JVM学习总结——JVM优化(jvm参数)
问题:
最近接触一个项目,项目灰度测试时发现3次下单2次超时。这就比较恐怖了,业务方之间反馈出来了,通过排查日志发现一个组装参数的方法耗时大概300~500ms,现在的RPC接口肯定不能接受。
排查方式:
通过观察Young GC 发现一次300多ms,时间也正好吻合。
机器配置 2C4G
每次FullGC后,内存都能回到某一个值可以排除内存泄漏的情况
解决方式:
对垃圾回收器进行参数调优,调优过程发现程序处理问题的复杂度不同参数也需要微调。
最主要的是当程序足够复杂,JVM参数调优是不明显或者没有改观。
JVM参数给出:
-Xms2048m -Xmx2048m -XX:+UseG1GC -XX:+UnlockExperimentalVMOptions -XX:MaxGCPauseMillis=50 -XX:ParallelGCThreads=2 -XX:CICompilerCount=2 -XX:ConcGCThreads=1 -XX:InitiatingHeapOccupancyPercent=30 -XX:G1MaxNewSizePercent=50 -XX:G1HeapRegionSize=4m -XX:+UseCompressedOops -XX:CompressedClassSpaceSize=128m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -XX:+AlwaysPreTouch -XX:+UnlockDiagnosticVMOptions
首先添加GC日志
XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintHeapAtGC -XX:+PrintGCDateStamps -Xloggc:gc.log
-
-XX:+PrintGC 输出简要GC日志
-
-XX:+PrintGCDetails 输出详细GC日志
-
-Xloggc:gc.log 输出GC日志到文件
-
-XX:+PrintGCTimeStamps 输出GC的时间戳(以JVM启动到当期的总时长的时间戳形式)
-
-XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
-
-XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
-
-verbose:gc
-
-XX:+PrintReferenceGC 打印年轻代各个引用的数量以及时长跟踪软引用、弱引用、虚引用和Finallize队列。
-
-XX:+PrintGCApplicationConcurrentTime 打印应用程序的执行时间 -XX:+PrintGCApplicationStoppedTime 打印应用由于GC而产生的停顿时间
更具GC日志选择添加和调优
-XX:CompileThreshold=100 -XX:-UseCounterDecay -XX:+OptimizeStringConcat -XX:+UseStringCache
通常根据 -XX:InitiatingHeapOccupancyPercent 和-XX:G1MaxNewSizePercent、-XX:G1HeapRegionSize=4m 调优
通过 -XX:CompressedClassSpaceSize=128m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m 设置方法区大小
-Xms2048m -Xmx2048m 初始化堆大小 调整 同最大堆大小 可提高性能,,防止使用时再申请
G1触发了Full GC情况?
1.并发模式失败
G1启动标记周期,但在Mixed GC之前,老年代就被填满,这时候G1会放弃标记周期。这种情形下,需要增加堆大小,或者调整周期或增加线程数-XX:ConcGCThreads等。
2.晋升失败
G1在进行GC的时候没有足够的内存供存活对象或晋升对象使用,由此触发了Full GC。可以在日志中看到(to-space exhausted)或者(to-space overflow)。
解决这种问题的方式是:
A,增加 -XX:G1ReservePercent 选项的值(并相应增加总的堆大小),为“目标空间”增加预留内存量。
B,通过减少 -XX:InitiatingHeapOccupancyPercent 提前启动标记周期。
C,也可以通过增加 -XX:ConcGCThreads 选项的值来增加并行标记线程的数目。
3.巨型对象分配失败
当巨型对象找不到合适的空间进行分配时,就会启动Full GC,来释放空间。这种情况下可以增加内存或者增大-XX:G1HeapRegionSize
jvm参数分类
根据jvm参数开头可以区分参数类型,共三类:“-”、“-X”、“-XX”,
(1)标准参数(-):所有的JVM实现都必须实现这些参数的功能,而且向后兼容;
例子:-verbose:class,-verbose:gc,-verbose:jni……
(2)非标准参数(-X):默认jvm实现这些参数的功能,但是并不保证所有jvm实现都满足,且不保证向后兼容;
例子:Xms20m,-Xmx20m,-Xmn20m,-Xss128k……
(3)非Stable参数(-XX):此类参数各个jvm实现会有所不同,将来可能会随时取消,需要慎重使用;
例子:-XX:+PrintGCDetails,-XX:-UseParallelGC,-XX:+PrintGCTimeStamps……
-XX:+或-某个属性值,+表开启,-表关闭
效果:
截止到目前从平均300多ms降到了平均31.4,目前计算得到最近一次Young GC耗时 24ms
总结:
没事别瞎优化,有一次 XX:G1MaxNewSizePercent 参数调整到30,项目直接启动失败。
什么时候需要优化,比如出现上述问题。
如果需要优化首先足够了解项目的功能和使用场景。
参数详细讲解
参考地址:https://www.oracle.com/java/technologies/javase/vmoptions-jsp.html, https://www.oracle.com/cn/technical-resources/articles/java/g1gc.html
设置堆栈大小
-Xms2048m -Xmx2048m
指定回收器
-XX:+UseG1GC
#年轻代大小
-XX:+G1YoungGenSize=512m
来配置老年代和新生代的比例,默认为2,即比例为2:1;(避免使用 -Xmn 选项或 -XX:NewRatio 等其他相关选项显式设置年轻代大小。固定年轻代的大小会覆盖暂停时间目标。)
-XX:NewRatio=2
则可以配置Eden与Survivor的比例,默认为8。
-XX:SurvivorRatio=8
解锁实验性虚拟机标志
-XX:+UnlockExperimentalVMOptions
为所需的最长暂停时间设置目标值
-XX:MaxGCPauseMillis=50
#暂停间隔目标
-XX:GCPauseIntervalMillis =200
并行回收线程数以及使用的标记线程
-XX:ParallelGCThreads=2 -XX:ConcGCThreads=2
使用编译线程数
-XX:CICompilerCount=2
通过JIT编译器,将方法编译成机器码的触发阀值,可以理解为调用方法的次数,例如调1000次,将方法编译为机器码
-XX:CompileThreshold=100
关闭热度衰减,让方法计数器统计方法调用的绝对次数,这样,只要系统运行时间足够长,绝大部分方法都会被编译成本地代码
-XX:-UseCounterDecay
编译后存放空间大小
-XX:CompressedClassSpaceSize=128m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m
设置触发标记周期的 Java 堆占用率阈值
-XX:InitiatingHeapOccupancyPercent=30
设置作为空闲空间的预留内存百分比,以降低目标空间溢出的风险
-XX:G1ReservePercent=20
设置要用作年轻代大小最小值的堆百分比
-XX:G1MaxNewSizePercent=50
区大小如果巨型分配导致连续的并发周期,并且此类分配导致老年代碎片化,请增加 -XX:G1HeapRegionSize,
-XX:G1HeapRegionSize=4m
元空间分配情况
-XX:+UseCompressedOops
JAVA进程启动的时候,虽然我们可以为JVM指定合适的内存大小,但是这些内存操作系统并没有真正的分配给JVM,而是等JVM访问这些内存的时候,才真正分配,这样会造成以下问题。
GC的时候,新生代的对象要晋升到老年代的时候,需要内存,这个时候操作系统才真正分配内存,这样就会加大young gc的停顿时间
-XX:+AlwaysPreTouch
字符串缓存
-XX:+UseStringCache
优化字符串连接
-XX:+OptimizeStringConcat
Xmx感知docker的memory limit 原生内存信息打印
-XX:+UnlockDiagnosticVMOptions
-XX:+UseCGroupMemoryLimitForHeap
-XX:+PrintFlagsFinal
线程本地分配缓冲区
-XX:+UseTLAB
打印TLAB相关分配信息
-XX:+PrintTLAB
设置TLAB大小
-XX:TLABSize
自动调整TLAB大小
-XX:+ResizeTLAB
参数了解完了,为什么优化?怎么优化?优化到什么地步?这些问题还没有解决。
下边谈一谈
为什么优化?
不管YGC还是FGC,都会造成一定程度的程序卡顿(即Stop The World问题:GC线程开始工作,其他工作线程被挂起),导致客户端调用超时。
怎么优化?
需要了解一些概念你自然就知道优化方向了。
内存泄漏(Memory Leak):是指程序中己动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。(百度百科)
举个例子:不断new Thread();每个线程让它等待。
/**
* Thread.sleep 和 object.wait 都可以使线程等待
* sleep 期间不会释对象放锁
* object.wait会立即释放对象锁
*
* 无限的object.wait 需要使用 object.notify
* */
public class WaitNotifyThread {
final static Object object=new Object();
public static class TreadOne extends Thread{
@Override
public void run() {
// synchronized (object){
System.out.println(System.currentTimeMillis()+": treadOne start !!!");
try {
System.out.println(System.currentTimeMillis()+": treadOne wait for object !!!");
Thread.sleep(10000L);//sleep 期间不会释放锁
object.wait();//会立刻释放锁
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(System.currentTimeMillis()+" treadOne end !!!");
// }
}
}
public static class TreadTwo extends Thread{
@Override
public void run() {
synchronized (object){
System.out.println(System.currentTimeMillis()+": treadTwo start !!!");
try {
System.out.println(System.currentTimeMillis()+": treadTwo wait for object !!!");
Thread.sleep(1000L);
System.out.println(System.currentTimeMillis()+": treadTwo notify !!!");
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(System.currentTimeMillis()+" treadTwo end !!!");
}
}
}
public static void main(String[] args) {
for(int i=0;i<100000;i++)
new TreadOne().start();
}
}
结果:
1589594553394: treadOne start !!!
1589594553397: treadOne start !!!
1589594553397: treadOne wait for object !!!
1589594553397: treadOne start !!!
java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:714)
at cn.ruyipay.mutilthread.WaitNotifyThread.main(WaitNotifyThread.java:46)
内存溢出:内存溢出(Out Of Memory,简称OOM)是指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于能提供的最大内存
内存泄漏后无法及时回收或者无法回收导致内存溢出
内存溢出的原因:内存大对象过多并且都是强引用 JVM无法回收
循环创建对象(如上)
JVM参数的内存值设置过小等等
每次FGC后,内存都能回到某一个值可以排除内存泄漏的情况
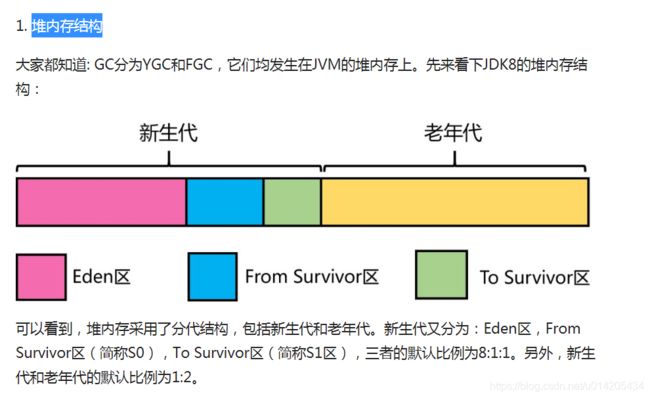
1. YGC是什么时候触发的?
new 出来的对象(除大对象外)直接在年轻代中的Eden区进行分配,如果Eden区域没有足够的空间,那么就会触发YGC(Minor GC),YGC处理的区域只有新生代。YGC后只有极少数的对象能存活下来,这些对象根据年轻代回收器中的算法进行处理。
2. FGC又是什么时候触发的?
下面4种情况,对象会进入到老年代中:
YGC时,To Survivor区不足以存放存活的对象,对象会直接进入到老年代。
经过多次YGC后,如果存活对象的年龄达到了设定阈值,则会晋升到老年代中。
动态年龄判定规则,To Survivor区中相同年龄的对象,如果其大小之和占到了 To Survivor区一半以上的空间,那么大于此年龄的对象会直接进入老年代,而不需要达到默认的分代年龄。
大对象:由-XX:PretenureSizeThreshold启动参数控制,若对象大小大于此值,就会绕过新生代, 直接在老年代中分配。
当晋升到老年代的对象大于了老年代的剩余空间时,就会触发FGC(Major GC),FGC处理的区域同时包括新生代和老年代。除此之外,还有以下4种情况也会触发FGC:
老年代的内存使用率达到了一定阈值(可通过参数调整),直接触发FGC。
空间分配担保:在YGC之前,会先检查老年代最大可用的连续空间是否大于新生代所有对象的总空间。如果小于,说明YGC是不安全的,则会查看参数 HandlePromotionFailure 是否被设置成了允许担保失败,如果不允许则直接触发Full GC;如果允许,那么会进一步检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果小于也会触发 Full GC。
Metaspace(元空间)在空间不足时会进行扩容,当扩容到了-XX:MetaspaceSize 参数的指定值时,也会触发FGC。
System.gc() 或者Runtime.gc() 被显式调用时,触发FGC
优化到什么地步?
FGC过于频繁:FGC通常是比较慢系统几天才执行一次,对系统的影响还能接受。
YGC耗时过长:YGC的总耗时在几十毫秒是比较正常的(这个要根据项目中功能的复杂度决定,如果项目过于复杂建议拆分尤其是RPC接口)