 然后网格搜索找出最优参数。
二、端到端的分类
前面也可以看出来, 其实机器学习任务大部分工作量都在特征工程一段(前文特征极其基础,可能不是很明显), 而另一类方法使用较少的特征工程,完全使用模型来实现分类。也即:输入为文本,输出为类别,中间全是模型,较少的特征工程。
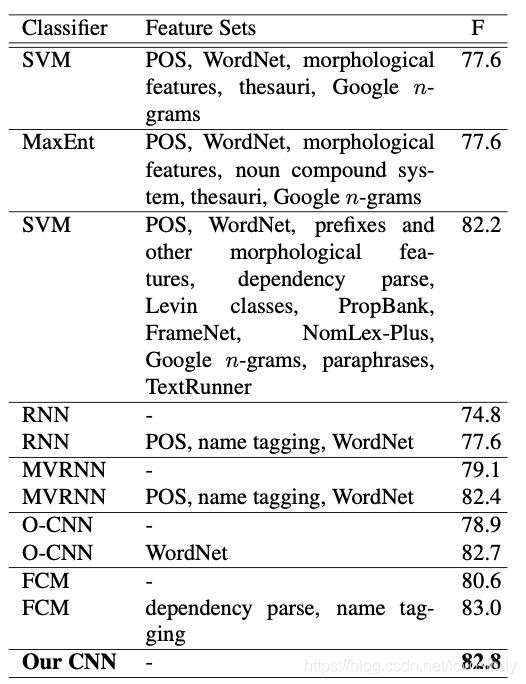
具体的,通过这个图片对比SVM和“Our CNN”模型就,SVM为基于特征的方法,显然文章添加基于外部的大量特征,而CNN方法只使用了文本字符串。两者性能差距其实不是很明显,但是CNN相比SVM少的这部分特征,也就是省去的构建人工特征时间。
笔者感觉,对于大部分基础任务,现在端到端的实现方式已经可以较好的完成任务,还省去大量特征工程的时间。而对于偏应用或着个性化领域的任务,仍然需要人工特征来获取更好的效果。
当然,使用端到端的方法并非放弃文本的信息。常见的NLP任务中使用预训练词向量,其实是添加了更加丰富的基础语义信息(fasttext除外)。接下来介绍基础的端到端的文本分类模型。
1.fasttext文本分类
fasttext是facebook开源的一个词向量与文本分类工具,典型应用场景是“带监督的文本分类问题”。具体其大概就是 N-gram子词特征 + CBOW + 层次SoftMax +负采样。其训练速度快, 并且不需要预训练的词向量,效果也较好。具体其代码如下(感觉类似于sklearn):
保证训练测试文本格式如下
2018 年 养羊 怎么样 ? __label__0
中国 第一所 私立 研究型 大学 成立 , 2023 年招 本科生 __label__3
# 训练模型
model = fasttext.train_supervised('data/fasttext.train.txt',epoch=10)
model.save_model("data/model_filename.bin")
# 测试模型
model = fasttext.load_model("data/model_filename.bin")
texts_test, labels_test = [], []
with open('data/fasttext.test.txt', 'r') as f:
for line in f:
*text, label = line.strip().split(' ')
text = ' '.join(text)
texts_test.append(text)
labels_test.append(label)
label_encoder = preprocessing.LabelEncoder()
labels_test = label_encoder.fit_transform(labels_test)
predits = list(zip(*(model.predict(texts_test)[0])))[0]
predits = label_encoder.transform(predits)
score = metrics.f1_score(predits, labels_test, average='weighted')
print('weighted f1-score : %.03f' % score)
2.CNN文本分类
Fasttext不需要预训练的词向量,其在训练分类任务的同时训练词语和n-gram子串的向量表示。而其他的大部分任务都是需要预训练词向量的。
CNN进行文本分类,感觉是端到端模型中性价比最高的。CNN进行文本分类模型相对简单,训练时间短并且效果很好。
最简单的CNN文本分类模型如下图。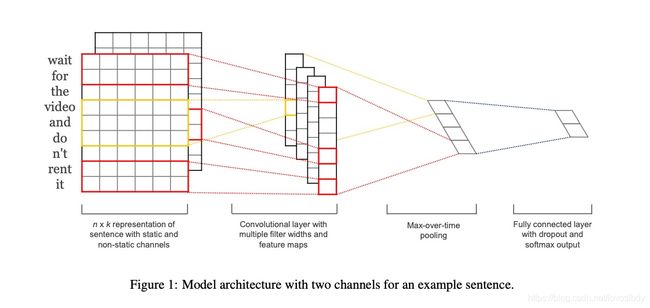
这个模型可以说是CNN最简版本了,相比CV里面的几十上百层卷机,就是这个模型就可以取得很好的效果。具体模型的讲解可以参见这篇博客
3.RNN文本分类
一般场景中直接使用RNN的较少,最常用的RNN应该是LSTM模型。由于RNN天生适合处理序列数据,而文本就是序列数据。LSTM处理分类可以直接将最后一个序列的输出作为句子的特征,也可以连接全部词语的输出作为句子特征,之后接分类层就可以实现分类。在LSTM之后也可以加入注意力层来提高效果。
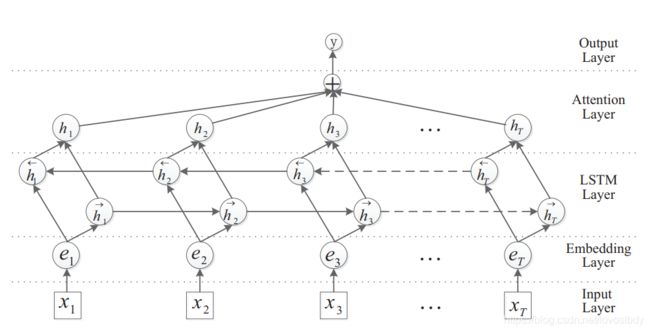
4.组合模型
现在可以发现其实大量的模型可以拼接,因为特征的相对统一,我们完全可以在CNN后接RNN,也可以在RNN后套CNN,按理说都可以取得一定的效果。但是这里确实也存在一个问题,就是增加了模型的复杂度,其拟合能力更强,也需要更多的数据,而现实场景下我们的数据集大小往往满足不了模型复杂度的要求。
5.HAN分类
另外对于长文本来说,还可以按照文章-句子-词语这样的层次来逐渐获取特征。常见的端文本分类,文本等效于句子。

HAN就是先利用RNN获取句子特征,再基于句子特征来获取文本特征。其特征抽取更加符合常理,在长文本的分类上其分类的效果更好。
6.更强大的词向量
前面讲到的各个方法其实都使用了word2vec预训练的词向量或者glove词向量(除fasttext), 也就是这些模型句子特征表示的基础就是词向量,只是其基于词向量获取句子特征的模型方法不同。但是这类静态词向量(not contextualized word embedding)不能处理多义词问题。也就是 "苹果很好吃"和"苹果出新款了"这两个苹果是一个表示。而这类多义词是非常常见的。
而动态词向量(contextualized word embedding)其实是可以理解该语句环境下该词语的正确表示,也就是要获取该词语向量的表示,还需要看完整个句子的到底是在说啥。这类动态词向量不仅仅是获取一个词语向量的过程,还包括了对整句话语义理解的过程。因此其对每个词语表示更加准确。
(现有通用词向量是在训练语言模型中产生的词语向量表示,我们认为其向量表示和特定任务下词语的向量表示相差不大,所以可以通过微调的方式获取特定任务的词语向量表示)
常见的动态词向量表示:
- ELMO
- GPT
- BERT
- ALBERT

具体对我来说,不同的词向量还是只是一个词语表示过程而已,其在模型中的功能也和之前的词向量相同,现在各个语言中调用也极其简单。
对于大部分NLP任务,上BERT都可以获取较大的性能提升,当然其也比简单静态词向量消耗机器性能和电费。
ALBERT相比BERT其参数量小些,在效果上影响不大。
感谢大家阅读。
算是第一次写文章,也还远远没有入门NLP,所以可能有大量错误,欢迎大家批评指正。
下面是公众号,欢迎扫描二维码,谢谢关注,谢谢支持!
公众号名称: Python入坑NLP
本公众号主要致力于自然语言处理、机器学习、coding算法以及Python的一些知识分享。本人只是小菜,希望记录自己学习、工作过程的同时,大家一起进步。欢迎交流、分享。
