python3爬虫(6)--使用Beautiful Soup解析数据
1、基础概念
前言:
Beautiful Soup 就是Python的一个HTML或XML的解析库,可以用它来方便地从网页中提取数据。
Beautiful Soup 已成为和lxml、html6lib一样出色的Python解释器,为用尸灵活地提供不同的解析策略或强劲的速度。
Beautiful Soup 自动将输入文档转换为Unicode编码,输出文档转换为UTF-8编码。
Beautiful Soup 的HTML和XML解析器是依赖于1xml库,所以需要确保lxml安装:pip install lxml ,常见错误提示:bs4 FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?卸载lxml:pip uninstall lxml ,再重装:pip install lxml,不行就重启pycharm.
Beautiful Soup 模块使用前需要确保安装,目前最新版本是4.x版本:pip install beautifulsoup4
Beautiful Soup 在解析数据时通常使用bs4,引入:from bs4 import BeautifulSoup
Beautiful Soup在解析时实际上依赖解析器,它除了支持Python标准库中的HTL解析器外,还支持一些第三方解析器(比如lxml)。
解析器:
Beautiful Soup在解析时实际上依赖解析器,它除了支持Python标准库中的HTL解析器外,还支持一些第三方解析器(比如lxml)。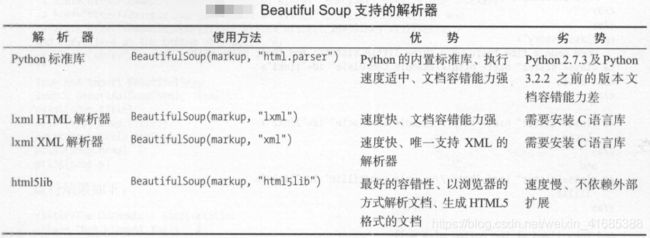
解析器选择及使用方法:
通过以上对比可以看出,lxml解析器有解析HTML和XML的功能,而且速度快,容错能力强,通常使用lxml。
使用时,在初始化Beautiful Soup时把第二个参数改为1xml即可:
from bs4 import BeautifulSoup
soup=BeautifulSoup('
Hello
,‘1xml')print(soup.p.string)
重点使用:
2、节点选择器
'''***********************************************节点选择器*********************************************************'''
from bs4 import BeautifulSoup
html = '''
密尔沃基 雄鹿nba
6
18 - 4
胜 6
119.5
nba
'''
soup=BeautifulSoup(html,'lxml') #初始化为BeautifulSoup的解析形式
'''*********************************节点选择器21个知识点*************************'''
#标准化
r1=soup.prettify()#把要解析的字符串以标准的缩进格式输出,同时有节点缺失或错误也可以自行更正
print("r1:",r1)
#节点简单定位
r2=soup.div.td.a #定位到指定节点
print(type(r2)) #输出:
print("r2",r2) #输出:密尔沃基 雄鹿nba
#获取文本或者节点名称
r3=soup.tr.td.string #调用string属性,获取指定标签里面的文本
print("r3",r3) #输出:6。注意:有多个td节点,默认只选择第一个,后面的被忽略。
r4=soup.tr.td.get_text() #用.get_text(),获取指定标签里面的文本
print("r4:",r4) #输出:6
r5=soup.tr.td.name #用.name获取节点的名称
print('r5',r5) #输出:td
#获取属性值
r6=soup.td.a['href'] #获取某个属性的值,简写式
print("r6",r6) #输出:bucks
r7=soup.td.a.attrs #以字典形式输出某个节点的所有属性-值
print('r7',r7)#{'href': 'bucks', 'class': ['ng-binding'], 'target': '_parent', 'href1': '/teams/#!/bucks'}
r8=soup.td.a.attrs['href'] #获取某个属性的值,字典索引式
print('r8',r8) # bucks
#获取子节点或子孙节点
r9=soup.div.td.contents #获取td的直接子节点的列表,调用contents
print('r9',r9) #['\n', 密尔沃基 雄鹿nba, '\n']
r10=soup.div.td.children #获取td的直接子节点的列表,调用children
print('r10',r10) #返回生成器类型:
for i, child in enumerate(soup.div.td.children):
print(i, child)#输出:
'''
0
1 密尔沃基 雄鹿nba
2
'''
r11=soup.div.td.descendants #要得到所有的子孙节点的话,可以调用descendants属性:
print("r11",r11) #返回生成器类型:
for i01, child01 in enumerate(soup.div.td.descendants):
print(i01, child01)#输出:
'''
0
1 密尔沃基 雄鹿nba
2 ngIf: row.clinched
3 密尔沃基 雄鹿
4 nba
5 nba
6
'''
#获取父节点和祖先节点
r12=soup.a.parent #获取某个节点元素的父节点,可以调用parent属性:
print("r12",r12) #输出:....
r13=soup.a.parents #获取所有的祖先节点,可以调用parents属性:
print("r13",r13)#返回生成器类型:
for i, parent in enumerate(soup.a.parents):
print(i, parent) #输出:略
#获取兄弟节点
r14=soup.div.tr.td.next_sibling.next_sibling #获取下面的第2个兄弟节点,很多时候把换行也算为一个节点
print('r14:',r14)#r14: 18 - 4
r15=soup.p.previous_sibling.previous_sibling #获取上面的第2个兄弟节点,很多时候把换行也算为一个节点
print('r15:',r15) #r15: ......
r16=soup.div.tr.td.next_siblings #获取下面的所有兄弟节点
print(type(r16),r16) #
print(list(enumerate(soup.div.tr.td.next_siblings)))#转化为列表元组输出
# 输出:[(0, '\n'), (1, 18 - 4 ), (2, '\n'), (3, 胜 6 ), (4, '\n'), (5, 119.5 ), (6, '\n')]
r17=soup.p.previous_siblings #获取上面的所有兄弟节点
print(type(r17),r17)#
print(list(enumerate(soup.p.previous_siblings)))
# 输出:[(0, '\n'), (1, ......)]
r18=soup.div.tr.td.next_sibling.next_sibling.string #获取文本信息,previous同理
print("r18:",r18) #r18: 18 - 4
r19=list(soup.div.tr.td.next_siblings)[1].string #获取文本信息,previous同理
print('r19:',r19)#r19: 18 - 4
r20=soup.div.tr.td.next_sibling.next_sibling.attrs["class"]#获取属性值,previous同理
print(r20) #['nobr', 'center', 'bold', 'desktop', 'ng-binding']
r21=list(soup.div.tr.td.next_siblings)[1].attrs["class"] #获取获取属性值,previous同理
print('r21:',r21)#r18:['nobr', 'center', 'bold', 'desktop', 'ng-binding']
3、方法选择器
'''*****************************************************方法选择器****************************************************'''
from bs4 import BeautifulSoup
import re
html = '''
密尔沃基 雄鹿nba
6
18 - 4
胜 6
119.5
nba
'''
soup=BeautifulSoup(html,'lxml') #初始化为BeautifulSoup的解析形式
'''****************方法选择器:find_al1()和find()的使用**********************************************'''
#find_al1(name,attrs,recursive,text,limit,**kwargs):查询所有符合条件的元素
# name:通常为节点名;
# attrs:属性约束;
# text:text参数可用来匹配节点的文本,传入的形式可以是字符串,可以是正则表达式对象;
# limit:该参数可以限制得到的结果的数目;
# recursive=False/True:递归,False只会找到该对象的最近后代,True默认值找到全部后代;
# 关键词参数 keyword,自己选择那些具有指定属性的标签
# 注意:多数情况下find_all()和findAll()等价,
# 其中:bsObj.findAll(class='text')#会报错 bsObj.findAll(class_='text')#解决方案
#案例:
ls=[]
for di in soup.find_all(name='td'):
ls.append(di.get_text()) #di.get_text()和di.string差不多,但get_text()更强大
print(ls) #['\n密尔沃基\xa0雄鹿nba\n', '6', '18\xa0-\xa04', '胜 6', '119.5']
ats1=soup.find_all('td',{'class':"nobr center bold ng-binding"})[0].get_text()
ats2=soup.find_all(name='td',attrs={'class':"nobr center bold ng-binding",'href':"href01"})[0].string
print(ats1,ats2) # 6 6
t1=soup.find_all(text=re.compile('(.*)雄鹿(.*)'))
print(t1) #['密尔沃基\xa0雄鹿']
ks1=soup.find_all(href="href01")[0].get_text()
print(ks1) # 6
#find(name,attrs,recursive,text,limit,**kwargs):查询第一个符合条件的元素,方法和find_all()完全一样,只是返回值的范围不一样
#案例
f1=soup.find(name='a',attrs={"href":"bucks","class":"ng-binding"})
print(f1.get_text()) #密尔沃基 雄鹿nba
# 其他:
# find_parents()和find_parent():前者返回所有祖先节点,后者返回直接父节点。
# find_next_siblings()和find_next_sibling():前者返回后面所有的兄弟节点,后者返回后面第一个兄弟节点。
# find_previous_siblings()和find_previous_sibling():前者返回前面所有的兄弟节点,后者返回前面第一个兄弟节点。
# find_al1_next()和find_next():前者返回节点后所有符合条件的节点,后者返回第一个符合条件的节点。
# find_all_previous()和find_previous():前者返回节点后所有符合条件的节点,后者返回第一个符合条件的节点。
Beautiful Soup解析也支持CSS选择器,但是他并没有使用pyquery解析强大,所以这里我们将不再深入。