百度一二三面!喜提提起批offer!别问,问就是牛逼!
学弟轻轻松松又怒斩B(百度)B(头条)AT offer 真的太强了,乔戈里问学弟要来了刚出炉的百度面经,觉得文章不错的在看转发支持一下!
7.29 20:00 - 21:00 百度 一面
问题如下:
直接开始做算法题:第一题是写一个变种的二分查找,也就是写寻找最左侧边界的二分搜索,第二题是 LeetCode 第 81 题:搜索旋转排序数组 II;
/**
* 返回的是比target小的数量,同时也是最左target的下标
* @param nums
* @param target
* @return
*/
int binarySearchLeft(int nums[],int target){
int left = 0;
int right = nums.length;
while(left < right){
//防止计算mid时溢出
int mid = left + (right - left) / 2;
if(nums[mid] == target)
right = mid;
else if(nums[mid] < target)
left = mid + 1;
else if(nums[mid] > target)
right = mid;
}
//要时刻注意处理边界,如果整个数组都没有这个target,则left会到nums.length
//left的取值是[0,nums.length]
// target 比所有数都大
if (left == nums.length) return -1;
// 类似之前算法的处理方式
return nums[left] == target ? left : -1;
}
class Solution {
public boolean search(int[] nums, int target) {
if (nums == null || nums.length == 0) {
return false;
}
int start = 0;
int end = nums.length - 1;
int mid;
while (start <= end) {
mid = start + (end - start) / 2;
if (nums[mid] == target) {
return true;
}
if (nums[start] == nums[mid]) {
start++;
continue;
}
//前半部分有序
if (nums[start] <= nums[mid]) {
//target在前半部分
if (nums[mid] > target && nums[start] <= target) {
end = mid - 1;
} else { //否则,去后半部分找
start = mid + 1;
}
} else {
//后半部分有序
//target在后半部分
if (nums[mid] < target && nums[end] >= target) {
start = mid + 1;
} else { //否则,去后半部分找
end = mid - 1;
}
}
}
//一直没找到,返回false
return false;
}
}
对套接字编程的详细过程进行描述,讲解 tcp 三次握手四次挥手过程中客户端服务器端的状态,分析服务器端 close_wait 的进程太多的原因是什么;
套接字编程流程
一个简易的 Server 的流程如下:
1.建立连接,接受一个客户端连接。
2.接受请求,从网络中读取一条 HTTP 请求报文。
3.处理请求,访问资源。
4.构建响应,创建带有 header 的 HTTP 响应报文。
5.发送响应,传给客户端。
省略流程 3,大体的程序与调用的函数逻辑如下:
socket() 创建套接字
bind() 分配套接字地址
listen() 等待连接请求
accept() 允许连接请求
read()/write() 数据交换
close() 关闭连接
三次握手
四次挥手
close_wait 太多,一般的原因就是服务器端没有主动调用 close()。
进程间通信 IPC 的方式有哪些,然后问哪个是最快的『共享内存』;
通信方式:「来自于:https://mp.weixin.qq.com/s/mblyh6XrLj1bCwL0Evs-Vg」
管道
消息队列
共享内存
信号量
信号
Socket
由于每个进程的用户空间都是独立的,不能相互访问,这时就需要借助内核空间来实现进程间通信,原因很简单,每个进程都是共享一个内核空间。
Linux 内核提供了不少进程间通信的方式,其中最简单的方式就是管道,管道分为「匿名管道」和「命名管道」。
匿名管道顾名思义,它没有名字标识,匿名管道是特殊文件只存在于内存,没有存在于文件系统中,shell 命令中的「
|」竖线就是匿名管道,通信的数据是无格式的流并且大小受限,通信的方式是单向的,数据只能在一个方向上流动,如果要双向通信,需要创建两个管道,再来匿名管道是只能用于存在父子关系的进程间通信,匿名管道的生命周期随着进程创建而建立,随着进程终止而消失。命名管道突破了匿名管道只能在亲缘关系进程间的通信限制,因为使用命名管道的前提,需要在文件系统创建一个类型为 p 的设备文件,那么毫无关系的进程就可以通过这个设备文件进行通信。另外,不管是匿名管道还是命名管道,进程写入的数据都是缓存在内核中,另一个进程读取数据时候自然也是从内核中获取,同时通信数据都遵循先进先出原则,不支持 lseek 之类的文件定位操作。
消息队列克服了管道通信的数据是无格式的字节流的问题,消息队列实际上是保存在内核的「消息链表」,消息队列的消息体是可以用户自定义的数据类型,发送数据时,会被分成一个一个独立的消息体,当然接收数据时,也要与发送方发送的消息体的数据类型保持一致,这样才能保证读取的数据是正确的。消息队列通信的速度不是最及时的,毕竟每次数据的写入和读取都需要经过用户态与内核态之间的拷贝过程。
共享内存可以解决消息队列通信中用户态与内核态之间数据拷贝过程带来的开销,它直接分配一个共享空间,每个进程都可以直接访问,就像访问进程自己的空间一样快捷方便,不需要陷入内核态或者系统调用,大大提高了通信的速度,享有最快的进程间通信方式之名。但是便捷高效的共享内存通信,带来新的问题,多进程竞争同个共享资源会造成数据的错乱。
那么,就需要信号量来保护共享资源,以确保任何时刻只能有一个进程访问共享资源,这种方式就是互斥访问。信号量不仅可以实现访问的互斥性,还可以实现进程间的同步,信号量其实是一个计数器,表示的是资源个数,其值可以通过两个原子操作来控制,分别是 P 操作和 V 操作。
与信号量名字很相似的叫信号,它俩名字虽然相似,但功能一点儿都不一样。信号是进程间通信机制中唯一的异步通信机制,信号可以在应用进程和内核之间直接交互,内核也可以利用信号来通知用户空间的进程发生了哪些系统事件,信号事件的来源主要有硬件来源(如键盘 Cltr+C )和软件来源(如 kill 命令),一旦有信号发生,进程有三种方式响应信号 1. 执行默认操作、2. 捕捉信号、3. 忽略信号。有两个信号是应用进程无法捕捉和忽略的,即
SIGKILL和SEGSTOP,这是为了方便我们能在任何时候结束或停止某个进程。前面说到的通信机制,都是工作于同一台主机,如果要与不同主机的进程间通信,那么就需要 Socket 通信了。Socket 实际上不仅用于不同的主机进程间通信,还可以用于本地主机进程间通信,可根据创建 Socket 的类型不同,分为三种常见的通信方式,一个是基于 TCP 协议的通信方式,一个是基于 UDP 协议的通信方式,一个是本地进程间通信方式。
然后讲到共享内存,就提到了内存映射,自然就问了 mmap,为什么 mmap 快?
快的原因就是减少了数据从内核态到用户态的拷贝,直接将内核空间和用户空间映射。
共享内存有哪些危害,如何避免?
共享内存后,不同进程间可以相互修改变量,容易造成不安全的现象,需要通过一些同步手段实现进程间的数据安全问题。
虚拟内存和物理内存区别,操作系统如何控制,如何使用;
物理内存地址是主存真实的地址,而虚拟内存则是作为一个抽象层,成为了进程和物理内存的桥梁。
虚拟内存和物理内存是通过 MMU(Memory Management Unit,内存管理单元) 来进行转换和映射的,内存管理单元中最重要的数据结构就是页表,在页表中,虚拟地址有三种状态:未被使用、未被缓存、已缓存:
如果是未被使用,则该虚拟地址并不存在于磁盘或者主存中;
如果是未被缓存的状态,说明虚拟地址此时对应的真实地址为磁盘地址,如果此时进程去访问未被缓存的虚拟地址,会触发缺页中断,操作系统会将磁盘上未被缓存的虚拟页加载到主存中,然后更新页表;
如果是已缓存的状态,说明虚拟地址此时对应的地址就是物理内存,也就是我们的主存。
总的来说,面试体验还是 Okay,面试官比较 nice,没有刻意刁难,提的问题也比较有探讨的感觉,让人感觉很不错,等一波二面啦,后面继续更新!
8.3 19:00 - 21:30 百度 二三面「已offer」
两面接着,感觉还是有点累的,二面主要问项目,三面则主要问一些发散性思维的问题以及聊聊生活工作,整体的面试过程非常 nice,offer 应该是没问题辽!
二面问的问题由浅入深,循循善诱,感觉面试官非常的专业,总结一下:
自我介绍;
讲一下自己了解的微服务,我说我用的HSF比较多,然后话题就此展开;
先讲了讲 HSF 底层用的 Netty 和 Hessian,讲讲 Netty 为啥这么快;
Netty 中的 NIO 的模型,以及为何这么快,自己是否试验过 NIO 和 BIO 速度的差别;
比较简单... 略
Hessian序列化为何这么快,内部的逻辑实现了解吗?
衡量一个序列化框架,主要有以下几个指标:
 序列化框架总结
序列化框架总结
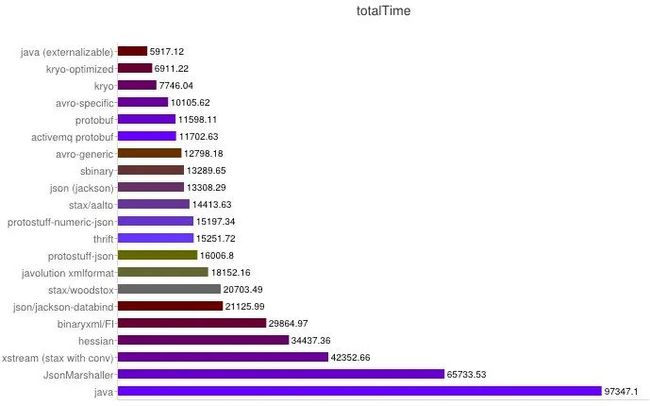 时间开销比较
时间开销比较
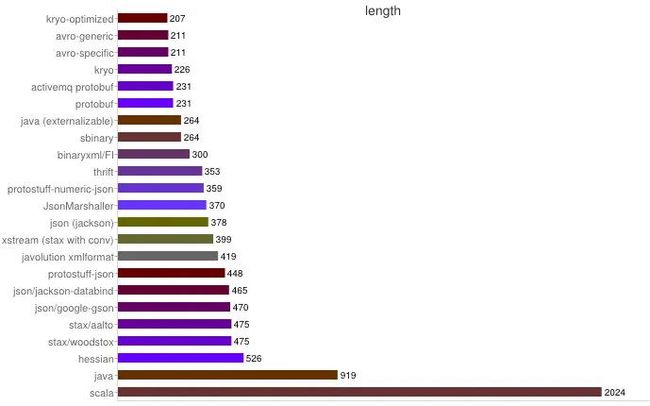 空间开销比较
空间开销比较
性能。包括时间开销方面的性能和空间开销方面的性能。时间开销,是指序列化反序列化解析的时间,空间开销,则是指相同的对象在序列化后所占的字节数。
通用性。是否支持跨平台,跨语言。
可扩展性、兼容性。如果序列化协议具有良好的可扩展性,支持自动增加新的业务字段,而不影响老的服务,这将大大提供系统的灵活度。
讲讲自己用的消息中间件,kafka 的用途有什么,为什么项目中要用 kafka?
-
主要就两个作用:
异步,生产者和消费者速率不同步;
解耦,主要规定好输入输出的消息格式,就可以对系统进行解耦。
了解 k8s,Docker,多线程的落地实现吗?
多线程的实现... 略难,这里不详细说了。
API 网关的用途,为何要用这个东西?
对于服务数量众多、复杂度比较高、规模比较大的业务来说,引入 API 网关有一系列的好处:
聚合接口使得服务对调用者透明,客户端与后端的耦合度降低
聚合后台服务,节省流量,提高性能,提升用户体验
提供安全、流控、过滤、缓存、计费、监控等 API 管理功能
长连接和短连接的区别?微服务中主要使用哪种连接?为什么?
短连接:每次通信时,创建 Socket;一次通信结束,调用 socket.close()。这就是一般意义上的短连接,短连接的好处是管理起来比较简单,存在的连接都是可用的连接,不需要额外的控制手段。
长连接:每次通信完毕后,不会关闭连接,这样就可以做到连接的复用。长连接的好处便是省去了创建连接的耗时。
短连接和长连接的优势,分别是对方的劣势。想要图简单,不追求高性能,使用短连接合适,这样我们就不需要操心连接状态的管理;想要追求性能,使用长连接,我们就需要担心各种问题:比如端对端连接的维护,连接的保活「 TCP 中的 KeepAlive 机制 + 应用层心跳」。
微服务中主要使用长连接,因为追求性能。
如何实现调用微服务中链路的记录?
可以使用字节码增强技术,动态代理,改造 Request,在Request中记录一些 trace,然后带到下一个调用者中。
进程和线程区别,进程间通信方式,讲讲 mmap?
进程是操作系统分配资源的最小单位,线程是CPU调度的最小单位。
进程间通信方式:管道、共享内存、信号量、信号、消息队列、Socket。
mmap,称为内存地址映射,将内核缓冲区的地址映射到用户缓冲区。
讲讲进程fork多个子进程和使用多线程的区别?
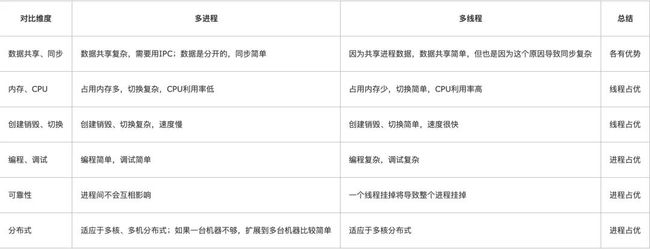 多进程 vs 多线程
多进程 vs 多线程
差不多就这些,还有很多回忆不起来了,问的都是项目中用到的一些东西,然后主要是看广度,深度不是很深,大概问了50多分钟,然后开始做题:
给定一些数(1,0),(2,1),(3,1),(4,2),(5,2),(6,2),前面是节点位置,后面是其父亲节点,构造出这样的一颗多叉树出来;
package 秋招百度二面; import java.util.*; public class Second { // (1,0),(2,1),(3,1),(4,2),(5,2),(6,2) public static void main(String[] args) { int[][] input = new int[][]{ {1, 0}, {2, 1}, {3, 1}, {4, 2}, {5, 3}, {6, 2}}; // 构建根节点,其中的 Set 集合 first 是下面 BFS 前确定 root 要用到的 Setfirst = new HashSet<>(); Set roots = new HashSet<>(); for (int i = 0; i < input.length; i++) { roots.add(input[i][1]); first.add(input[i][0]); } Map list = new ArrayList<>(); node.children = list; rootNodes.put(index, node); } // 构建叶子节点 Set leaf = new HashSet<>(); for (int i = 0; i < input.length; i++) { if (!roots.contains(input[i][0])) { leaf.add(input[i][0]); } } Map arrayList = new ArrayList<>(); Queue queue = new ArrayDeque<>(); Node cur = root; queue.add(cur); while (!queue.isEmpty()) { cur = queue.poll(); arrayList.add(cur.val); if (cur.children != null && cur.children.size() != 0) { for (Node node : cur.children) { queue.add(node); } } } System.out.println(arrayList); } } class Node { public int val; public List children; public Node(int val) { this.val = val; } } 二叉树翻转,写出树的数据结构,并且写前序遍历递归输出树。
private static TreeNode1 invertTree(TreeNode1 root){ if(root == null) return null; TreeNode1 left = invertTree(root.left); TreeNode1 right = invertTree(root.right); root.left = right; root.right = left; return root; } private static ListpreOrder(TreeNode1 root){ List result = new LinkedList<>(); proOrderHelper(root,result); return result; } private static void proOrderHelper(TreeNode1 root, List result) { if(root == null) return; result.add(root.val); proOrderHelper(root.left,result); proOrderHelper(root.right,result); } class TreeNode1 { public int val; public TreeNode1 left; public TreeNode1 right; public TreeNode1(int x) { val = x; } } 三面是工大的师兄,所以整体非常愉快,基本上就是聊天,面试流程如下:
自我介绍;
聊一聊工大的一些事,这里略过;
聊聊最近的阿里做的项目,针对项目提了很多问题;
主要是一些发散性的问题,例如如果让你下线老应用,如何劝说用户转到新应用呢?
既然是要转到新应用,说明老应用可能在维护上或者使用上有很大的问题,亟需解决,所以需要抓住那些影响很大的用户,让他们进行新应用的灰度,解决他们的痛点,然后将这些用户转到新应用后的提效数据可视化,再去劝说其他用户。
对工作流、统一接入层问了一些相关的问题,整体难度不大。
项目中最大的难点是什么?最大的收获是什么?大学期间最难忘的一件事是什么?
自己在那件事上有什么收获呢?为什么会这么难忘?
最后做了个逻辑题,6个赛道,36匹马,需要几次能得到前三名?
剩下就是反问环节啦,没了。