【承】Redis 原理篇——Redis 的内存回收机制
前言
关于 Redis 的“起承转合”,我前面已经用五个篇章的长度作了一个 Redis 基础篇——“起”篇的详细阐述,相信大家无论之前有没有接触过 Redis,都能从中学到不少东西。基础篇的内容顾名思义,只是个基础,主要说了 Redis 的发展以及 Redis 的基本数据类型,内容跟平时使用关联会比较大,难度不算大,希望大家能好好消化。
这里送上基础篇的飞机票:
【起】Redis 概述篇——带你走过 Redis 的前世今生
【起】Redis 基础篇——基本数据结构之String,Hash
【起】Redis 基础篇——基本数据结构之 List,Set
【起】Redis 基础篇——基本数据结构之 ZSet,Bitmap…
【起】Redis 基础篇——基本数据结构之总结篇
在“承”篇中,我会围绕 Redis 的原理来阐述,讲一些相对比较高级的特性,比如本篇章要讲到的 pub/sub(发布/订阅)模式,持久化机制,高性能特性,事务,内存回收机制等等,在接下来的篇章中,我会为大家穿针引线,把每个篇章的内容都串起来,这里就先不占用大家的前言篇章。
那话归正题,我们今天来看一下关于 Redis 的内存回收机制。
正文
内存回收
Reids 所有的数据都是存储在内存中的,在某些情况下需要对占用的内存空间进行回收。内存回收主要分为两类,一类是 key 过期,一类是内存使用达到上限(max_memory)触发内存淘汰。
过期策略
要实现 key 过期,我们有几种思路。
定时过期(主动淘汰)
每个设置过期时间的 key 都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的 CPU 资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
惰性过期(被动淘汰)
只有当访问一个 key 时,才会判断该 key 是否已过期,过期则清除。该策略可以最大化地节省 CPU 资源,却对内存非常不友好。极端情况可能出现大量的过期 key 没有再次被访问,从而不会被清除,占用大量内存。
例如 String,在 getCommand 里面会调用 expireIfNeeded
server.c expireIfNeeded(redisDb *db, robj *key)
第二种情况,每次写入 key 时,发现内存不够,调用 activeExpireCycle 释放一部分内存。
expire.c activeExpireCycle(int type)
定期过期
源码:server.h
typedef struct redisDb {
dict *dict; /* 所有的键值对 */
dict *expires; /* 设置了过期时间的键值对 */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
每隔一定的时间,会扫描一定数量的数据库的 expires 字典中一定数量的 key,并清除其中已过期的 key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得 CPU 和内存资源达到最优的平衡效果。
Redis 中同时使用了惰性过期和定期过期两种过期策略。
如果都不过期,Redis 内存满了怎么办?
淘汰策略
Redis 的内存淘汰策略,是指当内存使用达到最大内存极限时,需要使用淘汰算法来决定清理掉哪些数据,以保证新数据的存入。
最大内存设置
redis.conf 参数配置:
#maxmemory
如果不设置 maxmemory 或者设置为 0,64 位系统不限制内存,32 位系统最多使用 3GB 内存。
动态修改:
redis> config set maxmemory 2GB
到达最大内存以后怎么办?
淘汰策略
https://redis.io/topics/lru-cache
redis.conf
#maxmemory-policy noeviction
#volatile-lru -> Evict using approximated LRU among the keys with an expire set.
#allkeys-lru -> Evict any key using approximated LRU.
#volatile-lfu -> Evict using approximated LFU among the keys with an expire set.
#allkeys-lfu -> Evict any key using approximated LFU.
#volatile-random -> Remove a random key among the ones with an expire set.
#allkeys-random -> Remove a random key, any key.
#volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
#noeviction -> Don't evict anything, just return an error on write operations.
先从算法来看:
LRU,Least Recently Used:最近最少使用。判断最近被使用的时间,目前最远的数据优先被淘汰。
LFU,Least Frequently Used,最不常用,4.0 版本新增。
random,随机删除。
| 策略 | 含义 |
|---|---|
| volatile-lru | 根据 LRU 算法删除设置了超时属性(expire)的键,直到腾出足够内存为止。如果没有可删除的键对象,回退到 noeviction 策略。 |
| allkeys-lru | 根据 LRU 算法删除键,不管数据有没有设置超时属性,直到腾出足够内存为止。 |
| volatile-lfu | 在带有过期时间的键中选择最不常用的。 |
| allkeys-lfu | 在所有的键中选择最不常用的,不管数据有没有设置超时属性。 |
| volatile-random | 在带有过期时间的键中随机选择。 |
| allkeys-random | 随机删除所有键,直到腾出足够内存为止。 |
| volatile-ttl | 根据键值对象的 ttl 属性,删除最近将要过期数据。如果没有,回退到 noeviction 策略。 |
| noeviction | 默认策略,不会删除任何数据,拒绝所有写入操作并返回客户端错误信息(error)OOMcommand not allowed when used memory,此时 Redis 只响应读操作。 |
如果没有符合前提条件的 key 被淘汰,那么 volatile-lru、volatile-random 、
volatile-ttl 相当于 noeviction(不做内存回收)。
动态修改淘汰策略:
redis> config set maxmemory-policy volatile-lru
建议使用 volatile-lru,在保证正常服务的情况下,优先删除最近最少使用的 key。
LRU 淘汰原理
思考:基于一个数据结构做缓存,怎么实现 LRU——最长时间不被访问的元素在超过容量时删除?
问题:如果基于传统 LRU 算法实现 Redis LRU 会有什么问题?
需要额外的数据结构存储,消耗内存。
Redis LRU 对传统的 LRU 算法进行了改良,通过随机采样来调整算法的精度。
如果淘汰策略是 LRU,则根据配置的采样值 maxmemory_samples(默认是 5 个),随机从数据库中选择 m 个 key, 淘汰其中热度最低的 key 对应的缓存数据。所以采样参数 m 配置的数值越大, 就越能精确的查找到待淘汰的缓存数据,但是也消耗更多的 CPU 计算,执行效率降低。
问题:如何找出热度最低的数据?
Redis 中所有对象结构都有一个 lru 字段, 且使用了 unsigned 的低 24 位,这个字段用来记录对象的热度。对象被创建时会记录 lru 值。在被访问的时候也会更新 lru 的值。但是不是获取系统当前的时间戳,而是设置为全局变量 server.lruclock 的值。
源码:server.h
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
*LFU data (least significant 8 bits frequency
*and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
server.lruclock 的值怎么来的?
Redis 中 有 个 定 时 处 理 的 函 数 serverCron , 默 认 每 100 毫 秒 调 用 函 数 updateCachedTime 更新一次全局变量的 server.lruclock 的值,它记录的是当前 unix 时间戳。
源码:server.c
void updateCachedTime(void) {
time_t unixtime = time(NULL);
atomicSet(server.unixtime,unixtime);
server.mstime = mstime();
struct tm tm;
localtime_r(&server.unixtime,&tm);
server.daylight_active = tm.tm_isdst;
}
问题:为什么不获取精确的时间而是放在全局变量中?不会有延迟的问题吗?
这样函数 lookupKey 中更新数据的 lru 热度值时,就不用每次调用系统函数 time,可以提高执行效率。
OK,当对象里面已经有了 LRU 字段的值,就可以评估对象的热度了。
函数 estimateObjectIdleTime 评估指定对象的 lru 热度,思想就是对象的 lru 值和全局的 server.lruclock 的差值越大(越久没有得到更新), 该对象热度越低。
源码 evict.c
/* Given an object returns the min number of milliseconds the object was never
*requested, using an approximated LRU algorithm. */
unsigned long long estimateObjectIdleTime(robj *o) {
unsigned long long lruclock = LRU_CLOCK();
if (lruclock >= o->lru) {
return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;
} else {
return (lruclock + (LRU_CLOCK_MAX - o->lru)) *
LRU_CLOCK_RESOLUTION;
}
}
server.lruclock 只有 24 位,按秒为单位来表示才能存储 194 天。当超过 24bit 能表示的最大时间的时候,它会从头开始计算。
server.h
#define LRU_CLOCK_MAX ((1</* Max value of obj->lru */
在这种情况下,可能会出现对象的 lru 大于 server.lruclock 的情况,如果这种情况出现那么就两个相加而不是相减来求最久的 key。
为什么不用常规的哈希表+双向链表的方式实现?需要额外的数据结构,消耗资源。
而 Redis LRU 算法在 sample 为 10 的情况下,已经能接近传统 LRU 算法了。
https://redis.io/topics/lru-cache

问题:除了消耗资源之外,传统 LRU 还有什么问题?
如图,假设 A 在 10 秒内被访问了 5 次,而 B 在 10 秒内被访问了 3 次。因为 B 最后一次被访问的时间比 A 要晚,在同等的情况下,A 反而先被回收。
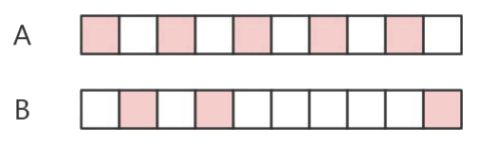
问题:要实现基于访问频率的淘汰机制,怎么做?
LFU
server.h
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
/* LRU time (relative to global lru_clock) or
*LFU data (least significant 8 bits frequency
*and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
当这 24 bits 用作 LFU 时,其被分为两部分:
高16 位用来记录访问时间(单位为分钟,ldt,last decrement time)低 8 位用来记录访问频率,简称 counter(logc,logistic counter)
counter 是用基于概率的对数计数器实现的,8 位可以表示百万次的访问频率。
对象被读写的时候,lfu 的值会被更新。
db.c——lookupKey
void updateLFU(robj *val) {
unsigned long counter = LFUDecrAndReturn(val);
counter = LFULogIncr(counter);
val->lru = (LFUGetTimeInMinutes()<<8) | counter;
}
增长的速率由,lfu-log-factor 越大,counter 增长的越慢 redis.conf 配置文件
# lfu-log-factor 10
如果计数器只会递增不会递减,也不能体现对象的热度。没有被访问的时候,计数器怎么递减呢?
减少的值由衰减因子 lfu-decay-time(分钟)来控制,如果值是 1 的话,N 分钟没有访问就要减少 N。
redis.conf 配置文件
# lfu-decay-time 1
By the way
有问题?可以给我留言或私聊
有收获?那就顺手点个赞呗~
当然,也可以到我的公众号下「6曦轩」,
回复“学习”,即可领取一份
【Java工程师进阶架构师的视频教程】~
回复“面试”,可以获得:
【本人呕心沥血整理的 Java 面试题】
回复“MySQL脑图”,可以获得
【MySQL 知识点梳理高清脑图】
还有【阿里云】【腾讯云】的购买优惠噢~具体请联系我
曦轩我是科班出身的程序员,php,Android以及硬件方面都做过,不过最后还是选择专注于做 Java,所以有啥问题可以到公众号提问讨论(技术情感倾诉都可以哈哈哈),看到的话会尽快回复,希望可以跟大家共同学习进步,关于服务端架构,Java 核心知识解析,职业生涯,面试总结等文章会不定期坚持推送输出,欢迎大家关注~~~
