RabbitMQ 在python下的一个坑 AMQPHeartbeatTimeout: No activity or too many missed heartbeats in the last 60
业务场景 : 这个场景下 RabbitMQ 是作为 分布式消息队列 的作用出现的,这里用的是 RabbitMQ 的 Routing 模式 ,这个就是在发布/订阅者 模式下 使用 RoutingKey 去匹配多个队列,使得发布者可以根据实际的情况把消息发送到指定的一个或多个消费者队列中去
问题出现 的 异常 : pika.exceptions.AMQPHeartbeatTimeout: No activity or too many missed heartbeats in the last 60 seconds
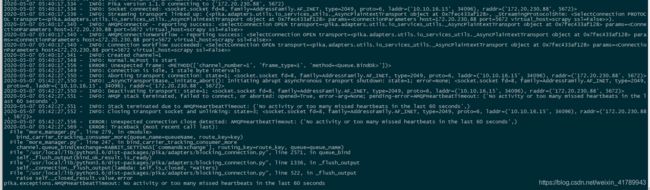
排查问题 : 一 、看到timeout,第一步想法是先排查MQ的连通性,是否能正常连接上.通过其他demo测试后是OK的;
二 、那就是这个的代码的问题,从翻译来看是一个心跳超时的问题,RabbitMQ 是有一个心跳检测的功能 , 这个心跳 检测是服务端用来检测客户端是否正常运行的一种机制 , 正常的话每隔一段时间客户端会发一个心跳包给服务 端,而现在这个异常应该是服务端没有再规定时间内收到这个心跳包所报出来的异常,这个就需要从代码上具体去 分析了 , 下面是出现异常的代码
credentials = pika.PlainCredentials(RABBIT_SETTINGS['username'], RABBIT_SETTINGS['password'])
connection = pika.BlockingConnection(pika.ConnectionParameters(host=RABBIT_SETTINGS['host'], port=RABBIT_SETTINGS['port'], credentials = credentials, virtual_host = RABBIT_SETTINGS['virtualHost']))
channel = connection.channel()
channel.exchange_declare(exchange=RABBIT_SETTINGS['commandExchange'], durable=True,
exchange_type='direct')
def while_get_mgs(queue_name,queueObject,isAuto):
"""
根据MQ消息归并多个消息然后同时去执行一个操作的消费者
"""
count = 0
maxcounts = 20
mqbody = MQBody(queueObject,isAuto) # MQBody 是一个处理消息的类
while True:
method, properties, body = channel.basic_get(queue_name)
if method:
if count <= maxcounts :
print(method.delivery_tag,properties.priority,body)
mqbody.add(method.delivery_tag,properties.priority,body)
count += 1
else:
mqbody.push_bodys(channel)
mqbody.add(method.delivery_tag,properties.priority,body)
count = 1
else:
if mqbody.bodys:
mqbody.push_bodys(channel)
count = 0
time.sleep(1)
def bind_consumer_more(queue_name='',route_key='',maxcount=20):
"""
启动一个队列
"""
p = Process(target=while_get_mgs, args=(queue_name,RABBITMQ_ROUTE_KEY_TO_EVENT[route_key],isAuto))
p.start()
channel.start_consuming()
logging.info('{} is start'.format(queue_name))
def run():
queues = ["wangye","zhugeqing","baoerjie"]
for queue in queues :
bind_consumer_more(queue,f"test.{queue}")这个代码实现的是一个 多个队列的消费者 监听 MQ 获取 消息的功能,但是每个队列的消费者 不是一次拿一个消息,而是一次拿多个消息
为什么不用 basic_consume 而用 basic_get ?
需求是一定需要连续拿多个消息然后合并成一个事件一块去处理,而 basic_consume 方法每次只能返回一个消息 ,它这个返回是直接调用回调函数的,考虑到一种情况,假如它再一段时间内只返回少量的消息,没有达到我去做下一步操作的阈值的话,这种要先去处理,用这个basic_consume就没这么直接了
为什么用进程而不用线程 ?
使用线程会在while_get_mgs 里面堵住,就只能监听一个队列,而不能多个
可能的原因是: 使用了多进程,但是channel这个链接的对象放在主进程,使得子进程里面的不能正常的和RabbiteMQ的服务端交互,这个可能是只有Python才出现的问题,使用其他语言(C#) 时是可以这么做的
最终的解决方式是 : 每一个队列消费者都独立使用一个channel,也就是一个独立的链接,每一个队列消费者起一个进程,互不干扰
def gen_channel(queue_name):
"""创建一个 channel 连接"""
credentials = pika.PlainCredentials(RABBIT_SETTINGS['username'], RABBIT_SETTINGS['password'])
connection = pika.BlockingConnection(pika.ConnectionParameters(host=RABBIT_SETTINGS['host'], port=RABBIT_SETTINGS['port'], credentials = credentials, virtual_host = RABBIT_SETTINGS['virtualHost']))
channel = connection.channel()
channel.exchange_declare(exchange=RABBIT_SETTINGS['commandExchange'], durable=True,
exchange_type='direct')
return channel
def while_get_mgs(queue_name,queueObject,isAuto,maxcounts):
"""
根据MQ消息归并多个消息然后同时去执行一个操作的消费者
"""
count = 0
gen_channel(queue_name)
mqbody = MQBody(queueObject,isAuto) # MQBody 是一个处理消息的类
while True:
method, properties, body = channel.basic_get(queue_name)
if method:
if count <= maxcounts :
print(method.delivery_tag,properties.priority,body)
mqbody.add(method.delivery_tag,properties.priority,body)
count += 1
else:
mqbody.push_bodys(channel)
mqbody.add(method.delivery_tag,properties.priority,body)
count = 1
else:
if mqbody.bodys:
mqbody.push_bodys(channel)
count = 0
time.sleep(1)
def bind_carrier_tracking_consumer_more(queue_name='',route_key='',maxcount=20):
"""
启动一个队列
"""
p = Process(target=while_get_mgs, args=(queue_name,RABBITMQ_ROUTE_KEY_TO_EVENT[route_key],isAuto,maxcount))
p.start()
logging.info('{} is start'.format(queue_name))
def run():
queues = ["wangye","zhugeqing","baoerjie"]
for queue in queues :
bind_carrier_tracking_consumer_more(queue,f"test.{queue}")