FD.io/VPP — Overview
目录
文章目录
- 目录
- FD.io
- VPP
-
- 矢量处理和标量处理
- I-cache 抖动
- VPP 特色
- VPP 架构:Packet Processing Graph
- Packet Processing Graph 的处理流程
FD.io
官网:https://fd.io
FD.io(Fast data – Input/Output)是 Linux 基金会下属的一个开源项目,成立于 2016 年 2 月 11 日。FD.io 基于 DPDK 并逐渐演化,是许多数据面(Data Plane)项目和库的一个集合,在通用硬件平台上提供了具有灵活性、可扩展、组件化等特点的高性能 I/O 服务框架,用以迎接下一个网络和存储浪潮。
简而言之,FD.io 是一个软件定义基础设施的开发平台,帮助开发者简易的实现基于软件的报文处理创新方案,包括设计、开发高吞吐量、低延时和有效利用资源的应用程序。并为这些创新型应用程序屏蔽了 CPU 架构(x86、ARM 和 PowerPC)以及运行环境(裸机、虚拟机和容器)的差异。
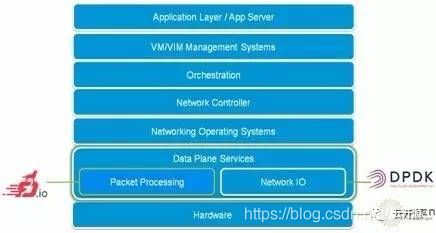
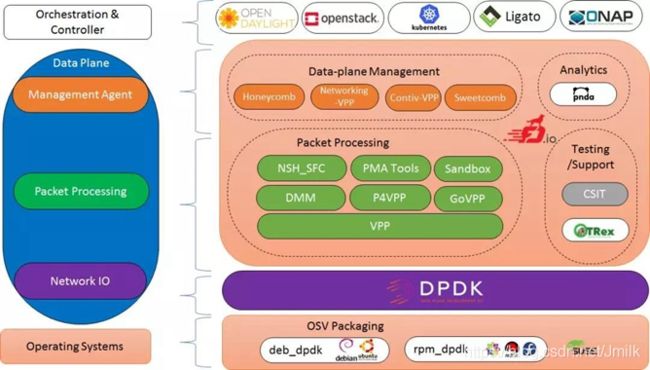
FD.io 的一个关键项目是由 Cisco 捐赠的已商用的 VPP(Vector Packet Processing,矢量报文处理)库,并充分利用 DPDK 特性孵化了多个项目和库,包括:NSH_SFC、Honeycomb 和 ONE。此外,FD.io 还积极推进与其他关键的开源项目进行集成,以支持 NFV 和 SDN。目前已经集成的开源项目包括:K8s、OpenStack、ONAP 和 OpenDaylight。
FD.io 的网络生态矩阵如下图所示:
VPP
官网:https://wiki.fd.io/view/VPP
VPP(Vector Packet Processing,矢量报文处理)是一个高度模块化和可扩展的软件框架,新开发的功能模块很容易被集成到 VPP,而不影响 VPP 底层的代码框架。这就给了开发者很大的灵活性,用于创建网络数据面应用程序。
VPP 平台可用于构建任何类型的数据包处理应用程序。例如:负载均衡器,防火墙,IDS 或主机协议栈的基础架构。此外,还可以创建应用程序的组合,例如:向 vSwitch 添加负载平衡功能。并且 VPP 在用户空间运行,这意味着 VPP 的插件不需要更改 Linux Kernel 的代码。
在 DPDK 的轮询模式驱动程序(PMD)和环形缓冲区库的支持下,VPP 把重点放在优化软件和硬件接口上,旨在通过减少数据流/转发表缓存的未命中数来增加转发平面吞吐量,同时使用并行方式替换标准串行数据报文处理。
VPP 充分利用了通用处理器优化技术,包括矢量指令(e.g. Intel SSE, AVX)以及 I/O 和 CPU 缓存间的直接交互(e.g. Intel DDIO),以达到最好的报文处理性能。利用这些优化技术的好处是:使用最少的 CPU 核心指令和时钟周期来处理每个报文。在最新的 Intel Xeon-SP 处理器上,可以达到 Tbps 的处理性能。
矢量处理和标量处理
所谓的 “矢量” 是与传统的 “标量” 报文处理相对而言的,矢量是一个自然科学术语,是一种既有大小又有方向的量,又称为向量。在计算机科学中,矢量图可以无限放大永不变形。
标量报文处理方式:是人类常用的逻辑思维方式,即:报文是按照到达先后顺序来处理,第一个报文处理完,再处理第二个,依次类推。更为传统的方式还需要处理中断,并遍历调用栈(e.g. A calls B calls C….return return return…), 然后从中断返回,函数会频繁嵌套调用。最后,该过程执行以下三种操作之一:
- 不作处理
- 丢弃或重写
- 转发报文
由此可见,传统的标量报文处理方式有如下缺陷:
- I-cache(CPU 指令缓存)抖动,Cache 时间局限性和空间局限性特点。
- I-cache misses,每个报文都会产生一组相同的 I-cache 未命中。
- 除了提供更大的 Cache 空间之外,没有解决方法。
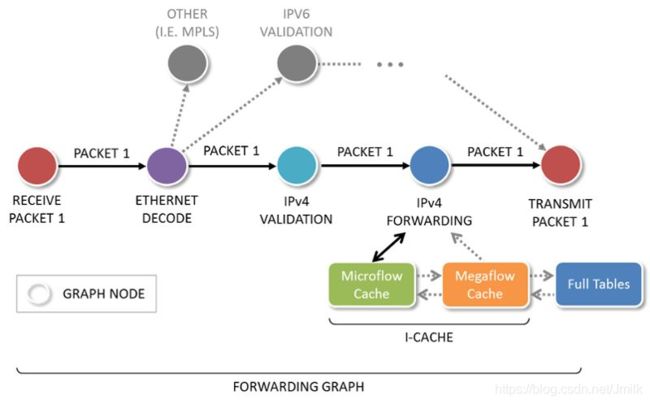
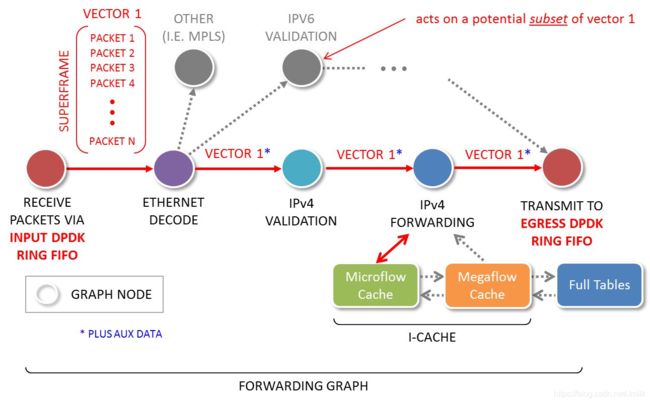
矢量报文处理方式:则是一次处理多个报文,也相当于一次处理一个报文数组。把一批底层硬件队列 Rx ring 收到的报文,组成一个报文数组,称为 Packet Vector(矢量报文),助于 Packet Processing Graph(报文处理图)来组织处理流程。

Graph Node(图节点)把整个处理流程分解为一个个先后连接的 Service Node(服务节点)。Packet vector 首先被第一个 Graph Node 的任务处理,然后依次被第二个 Graph Node 的任务处理,依次类推,如下图所示:
矢量报文处理利用了数据报文处理的时间局部性特点,将一批报文分为一组,如果 I-cache 命中,则这一批报文都命中;否则这一批报文都未命中。而未命中时,则通过 Packet Vector 中的第一个报文 packet-1 为 I-cache 进行预热,然后可以针对矢量报文中后续数据包重复执行缓存中所得到的指令。如此的,Packet Vector 中剩下报文的处理性能可以直接达到极限,从而在整个报文分组中分摊一个报文的高速缓存未命中时间,使单个报文的处理开销显著降低。
由此可见,矢量报文处理解决了标量报文处理的主要性能缺陷,并有具有如下优点:
- 解决了 I-cache 抖动问题。
- 对 I-cache 进行预热缓解了读时延问题,高性能并且更加稳定。
I-cache 抖动
短时间存活的数据流或高熵数据报文字段(那些在数据包之间具有不同值的数据包)都会使 I-cache(CPU 指令缓存)失效。
当计算设备启动时,I-cache 是空的,称呼为缓存是 “冷” 的,此时所有冷缓存查询都会失败。未命中的数据报文随后用于填充缓存,称呼该动作为缓存 “预热”,称呼此时的 I-cache 为缓存是 “热” 的,此时热缓存的查询会有适当数量的 “命中”。缓存可以使用简单的先进先出(FIFO),或者最近最少使用(LRU)或最不常用(LFU)算法决定是否用新的缓存替换旧的缓存。这个替换策略很重要,因为高速缓存流失可能是由于不良的替换算法造成的。然而,更可能的原因是那些讨厌的短时间存活的数据流,每次新添加短时间存活的数据流缓存都会导致后续查询 miss,并且可能会替换缓存中的长期数据流缓存。I-cache 缓存中的有用的数据不断被替换,这一现象称之为 “缓存抖动”。
显然的,I-cache 缓存抖动会导致数据报文处理效率的显著降低。同时,根据数据报文处理的时间局部性和空间局部性原理,我们知道在短时间内采样的数据报文分组它们本质上相似,即使不相同,相似性也很强。具有此类属性的数据报文将重用相同的资源,并将访问相同(缓存)的内存位置。VPP 根据该特性,通过防止 I-cache 缓存抖动可以显著提高数据报文的处理效率。
VPP 特色
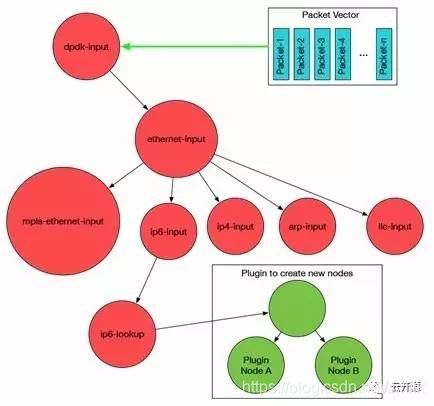
插件化:VPP 平台的 Graph Node 组织方式,使用户可以根据需求,通过 Plugin 的方式插入新的图节点或者重新排列图节点,扩展非常方便,也不会影响原有核心处理流程。
丰富的基础功能:
-
IPv4/v6:
- 14+ MPPS, single core
- Multimillion entry FIBs
- Input Checks: Source RPF, TTL expiration, header checksum, L2 length < IP length, ARP resolution/snooping, ARP proxy
- Thousands of VRFs: controlled cross-VRF lookups
- Multipath - ECMP and Unequal Cost
- Multiple million Classifiers - Arbitrary N-tuple
- VLAN support - Single/Double tag
-
IPv4:
- GRE、MPLS-GRE、NSH-GRE
- VXLAN
- IPSEC
- DHCP client/proxy。
-
IPV6:
- Neighbor discovery
- Router Advertisement
- DHCPv6 Proxy
- L2TPv3
- Segment Routing
- MAP/LW46 – IPv4aas
- iOAM
-
MPLS:
- MPLS-o-Ethernet – Deep label stacks supported
-
L2:
- VLAN Support Single/Double tag
- L2 forwarding with EFP/BridgeDomain concepts
- VTR – push/pop/Translate (1:1,1:2, 2:1,2:2)
- Mac Learning – default limit of 50k addresses
- Bridging – Split-horizon group support/EFP Filtering
- Proxy Arp
- Arp termination
- IRB – BVI Support with RouterMac assignment
- Flooding
- Input ACLs
- Interface cross-connect
VPP 架构:Packet Processing Graph
通过上述内容我们可以体会到,VPP 包括一个软件框架和一系列根据 Packet Processing Graph 组织的 Graph Node。其中,软件框架包含了基本的数据结构、定时器、驱动程序、在 Graph Node 间分配 CPU 时间片的调度器、性能调优工具(e.g. 计数器、抓包工具)。
VPP 的软件框架采用了 Plugin 架构,插件与 VPP 内建的模块被同等对待,从而有利于快速灵活地开发新功能。因此,插件架构使开发者能够充分利用现有模块快速开发出新功能。实际上,插件的本质就是实现了某一特定功能的 Graph Node,但也可以是一个驱动程序或者 CLI。插件能被插入到 VPP 的 Packet Processing Graph 中的任意位置。
Packet Processing Graph 的处理流程

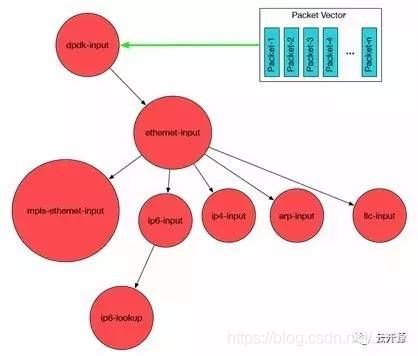
如上图,VPP 首先从 Input Node(输入节点)轮询(或中断)以太网接口的接收队列,获取批量报文。接着把这些报文按照下一个 Graph Node 的功能组成一个 Packet Vector 或者帧(Frame)。比如:Input Node 收集所有 IPv6 的报文并把它们传递给 ip6-input Node。
当 ip6-input Node 被调度时,它取出第一个报文 packet-1,利用双循环(Dual-Loop)或四循环(Quad-Loop)以及通过预取报文到 CPU 缓存技术来处理报文,可以有效减少缓存未命中数,以达到最优性能。当 ip6-input 节点处理完当前帧的所有报文后,把报文传递到后续不同的节点。比如:如果某报文校验失败,就被传送到 error-drop 节点。而正常报文被传送到 ip6-lookup 节点。packet-1 依次通过不同的图形节点,直到它们被 interface-output 节点发送出去。
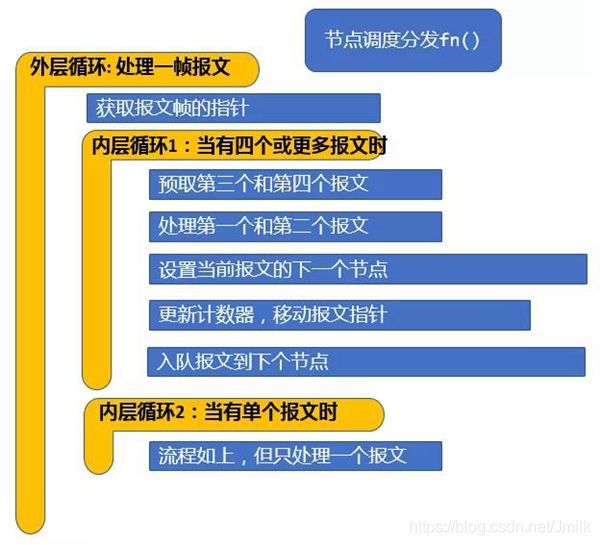
每一个 Graph Node 利用一帧报文作为输入和输出的最小处理单位进行处理,有几个好处:
-
从软件工程的角度看,每一个图形节点是独立和自治的。
-
从性能的角度看,主要的好处是可以优化 CPU 指令缓存(I-cache)的使用。当前帧的第一个报文加载当前节点的指令到指令缓存,当前帧的后续报文就可以 “免费” 使用指令缓存。这里,VPP 充分利用了 CPU 的矢量结构,使报文内存加载和报文处理交织进行,达到更有效地利用 CPU 处理流水线。
-
VPP 也充分利用了 CPU 的预测执行功能来达到更好的性能。从预测重用报文间的转发对象(比如邻接表和路由查找表),以及预先加载报文内容到 CPU 的本地数据缓存(d-cache)供下一次循环使用,这些有效使用计算硬件的技术,使得 VPP 可以利用更细粒度的并行性。
VPP 的矢量图报文处理的特性,使它成为一个松耦合、高度一致的软件架构。每一个 Graph Node 利用一帧报文作为输入和输出的最小处理单位,这就提供了松耦合的特性。通用功能被组合到每个 Graph Node 中,这就提供了高度一致的架构。
在矢量图中的节点是可替代的,这个特性和 VPP 支持动态加载插件节点相结合时,新功能能被快速开发,而不需要新建和编译一个定制的代码版本。