STL源码剖析——stl_algobase.h
STL标准中没有区分基本算法或复杂算法,单SGI把常用的一些算法定义在
stl_algobase.h中的算法,比较值得学习的是copy(),它“无所不用其极”的改善效率。copy的目的是复制一段元素到指定区间,复制操作最容易想到赋值操作符=,但是有的赋值操作符=是trivial的,可以直接拷贝。关于赋值操作符=是不是trivial的,可以参考“Memberwise copy(深拷贝)与Bitwise copy(浅拷贝)的区别”。
Memberwise copy: 在初始化一个对象期间,基类的构造函数被调用,成员变量被调用,如果它们有构造函数的时候,它们的构造函数被调用,这个过程是一个递归的过程.
Bitwise copy: 原内存拷贝.例子,给定一个对象object,它的类型是class Base.对象object占用10字节的内存,地址从0x0到0x9.如果还有一个对象objectTwo,类型也是class Base.那么执行objectTwo = object;如果使用Bitwise拷贝语义,那么将会拷贝从0x0到0x9的数据到objectTwo的内存地址,.也就是说Bitwise是字节到字节的拷贝.
对于默认的拷贝构造函数不会使用深拷贝,它只是使用浅拷贝.这意味着类的所有的成员是一层深度的拷贝而已。如果你的类或结构体成员中只是包含基本的数据类型例如int, float, char,那么Memberwise copy与Bitwise copy基本是相同的。但如果类中有指针存在,那么你可能会遇到问题。
例如下面的例子:
class A
{
int m1;
double d1;
char* pString;
};如果你创建两个这样的类对象,class A a, b;并且你给a赋值,
a.mi = 6;
a.d1 = 10.123;
a.pString = new char[10];
astrcpy(a.pString, "test");//这里是浅拷贝如果执行b = a;那么会把对象a的每一个成员的值赋值给b的每个成员。
b.m1 = a.m1;
b.d1 = a.d1;
b.pString = a.pString;//现在对象a和b的成员pString都执向相同的内存,删除任一个内存都会析放另一个对象的内存。所以你需要深拷贝,它不是拷贝的内存地址而是拷贝内存地址的内容。一个默认的拷贝构造函数经常执行浅拷贝,只有拥有
自己的拷贝函数才可以实现深拷贝。
补充:
在BitWise Copy Sematics中,因为是按位拷贝的(内存复制),所以那些整数、数组等都会拷贝,新得到的类和原来的类完全一样。但是需要注意一点,如果有指针时,例如
Class Test{
……;
char * p;
};
Test B=A;//A是Test类的对象这时候如果是BitWise Copy,那么A和B中的指针p就会指向同一内存,如果内存在构造函数中释放,那么另一个类的指针将失效。
在一下4中情况,不要BitWise Copy
1、当Class内的成员变量是一个类,这各类声明了Copy Constructor(不是编译器默认合成)时。
2、当Class继承自一个Base Class时,而Base Class存在Copy Constructor时(不是编译器默认合成)。
3、当Class中声明有virtual function时
4、当Class继承自一个继承串链,其中一个或多个virtual Base Class时。
下面是copy调用过程的讲解。
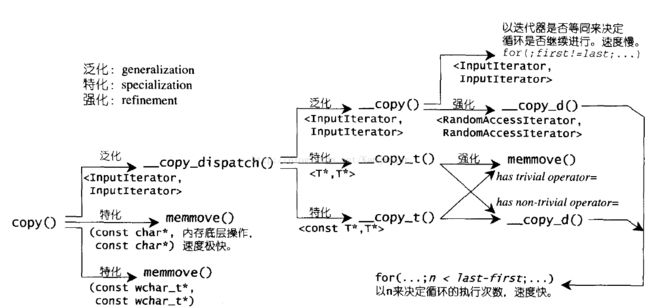
// Filename: stl_algobase.h
// 这个文件中定义的都是一些最常用的算法, 我仅仅给出一个思路,
// 不进行详尽讲解, 具体算法请参考算法书籍, 推荐《算法导论》
// 另外, 对于基础薄弱的, 推荐《大话数据结构》, 此书我读了一下
// 试读章节, 适合初学者学习
/*
*
* Copyright (c) 1994
* Hewlett-Packard Company
*
* Permission to use, copy, modify, distribute and sell this software
* and its documentation for any purpose is hereby granted without fee,
* provided that the above copyright notice appear in all copies and
* that both that copyright notice and this permission notice appear
* in supporting documentation. Hewlett-Packard Company makes no
* representations about the suitability of this software for any
* purpose. It is provided "as is" without express or implied warranty.
*
*
* Copyright (c) 1996
* Silicon Graphics Computer Systems, Inc.
*
* Permission to use, copy, modify, distribute and sell this software
* and its documentation for any purpose is hereby granted without fee,
* provided that the above copyright notice appear in all copies and
* that both that copyright notice and this permission notice appear
* in supporting documentation. Silicon Graphics makes no
* representations about the suitability of this software for any
* purpose. It is provided "as is" without express or implied warranty.
*/
/* NOTE: This is an internal header file, included by other STL headers.
* You should not attempt to use it directly.
*/
#ifndef __SGI_STL_INTERNAL_ALGOBASE_H
#define __SGI_STL_INTERNAL_ALGOBASE_H
#ifndef __STL_CONFIG_H
#include
#endif
#ifndef __SGI_STL_INTERNAL_RELOPS
#include
#endif
#ifndef __SGI_STL_INTERNAL_PAIR_H
#include
#endif
#ifndef __TYPE_TRAITS_H_
#include
#endif
#include
#include
#include
#include
#include
#include
#ifndef __SGI_STL_INTERNAL_ITERATOR_H
#include
#endif
__STL_BEGIN_NAMESPACE
// 第三个参数为什么为指针参见
template
inline void __iter_swap(ForwardIterator1 a, ForwardIterator2 b, T*)
{
// 这里交换的其实是内部对象
T tmp = *a;
*a = *b;
*b = tmp;
}
template
inline void iter_swap(ForwardIterator1 a, ForwardIterator2 b)
{
// 型别以第一个为准
__iter_swap(a, b, value_type(a));
}
// 进行交换操作, 使用的是operator =()
template
inline void swap(T& a, T& b)
{
T tmp = a;
a = b;
b = tmp;
}
#ifndef __BORLANDC__
#undef min
#undef max
// max和min非常简单了, 由于返回的是引用, 因此可以嵌套使用
template
inline const T& min(const T& a, const T& b)
{
return b < a ? b : a;
}
template
inline const T& max(const T& a, const T& b)
{
return a < b ? b : a;
}
#endif /* __BORLANDC__ */
template
inline const T& min(const T& a, const T& b, Compare comp)
{
return comp(b, a) ? b : a;
}
template
inline const T& max(const T& a, const T& b, Compare comp)
{
return comp(a, b) ? b : a;
}
// 这是不支持随机访问的情况
template
inline OutputIterator __copy(InputIterator first, InputIterator last,
OutputIterator result, input_iterator_tag)
{
// first != last导致要进行迭代器的比较, 效率低
for ( ; first != last; ++result, ++first)
*result = *first;
return result;
}
template
inline OutputIterator
__copy_d(RandomAccessIterator first, RandomAccessIterator last,
OutputIterator result, Distance*)
{
// 不进行迭代器间的比较, 直接指定循环次数, 高效
for (Distance n = last - first; n > 0; --n, ++result, ++first)
*result = *first;
return result;
}
// 这是支持随机访问的情况
template
inline OutputIterator
__copy(RandomAccessIterator first, RandomAccessIterator last,
OutputIterator result, random_access_iterator_tag)
{
return __copy_d(first, last, result, distance_type(first));
}
template
struct __copy_dispatch
{
// 这里是一个仿函数. 再次派发
OutputIterator operator()(InputIterator first, InputIterator last,
OutputIterator result) {
return __copy(first, last, result, iterator_category(first));
}
};
// 提供兼容
#ifdef __STL_CLASS_PARTIAL_SPECIALIZATION
// 可以直接移动, 不需要额外操作
template
inline T* __copy_t(const T* first, const T* last, T* result, __true_type)
{
memmove(result, first, sizeof(T) * (last - first));
return result + (last - first);
}
// 需要进行一些处理, 保证对象复制的正确性
template
inline T* __copy_t(const T* first, const T* last, T* result, __false_type)
{
return __copy_d(first, last, result, (ptrdiff_t*) 0);
}
// 对指针提供特化
template
struct __copy_dispatch
{
T* operator()(T* first, T* last, T* result)
{
// 判断其内部是否具有trivial_assignment_operator, 以进行派发
typedef typename __type_traits::has_trivial_assignment_operator t;
return __copy_t(first, last, result, t());
}
};
template
struct __copy_dispatch
{
T* operator()(const T* first, const T* last, T* result) {
typedef typename __type_traits::has_trivial_assignment_operator t;
return __copy_t(first, last, result, t());
}
};
#endif /* __STL_CLASS_PARTIAL_SPECIALIZATION */
// 将[first, last)拷贝到result处
template
inline OutputIterator copy(InputIterator first, InputIterator last,
OutputIterator result)
{
// 此处进行函数派发操作
return __copy_dispatch()(first, last, result);
}
// 针对char字符串的特化, 效率至上, C++的设计理念
inline char* copy(const char* first, const char* last, char* result)
{
memmove(result, first, last - first);
return result + (last - first);
}
// 针对wchar_t字符串的特化, 效率至上, C++的设计理念
inline wchar_t* copy(const wchar_t* first, const wchar_t* last,
wchar_t* result) {
memmove(result, first, sizeof(wchar_t) * (last - first));
return result + (last - first);
}
template
inline BidirectionalIterator2 __copy_backward(BidirectionalIterator1 first,
BidirectionalIterator1 last,
BidirectionalIterator2 result)
{
while (first != last) *--result = *--last;
return result;
}
template
struct __copy_backward_dispatch
{
BidirectionalIterator2 operator()(BidirectionalIterator1 first,
BidirectionalIterator1 last,
BidirectionalIterator2 result)
{
return __copy_backward(first, last, result);
}
};
#ifdef __STL_CLASS_PARTIAL_SPECIALIZATION
template
inline T* __copy_backward_t(const T* first, const T* last, T* result,
__true_type)
{
const ptrdiff_t N = last - first;
memmove(result - N, first, sizeof(T) * N);
return result - N;
}
template
inline T* __copy_backward_t(const T* first, const T* last, T* result,
__false_type)
{
return __copy_backward(first, last, result);
}
template
struct __copy_backward_dispatch
{
T* operator()(T* first, T* last, T* result)
{
typedef typename __type_traits::has_trivial_assignment_operator t;
return __copy_backward_t(first, last, result, t());
}
};
template
struct __copy_backward_dispatch
{
T* operator()(const T* first, const T* last, T* result)
{
typedef typename __type_traits::has_trivial_assignment_operator t;
return __copy_backward_t(first, last, result, t());
}
};
#endif /* __STL_CLASS_PARTIAL_SPECIALIZATION */
// 将[first, last)的元素反向拷贝到(..., last)处, 其机制和copy非常接近, 不做说明
template
inline BidirectionalIterator2 copy_backward(BidirectionalIterator1 first,
BidirectionalIterator1 last,
BidirectionalIterator2 result)
{
return __copy_backward_dispatch()(first, last,
result);
}
template
pair __copy_n(InputIterator first, Size count,
OutputIterator result,
input_iterator_tag)
{
for ( ; count > 0; --count, ++first, ++result)
*result = *first;
return pair(first, result);
}
template
inline pair
__copy_n(RandomAccessIterator first, Size count,
OutputIterator result,
random_access_iterator_tag)
{
// 使用copy()以选择最高效的拷贝算法
RandomAccessIterator last = first + count;
return pair(last,
copy(first, last, result));
}
// 从first拷贝n个值到result处
template
inline pair
copy_n(InputIterator first, Size count,
OutputIterator result)
{
// 进行函数派发, 选咋高效版本
return __copy_n(first, count, result, iterator_category(first));
}
// 使用value填充[first, last)区间
template
void fill(ForwardIterator first, ForwardIterator last, const T& value)
{
for ( ; first != last; ++first)
*first = value; // 调用的是operator =(), 这个要特别注意
}
// 用value填充[first, first + n)的区间
// 为了防止越界, 可以使用下面实例的技巧
// vector vec();
// for (int i = 0; i < 10; ++i)
// vec.push_back(i);
// fill_n(inserter(iv, iv.begin()), 100, 10); // 这就可以使容器动态扩展
template
OutputIterator fill_n(OutputIterator first, Size n, const T& value)
{
for ( ; n > 0; --n, ++first)
*first = value;
return first;
}
// 找到两个序列第一个失配的地方, 结果以pair返回
template
pair mismatch(InputIterator1 first1,
InputIterator1 last1,
InputIterator2 first2)
{
// 遍历区间, 寻找失配点
while (first1 != last1 && *first1 == *first2) {
++first1;
++first2;
}
return pair(first1, first2);
}
// 提供用户自定义的二元判别式, 其余同上
template
pair mismatch(InputIterator1 first1,
InputIterator1 last1,
InputIterator2 first2,
BinaryPredicate binary_pred)
{
while (first1 != last1 && binary_pred(*first1, *first2)) {
++first1;
++first2;
}
return pair(first1, first2);
}
// 如果序列在[first, last)内相等, 则返回true, 如果第二个序列有多余的元素,
// 则不进行比较, 直接忽略. 如果第二个序列元素不足, 会导致未定义行为
template
inline bool equal(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2)
{
for ( ; first1 != last1; ++first1, ++first2)
if (*first1 != *first2) // 只要有一个不相等就判定为false
return false;
return true;
}
// 进行比较的操作改为用户指定的二元判别式, 其余同上
template
inline bool equal(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, BinaryPredicate binary_pred)
{
for ( ; first1 != last1; ++first1, ++first2)
if (!binary_pred(*first1, *first2))
return false;
return true;
}
// 字典序比较, 非常类似字符串的比较
// 具体比较方式参见STL文档, 另外strcmp()也可以参考
template
bool lexicographical_compare(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2)
{
for ( ; first1 != last1 && first2 != last2; ++first1, ++first2) {
if (*first1 < *first2)
return true;
if (*first2 < *first1)
return false;
}
return first1 == last1 && first2 != last2;
}
// 二元判别式自己指定, 其余同上
template
bool lexicographical_compare(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2,
Compare comp) {
for ( ; first1 != last1 && first2 != last2; ++first1, ++first2)
{
if (comp(*first1, *first2))
return true;
if (comp(*first2, *first1))
return false;
}
return first1 == last1 && first2 != last2;
}
// 针对字符串的特化, 效率至上
inline bool
lexicographical_compare(const unsigned char* first1,
const unsigned char* last1,
const unsigned char* first2,
const unsigned char* last2)
{
const size_t len1 = last1 - first1;
const size_t len2 = last2 - first2;
const int result = memcmp(first1, first2, min(len1, len2));
return result != 0 ? result < 0 : len1 < len2;
}
// 针对字符串的特化, 效率至上
inline bool lexicographical_compare(const char* first1, const char* last1,
const char* first2, const char* last2)
{
#if CHAR_MAX == SCHAR_MAX
return lexicographical_compare((const signed char*) first1,
(const signed char*) last1,
(const signed char*) first2,
(const signed char*) last2);
#else
return lexicographical_compare((const unsigned char*) first1,
(const unsigned char*) last1,
(const unsigned char*) first2,
(const unsigned char*) last2);
#endif
}
// 一句话概括, 这个是strcmp()的泛化版本
template
int lexicographical_compare_3way(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2)
{
while (first1 != last1 && first2 != last2) {
if (*first1 < *first2) return -1;
if (*first2 < *first1) return 1;
++first1; ++first2;
}
if (first2 == last2) {
return !(first1 == last1);
} else {
return -1;
}
}
// 特换版本, 效率决定一切
inline int
lexicographical_compare_3way(const unsigned char* first1,
const unsigned char* last1,
const unsigned char* first2,
const unsigned char* last2)
{
const ptrdiff_t len1 = last1 - first1;
const ptrdiff_t len2 = last2 - first2;
const int result = memcmp(first1, first2, min(len1, len2));
return result != 0 ? result : (len1 == len2 ? 0 : (len1 < len2 ? -1 : 1));
}
inline int lexicographical_compare_3way(const char* first1, const char* last1,
const char* first2, const char* last2)
{
#if CHAR_MAX == SCHAR_MAX
return lexicographical_compare_3way(
(const signed char*) first1,
(const signed char*) last1,
(const signed char*) first2,
(const signed char*) last2);
#else
return lexicographical_compare_3way((const unsigned char*) first1,
(const unsigned char*) last1,
(const unsigned char*) first2,
(const unsigned char*) last2);
#endif
}
__STL_END_NAMESPACE
#endif /* __SGI_STL_INTERNAL_ALGOBASE_H */
// Local Variables:
// mode:C++
// End:
实例:
// swap algorithm example (C++11)
#include // std::cout
#include // std::swap
int main () {
int x=10, y=20; // x:10 y:20
std::swap(x,y); // x:20 y:10
int foo[4]; // foo: ? ? ? ?
int bar[] = {10,20,30,40}; // foo: ? ? ? ? bar: 10 20 30 40
std::swap(foo,bar); // foo: 10 20 30 40 bar: ? ? ? ?
std::cout << "foo contains:";
for (int i: foo) std::cout << ' ' << i;
std::cout << '\n';
return 0;
} Output:
foo contains: 10 20 30 40 |
// fill algorithm example
#include // std::cout
#include // std::fill
#include // std::vector
int main () {
std::vector myvector (8); // myvector: 0 0 0 0 0 0 0 0
std::fill (myvector.begin(),myvector.begin()+4,5); // myvector: 5 5 5 5 0 0 0 0
std::fill (myvector.begin()+3,myvector.end()-2,8); // myvector: 5 5 5 8 8 8 0 0
std::cout << "myvector contains:";
for (std::vector::iterator it=myvector.begin(); it!=myvector.end(); ++it)
std::cout << ' ' << *it;
std::cout << '\n';
return 0;
} Output:
myvector contains: 5 5 5 8 8 8 0 0 |
// fill_n example
#include // std::cout
#include // std::fill_n
#include // std::vector
int main () {
std::vector myvector (8,10); // myvector: 10 10 10 10 10 10 10 10
std::fill_n (myvector.begin(),4,20); // myvector: 20 20 20 20 10 10 10 10
std::fill_n (myvector.begin()+3,3,33); // myvector: 20 20 20 33 33 33 10 10
std::cout << "myvector contains:";
for (std::vector::iterator it=myvector.begin(); it!=myvector.end(); ++it)
std::cout << ' ' << *it;
std::cout << '\n';
return 0;
} Output:
myvector contains: 20 20 20 33 33 33 10 10 |
// equal algorithm example
#include // std::cout
#include // std::equal
#include // std::vector
bool mypredicate (int i, int j) {
return (i==j);
}
int main () {
int myints[] = {20,40,60,80,100}; // myints: 20 40 60 80 100
std::vectormyvector (myints,myints+5); // myvector: 20 40 60 80 100
// using default comparison:
if ( std::equal (myvector.begin(), myvector.end(), myints) )
std::cout << "The contents of both sequences are equal.\n";
else
std::cout << "The contents of both sequences differ.\n";
myvector[3]=81; // myvector: 20 40 60 81 100
// using predicate comparison:
if ( std::equal (myvector.begin(), myvector.end(), myints, mypredicate) )
std::cout << "The contents of both sequences are equal.\n";
else
std::cout << "The contents of both sequences differ.\n";
return 0;
} Output:
The contents of both sequences are equal. The contents of both sequence differ. |