freetype2 开发手册
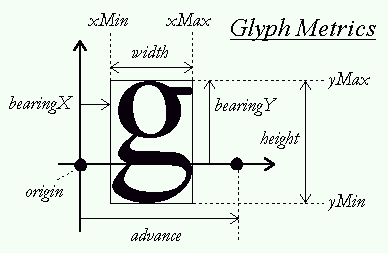
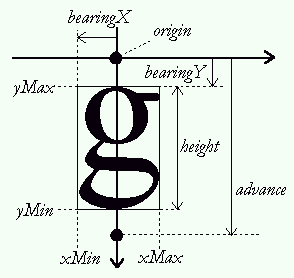
《FreeType Glyph Conventions》中译版FreeType字形约定一、基本印刷概念1、字体文件、格式和信息 字体是一组可以被显示和打印的多样的字符映像,在单个字体中共享一些共有的特性,包括外表、风格、衬线等。按印刷领域的说法,它必须区别一个字体 家族和多种字体外观,后者通常是从同样的模板而来,但是风格不同。例如,Palatino Regular 和 Palatino Italic是两种不同的外观,但是属于同样的家族Palatino。 单个字体术语根据上下文既可以指家族也可指外观。例如,大多文字处理器的用户用字体指不同的字体家族,然而,大多这些家族根据它们的格式会通过多 个数据文件实现。对于 TrueType来讲,通常是每个外观一个文件(arial.ttf对应Arial Regular外观,ariali.ttf对应Arial Italic外观)这个文件也叫字体,但是实际上只是一个字体外观。 数字字体是一个可以包含一个和多个字体外观的数据文件,它们每个都包含字符映像、字符度量,以及其他各种有关文本布局和特定字符编码的重要信息。 对有些难用的格式,像Adobe的Type1,一个字体外观由几个文件描述(一个包含字符映象,一个包含字符度量等)。在这里我们忽略这种情况,只考虑一 个外观一个文件的情况,不过在FT2.0中,能够处理多文件字体。 为了方便说明,一个包含多个外观的字体文件我们叫做字体集合,这种情况不多见,但是多数亚洲字体都是如此,它们会包含两种或多种表现形式的映像,例如横向和纵向布局。 2、字符映象和图 字符映象叫做字形,根据书写、用法和上下文,单个字符能够有多个不同的映象,即多个字形。多个字符也可以有一个字形(例如Roman??)。字符 和字形之间的关系可能是非常复杂,本文不多述。而且,多数字体格式都使用不太难用的方案存储和访问字形。为了清晰的原因,当说明FT时,保持下面的观念 3、字符和字体度量 每个字符映象都关联多种度量,被用来在渲染文本时,描述如何放置和管理它们。在后面会有详述,它们和字形位置、光标步进和文本布局有关。它们在渲染一个文本串时计算文本流时非常重要。 每个可缩放的字体格式也包含一些全局的度量,用概念单位表示,描述同一种外观的所有字形的一些特性,例如最大字形外框,字体的上行字符、下行字符和文本高度等。 虽然这些度量也会存在于一些不可缩放格式,但它们只应用于一组指定字符维度和分辨率,并且通常用象素表示。 二、字形轮廓1、象素、点和设备解析度 当处理计算机图形程序时,指定象素的物理尺寸不是正方的。通常,输出设备是屏幕或打印机,在水平和垂直方向都有多种分辨率,当渲染文本是要注意这些情况。 定义设备的分辨率通常使用用dpi(每英寸点(dot)数)表示的两个数,例如,一个打印机的分辨率为300x600dpi表示在水平方向,每英 寸有300 个象素,在垂直方向有600个象素。一个典型的计算机显示器根据它的大小,分辨率不同(15’’和17’’显示器对640x480象素大小不同),当然图 形模式分辨率也不一样。 所以,文本的大小通常用点(point)表示,而不是用设备特定的象素。点是一种简单的物理单位,在数字印刷中,一点等于1/72英寸。例如,大多罗马书籍使用10到14点大小印刷文字内容。 可以用点数大小来计算象素数,公式如下: 象素数 = 点数*分辨率/72 2、向量表示 字体轮廓的源格式是一组封闭的路径,叫做轮廓线。每个轮廓线划定字形的外部或内部区域,它们可以是线段或是Bezier曲线。 曲线通过控制点定义,根据字体格式,可以是二次(conic Beziers)或三次(cubic Beziers)多项式。在文献中,conic Bezier通常称为quadratic Beziers。因此,轮廓中每个点都有一个标志表示它的类型是一般还是控制点,缩放这些点将缩放整个轮廓。 每个字形最初的轮廓点放置在一个不可分割单元的网格中,点通常在字体文件中以16位整型网格坐标存储,网格的原点在(0,0),它的范围是-16384到-16383(虽然有的格式如Type1使用浮点型,但为简便起见,我们约定用整型分析)。 网格的方向和传统数学二维平面一致,x轴从左到右,y轴从下到上。 在创建字形轮廓时,一个字体设计者使用一个假想的正方形,叫做EM正方形。他可以想象成一个画字符的平面。正方形的大小,即它边长的网格单元是很重要的,原因是 * 它是用来将轮廓缩放到指定文本尺寸的参考,例如在300x300dpi中的12pt大小对应12*300/72=50象素。从网格单元缩放到象素可以使用下面的公式 象素数 = 点数 × 分辨率/72 * EM尺寸越大,可以达到更大的分辨率,例如一个极端的例子,一个4单元的EM,只有25个点位置,显然不够,通常TrueType字体之用2048单元的EM;Type1 PostScript字体有一个固定1000网格单元的EM,但是点坐标可以用浮点值表示。 注意,字形可以自由超出EM正方形。网格单元通常交错字体单元或EM单元。上边的象素数并不是指实际字符的大小,而是EM正方形显示的大小,所以不同字体,虽然同样大小,但是它们的高度可能不同。 3、Hinting和位图渲染 存储在一个字体文件中的轮廓叫“主”轮廓,它的点坐标用字体单元表示,在它被转换成一个位图时,它必须缩放至指定大小。这通过一个简单的转换完成,但是总会产生一些不想要的副作用,例如像字母E和H,它们主干的宽度和高度会不相同。 所以,优秀的字形渲染过程在缩放“点”是,需要通过一个网格对齐(grid-fitting)的操作(通常叫hinting),将它们对齐到目标 设备的象素网格。这主要目的之一是为了确保整个字体中,重要的宽度和高度能够一致。例如对于字符I和T来说,它们那个垂直笔划要保持同样象素宽度。另外, 它的目的还有管理如stem和overshoot的特性,这在小象素字体会引起一些问题。 有若干种方式来处理网格对齐,多数可缩放格式中,每种字形轮廓都有一些控制数据和程序。 * 显式网格对齐 TrueType格式定义了一个基于栈的虚拟机(VM),可以借助多于200中操作码(大多是几何操作)来编写程序,每个字形都由一个轮廓和一个控制程序组成,后者可以处理实际的网格对齐,他由字体设计者定义。 * 隐式网格对齐(也叫hinting) Type1格式有一个更简单的方式,每个字形由一个轮廓以及若干叫hints的片断组成,后者用来描述字形的某些重要特性,例如主干的存在、某些宽度匀称性等诸如此类。没有多少种hint,要看渲染器如何解释hint来产生一个对齐的轮廓。 * 自动网格对齐 有些格式很简单,没有包括控制信息,将字体度量如步进、宽度和高度分开。要靠渲染器来猜测轮廓的一些特性来实现得体的网格对齐。 下面总结了每种方案的优点和缺点 方案 优点 缺点 显式 质量:对小字体有很好的结果,这对屏幕显示非常重要。 速度:如果程序很复杂,解释字节码很慢 隐式 大小:Hint通常比显式字形程序小的多 质量:小字体不好,最后结合反走样 自动 大小:不需要控制信息,导致更小的字体文件 质量:小字体不好,最后结合反走样 三、字形度量1、基线(baseline)、笔(pen)和布局(layout) 基线是一个假想的线,用来在渲染文本时知道字形,它可以是水平(如Roman)和是垂直的(如中文)。而且,为了渲染文本,在基线上有一个虚拟的点,叫做笔位置(pen position)或原点(origin),他用来定位字形。 每种布局使用不同的规约来放置字形: * 对水平布局,字形简单地搁在基线上,通过增加笔位置来渲染文本,既可以向右也可以向左增加。 两个相邻笔位置之间的距离是根据字形不同的,叫做步进宽度(advance width)。注意这个值总是正数,即使是从右往左的方向排列字符,如Arabic。这和文本渲染的方式有些不同。 笔位置总是放置在基线上。 * 对垂直布局,字形在基线上居中放置。 2、印刷度量和边界框 在指定字体中,定义了多种外观度量。 * 上行高度(ascent)。从基线到放置轮廓点最高/上的网格坐标,因为Y轴方向是向上的,所以它是一个正值。 * 下行高度(descent)。从基线到放置轮廓点最低/下的网格坐标,因为Y轴方向是向上的,所以它是一个负值。 * 行距(linegap)。两行文本间必须的距离,基线到基线的距离应该计算成 上行高度 - 下行高度 + 行距 * 边界框(bounding box,bbox)。这是一个假想的框子,他尽可能紧密的装入字形。通过四个值来表示,叫做xMin、yMin、xMax、yMax,对任何轮廓都可以计 算,它们可以是字体单元(测量原始轮廓)或者整型象素单元(测量已缩放的轮廓)。注意,如果不是为了网格对齐,你无需知道这个框子的这个值,只需知道它的 大小即可。但为了正确渲染一个对齐的字形,需要保存每个字形在基线上转换、放置的重要对齐。 * 内部leading。这个概念从传统印刷业而来,他表示字形出了EM正方形空间数量,通常计算如下 internal leading = ascent – descent – EM_size * 外部leading。行距的别名。 3、跨距(bearing)和步进 每个字形都有叫跨距和步进的距离,它们的定义是常量,但是它们的值依赖布局,同样的字形可以用来渲染横向或纵向文字。 * 左跨距或bearingX。从当前笔位置到字形左bbox边界的水平距离,对水平布局是正数,对垂直布局大多是负值。 * 上跨距或bearingY。从基线到bbox上边界的垂直距离,对水平布局是正值,对垂直布局是负值。 * 步进宽度或advanceX。当处理文本渲染一个字形后,笔位置必须增加(从左向右)或减少(从右向左)的水平距离。对水平布局总是正值,垂直布局为null。 * 步进高度或advanceY。当每个字形渲染后,笔位置必须减少的垂直距离。对水平布局为null,对垂直布局总是正值。 * 字形宽度。字形的水平长度。对未缩放的字体坐标,它是bbox.xMax-bbox.xMin,对已缩放字形,它的计算要看特定情况,视乎不同的网格对齐而定。 * 字形高度。字形的垂直长度。对未缩放的字体坐标,它是bbox.yMax-bbox.yMin,对已缩放字形,它的计算要看特定情况,视乎不同的网格对齐而定。 * 右跨距。只用于水平布局,描述从bbox右边到步进宽度的距离,通常是一个非负值。 advance_width – left_side_bearing – (xMax-xMin) 下图是水平布局所有的度量
4、网格对齐的效果 因为hinting将字形的控制点对齐到象素网格,这个过程将稍稍修改字符映象的尺寸,和简单的缩放有所区别。例如,小写字母m的映象在主网格中 有时是一个正方形,但是为了使它在小象素大小情况下可以辨别,hinting试图扩大它已缩放轮廓,以让它三条腿区分开来,这将导致一个更大的字符位图。 字形度量也会受网格对齐过程的影响: * 映象的宽度和高度改变了,即使只是一个象素,对于小象素大小字形区别都很大; * 映象的边界框改变了,也改变了跨距; * 步进必须更改,例如如果被hint的位图比缩放的位图大时,必须增加步进宽度,来反映扩大的字形宽度。 这有一些含义如下, * 因为hinting,简单缩放字体上行或下行高度可能不会有正确的结果,一个可能的方法时保持被缩放上行高度的顶和被缩放下行高度的底。 * 没有容易的方法去hint一个范围内字形并步进它们宽度,因为hinting对每个轮廓工作都不一样。唯一的方法时单独hint每个字形,并记录返回值。有些格式,如TrueType,包含一些表对一些通用字符预先计算出它们的象素大小。 * hinting依赖最终字符宽度和高度的象素值,意味着它非常依赖分辨率,这个特性使得正确的所见即所得布局非常难以实现。 在FT 中,对字形轮廓处理2D变换很简单,但是对一个已hint的轮廓,需要注意专有地使用整型象素距离(意味着FT_Outline_Translate() 函数的参数应该都乘以64,因为点坐标都是26.6固定浮点格式),否则,变换将破坏hinter的工作,导致非常难看的位图。 5、文本宽度和边界框 如上所示,指定字形的原点对应基线上笔的位置,没有必要定位字形边界框的某个角,这不像多数典型的位图字体格式。有些情况,原点可以在边界框的外边,有时,也可以在里边,这要看给定的字形外形了。 四、字距调整字距调整这个术语指用来在一个文本串中调整重合字形的相对位置的特定信息。 1、字距调整对 字距调整包括根据相邻字形的轮廓修改它们之间的距离。例如T和y可以贴得更近一点,因为y的上缘正好在T的右上角一横的下边。 2、应用字距调整 在渲染文本时应用字据调整是一个比较简单的过程,只需要在写下一个字形时,将缩放的字距加到笔位置即可。然而,正确的渲染器要考虑的更细一点。 五、文本处理1、书写简单文本串 在第一个例子中,我们将生成一个简单的Roman文字串,即采用水平的自左向右布局,使用专有的象素度量,这个过程如下: 2、子象素定位 在渲染文本时使用子象素定位有时很有用。这非常重要,例如为了提供半所见即所得的文本布局,文本渲染的算法和上一节很相似,但是有些区别: 3、简单字距调整 在基本文本渲染算法上增加字距调整非常简单,当一个字距调整对发现了,简单地在第4步前,将缩放后的调整距离增加到笔位置即可。淡然,这个距离在算法1需要被取整,算法2不必要。 4、自右向左布局 布局Arabic或Heberw文字的过程非常相似,区别只是在字形渲染前,笔位置需要减少(记住步进宽度总是正值) 5、垂直布局 布局垂直文字也是同样的过程,重要的区别如下: 6、所见即所得布局 六、FT轮廓1、FT轮廓描述和结构 a. 轮廓曲线分解 2、边界和控制框计算 边界框(bbox)是一个完全包含指定轮廓的矩形,所要的是最小的边界框。因为弧的定义,bezier的控制点无需包含在轮廓的边界框中。例如轮 廓的上缘是一个Bezier弧,一个off点就位于bbox的上面。不过这在字符轮廓中很少出现,因为大多字体设计者和创建工具都会在每个曲线拐点处放一 个on点,这会使hinting更加容易。于是我们定义了控制框(cbox),它是一个包含轮廓所有点的最小矩形,很明显,它包含bbox,通常它们是一 样的。不想 bbox,cbox计算起来非常快。 七、FT位图1、向量坐标和象素坐标对比 这里阐述了向量坐标的象素坐标的区别,为了更清楚的说明,使用方括号来表示象素坐标,使用圆括号表示向量坐标。 2、FT位图和象素图描述符 一个位图和象素图通过一个叫FT_Bitmap的单一结构描述,他定义在 3、轮廓转换到位图和象素图 使用FT从一个向量映象转换到位图和象素图非常简单,但是,在转换前,必须理解有关在2D平面上放置轮廓的一些问题: |
| Subject: [精华] Re: FreeType 2开发文档 [中译版] Author: gogoliu Posted: 2006-01-23 19:14 Length:15,143 byte(s) |
|
| [Original][Print] [Top] | |
《The design of FreeType 2》中译版FreeType 2的设计介绍这份文档提供了FreeType 2函数库设计与实现的细节。本文档的目标是让开发人员更好的理解FreeType 2是如何组织的,并让他们扩充、定制和调试它。首先,我们先了解这个库的目的,也就是说,为什么会写这个库: * 它让客户应用程序方便的访问字体文件,无论字体文件存储在哪里,并且与字体格式无关。 * 方便的提取全局字体数据,这些数据在平常的字体格式中普遍存在。(例如:全局度量标准,字符编码/字符映射表,等等) * 方便的提取某个字符的字形数据(度量标准,图像,名字,其他任何东西) * 访问字体格式特定的功能(例如,SFNT表,多重控制,OpenType轮廓表) Freetype 2的设计也受如下要求很大的影响: * 高可移植性。这个库必须可以运行在任何环境中。这个要求引入了一些非常激烈的选择,这些是FreeType2的低级系统界面的一部分。 * 可扩展性。新特性应该可以在极少改动库基础代码的前提下添加。这个要求引入了非常简单的设计:几乎所有操作都是以模块的形式提供的。 * 可定制。它应该能够很容易建立一个只包含某个特定项目所需的特性的版本。当你需要集成它到一个嵌入式图形库的字体服务器中时,这是非常重要的。 * 简洁高效。这个库的主要目标是只有很少cpu和内存资源的嵌入式系统。 这份文档的其他部分分为几个部分。首先,一些章节介绍了库的基本设计以及Freetype 2内部对象/数据的管理。 接下来的章节专注于库的定制和与这个话题相关的系统特定的界面,如何写你自己的模块和如何按需裁减库初始化和编译。 一、组件和APIFT可以看作是一组组件,每个组件负责一部分任务,它们包括* 客户应用程序一般会调用FT高层API,它的功能都在一个组件中,叫做基础层。 * 根据上下文和环境,基础层会调用一个或多个模块进行工作,大多数情况下,客户应用程序不知道使用那个模块。 * 基础层还包含一组例程来进行一些共通处理,例如内存分配,列表处理、io流解析、固定点计算等等,这些函数可以被模块随意调用,它们形成了一个底层基础API。 如下图,表明它们的关系 另外, * 为了一些特殊的构建,基础层的有些部分可以替换掉,也可以看作组件。例如ftsystem组件,负责实现内存管理和输入流访问,还有ftinit,负责库初始化。 * FT还有一些可选的组件,可以根据客户端应用灵活使用,例如ftglyph组件提供一个简单的API来管理字形映象,而不依赖它们内部表示法。或者是访问特定格式的特性,例如ftmm组件用来访问和管理Type1字体中Multiple Masters数据。 * 最后,一个模块可以调用其他模块提供的函数,这对在多个字体驱动模块中共享代码和表非常有用,例如truetype和cff模块都使用sfnt模块提供的函数。 见下图,是对上图的一个细化。 请注意一些要点: * 一个可选的组件可以用在高层API,也可以用在底层API,例如上面的ftglyph; * 有些可选组件使用模块特定的接口,而不是基础层的接口,上例中,ftmm直接访问Type1模块来访问数据; * 一个可替代的组件能够提供一个高层API的函数,例如,ftinit提供FT_Init_FreeType() 二、公共对象和类1、FT中的面向对象 虽然FT是使用ANSI C编写,但是采用面向对象的思想,是这个库非常容易扩展,因此,下面有一些代码规约。1. 每个对象类型/类都有一个对应的结构类型和一个对应的结构指针类型,后者称为类型/类的句柄类型 设想我们需要管理FT中一个foo类的对象,可以定义如下 typedef struct FT_FooRec_* FT_Foo; typedef struct FT_FooRec_ { // fields for the foo class … }FT_FooRec; 依照规约,句柄类型使用简单而有含义的标识符,并以FT_开始,如FT_Foo,而结构体使用相同的名称但是加上Rec后缀。Rec是记录的缩写。每个类类型都有对应的句柄类型; 2. 类继承通过将基类包装到一个新类中实现,例如,我们定义一个foobar类,从foo类继承,可以实现为 typedef struct FT_FooBarRec_ * FT_FooBar; typedef struct FT_FooBarRec_ { FT_FooRec root; //基类 }FT_FooBarRec; 可以看到,将一个FT_FooRec放在FT_FooBarRec定义的开始,并约定名为root,可以确保一个foobar对象也是一个foo对象。 在实际使用中,可以进行类型转换。 后面 2、FT_Library类 这个类型对应一个库的单一实例句柄,没有定义相应的FT_LibraryRec,使客户应用无法访问它的内部属性。库对象是所有FT其他对象的父亲,你需要在做任何事情前创建一个新的库实例,销毁它时会自动销毁他所有的孩子,如face和module等。 通常客户程序应该调用FT_Init_FreeType()来创建新的库对象,准备作其他操作时使用。 另一个方式是通过调用函数FT_New_Library()来创建一个新的库对象,它在 调用FT_Init_FreeType()更方便一些,因为他会缺省地注册一些模块。这个方式中,模块列表在构建时动态计算,并依赖ftinit部件的内 容。(见ftinit.c[l73]行,include FT_CONFIG_MODULES_H,其实就是包含ftmodule.h,在ftmodule.h中定义缺省的模块,所以模块数组 ft_default_modules的大小是在编译时动态确定的。) 3、FT_Face类 一个外观对象对应单个字体外观,即一个特定风格的特定外观类型,例如Arial和Arial Italic是两个不同的外观。一个外观对象通常使用FT_New_Face()来创建,这个函数接受如下参数:一个FT_Library句柄,一个表示字体文件的C文件路径名,一个决定从文件中装载外观的索引(一个文件中可能有不同的外观),和FT_Face句柄的地址,它返回一个错误码。 FT_Error FT_New_Face( FT_Library library, const char* filepathname, FT_Long face_index, FT_Face* face); 函数调用成功,返回0,face参数将被设置成一个非NULL值。 外观对象包含一些用来描述全局字体数据的属性,可以被客户程序直接访问。例如外观中字形的数量、外观家族的名称、风格名称、EM大小等,详见FT_FaceRec定义。 4、FT_Size类 每个FT_Face对象都有一个或多个FT_Size对象,一个尺寸对象用来存放指定字符宽度和高度的特定数据,每个新创建的外观对象有一个尺寸,可以通过face->size直接访问。尺寸对象的内容可以通过调用FT_Set_Pixel_Sizes()或FT_Set_Char_Size()来改变。 一个新的尺寸对象可以通过FT_New_Size()创建,通过FT_Done_Size()销毁,一般客户程序无需做这一步,它们通常可以使用每个FT_Face缺省提供的尺寸对象。 FT_Size 公共属性定义在FT_SizeRec中,但是需要注意的是有些字体驱动定义它们自己的FT_Size的子类,以存储重要的内部数据,在每次字符大小改变时 计算。大多数情况下,它们是尺寸特定的字体hint。例如,TrueType驱动存储CVT表,通过cvt程序执行将结果放入TT_Size结构体中,而 Type1驱动将scaled global metrics放在T1_Size对象中。 5、FT_GlyphSlot类 字形槽的目的是提供一个地方,可以很容易地一个个地装入字形映象,而不管它的格式(位图、向量轮廓或其他)。理想的,一旦一个字形槽创建了,任何字形映象 可以装入,无需其他的内存分配。在实际中,只对于特定格式才如此,像TrueType,它显式地提供数据来计算一个槽地最大尺寸。另一个字形槽地原因是他用来为指定字形保存格式特定的hint,以及其他为正确装入字形的必要数据。 基本的FT_GlyphSlotRec结构体只向客户程序展现了字形metics和映象,而真正的实现回包含更多的数据。 例如,TrueType特定的TT_GlyphSlotRec结构包含附加的属性,存放字形特定的字节码、在hint过程中暂时的轮廓和其他一些东西。 最后,每个外观对象有一个单一字形槽,可以用face->glyph直接访问。 6、FT_CharMap类 FT_CharMap类型用来作为一个字符地图对象的句柄,一个字符图是一种表或字典,用来将字符码从某种编码转换成字体的字形索引。单个外观可能包含若干字符图,每个对应一个指定的字符指令系统,例如Unicode、Apple Roman、Windows codepages等等。 每个FT_CharMap对象包含一个platform和encoding属性,用来标识它对应的字符指令系统。每个字体格式都提供它们自己的FT_CharMapRec的继承类型并实现它们。 7、对象关系 三、内部对象和类1、内存管理所有内存管理操作通过基础层中3个特定例程完成,叫做FT_Alloc、FT_Realloc、 FT_Free,每个函数需要一个 FT_Memory句柄作为它的第一个参数。它是一个用来描述当前内存池/管理器对象的指针。在库初始化时,在FT_Init_FreeType中调用函 数FT_New_Memory创建一个内存管理器,这个函数位于ftsystem部件当中。 缺省情况下,这个管理器使用ANSI malloc、realloc和free函数,不过ftsystem是基础层中一个可替换的部分,库的特定构建可以提供不同的内存管理器。即使使用缺省的 版本,客户程序仍然可以提供自己的内存管理器,通过如下的步骤,调用FT_Init_FreeType实现: 1. 手工创建一个FT_Memory对象,FT_MemoryRec位于公共文件 2. 使用你自己的内存管理器,调用FT_New_Library()创建一个新的库实例。新的库没有包含任何已注册的模块。 3. 通过调用函数FT_Add_Default_Modules()(在ftinit部件中)注册缺省的模块,或者通过反复调用FT_Add_Module手工注册你的驱动。 2、输入流 字体文件总是通过FT_Stream对象读取,FT_StreamRec的定义位于公共文 件 举例来说,流的缺省实现位于文件src/base/ftsystem.c并使用ANSI fopen/fseek和fread函数。不过在FT2的Unix版本中,提供了另一个使用内存映射文件的实现,对于主机系统来说,可以大大提高速度。 FT区分基于内存和基于磁盘的流,对于前者,所有数据在内存直接访问(例如ROM、只写静态数据和内存映射文件),而后者,使用帧(frame)的概念从字体文件中读出一部分,使用典型的seek/read操作并暂时缓冲。 FT_New_Memory_Face 函数可以用来直接从内存中可读取的数据创建/打开一个FT_Face对象。最后,如果需要客户输入流,客户程序能够使用FT_Open_Face()函数 接受客户输入流。这在压缩或远程字体文件的情况下,以及从特定文档抽取嵌入式字体文件非常有用。 注意每个外观拥有一个流,并且通过FT_Done_Face被销毁。总的来说,保持多个FT_Face在打开状态不是一个很好的主意。 3、模块 FT2 模块本身是一段代码,库调用FT_Add_Moudle()函数注册模块,并为每个模块创建了一个FT_Module对象。FT_ModuleRec的定 义对客户程序不是公开的,但是每个模块类型通过一个简单的公共结构FT_Module_Class描述,它定义在< freetype/ftmodule.h>中,后面将详述。 当调用FT_Add_Module是,需要指定一个FT_Module_Class结构的指针,它的声明如下: FT_Error FT_Add_Module( FT_Library library, const FT_Module_Class* clazz); 调用这个函数将作如下操作: * 检查库中是否已经有对应FT_Module_Class指名的模块对象; * 如果是,比较模块的版本号看是否可以升级,如果模块类的版本号小于已装入的模块,函数立即返回。当然,还要检查正在运行的FT版本是否满足待装模块所需FT的版本。 * 创建一个新的FT_Module对象,使用模块类的数据的标志决定它的大小和如何初始化; * 如果在模块类中有一个模块初始器,它将被调用完成模块对象的初始化; * 新的模块加入到库的“已注册”模块列表中,对升级的情况,先前的模块对象只要简单的销毁。 注意这个函数并不返回FT_Module句柄,它完全是库内部的事情,客户程序不应该摆弄他。最后,要知道FT2识别和管理若干种模块,这在后面将有详述,这里列举如下: * 渲染器模块用来将原始字形映象转换成位图或象素图。FT2自带两个渲染器,一个是生成单色位图,另一个生成高质量反走样的象素图。 * 字体驱动模块用来支持多种字体格式,典型的字体驱动需要提供特定的FT_Face、FT_Size、FT_GlyphSlot和FT_CharMap的实现; * 助手模块被多个字体驱动共享,例如sfnt模块分析和管理基于SFNT字体格式的表,用于TrueType和OpenType字体驱动; * 最后,auto-hinter模块在库设计中有特殊位置,它不管原始字体格式,处理向量字形轮廓,使之产生优质效果。 注意每个FT_Face对象依据原始字体文件格式,都属于相应的字体驱动。这就是说,当一个模块从一个库实例移除/取消注册后,所有的外观对象都被销毁(通常是调用FT_Remove_Module()函数)。 因此,你要注意当你升级或移除一个模块时,没有打开FT_Face对象,因为这会导致不预期的对象删除。 4、库 现在来说说FT_Library对象,如上所述,一个库实例至少包含如下: * 一个内存管理对象(FT_Memory),用来在实例中分配、释放内存; * 一个FT_Module对象列表,对应“已安装”或“已注册”的模块,它可以随时通过FT_Add_Module()和FT_Remove_Module()管理; * 记住外观对象属于字体驱动,字体驱动模块属于库。 还有一个对象属于库实例,但仍未提到:raster pool 光栅池是一个固定大小的一块内存,为一些内存需要大的操作作为内部的“草稿区域”,避免内存分配。例如,它用在每个渲染器转换一个向量字形轮廓到一个位图时(这其实就是它为何叫光栅池的原因)。 光栅池的大小在初始化的时候定下来的(缺省为16k字节),运行期不能修改。当一个瞬时操作需要的内存超出这个池的大小,可以另外分配一块作为例外条件,或者是递归细分任务,以确保不会超出池的极限。 这种极度的内存保守行为是为了FT的性能考虑,特别在某些地方,如字形渲染、扫描线转换等。 5、总结 最后,下图展示的上面所述内容,他表示FT基本设计的对象图 四、模块类 在FT中有若干种模块 * 渲染模块,用来管理可缩放的字形映象。这意味这转换它们、计算边框、并将它们转换成单色和反走样位图。FT可以处理任何类型的字形映像,只要为它提供了一个渲染模块,FT缺省带了两个渲染器 raster 支持从向量轮廓(由FT_Outline对象描述)到单色位图的转换 smooth 支持同样的轮廓转换到高质量反走样的象素图,使用256级灰度。这个渲染器也支持直接生成span。 * 字体驱动模块,用来支持一种或多种特定字体格式,缺省情况下,FT由下列字体驱动 truetype 支持TrueType字体文件 type1 支持PostScript Type1字体,可以是二进制(.pfb)和ASCII(.pfa)格式,包括Multiple Master字体 cid 支持Postscript CID-keyed字体 cff 支持OpenType、CFF和CEF字体(CEF是CFF的一个变种,在Adobe的SVG Viewer中使用 winfonts 支持Windows位图字体,.fon和.fnt 字体驱动可以支持位图和可缩放的字形映象,一个特定支持Bezier轮廓的字体驱动通过FT_Outline可以提供他自己的hinter,或依赖FT的autohinter模块。 * 助手模块,用来处理一些共享代码,通常被多个字体驱动,甚至是其他模块使用,缺省的助手如下 sfnt 用来支持基于SFNT存储纲要的字体格式,TrueType和OpenType字体和其他变种 psnames 用来提供有关字形名称排序和Postscript编码/字符集的函数。例如他可以从一个Type1字形名称字典中自动合成一个Unicode字符图。 psaux 用来提供有关Type1字符解码的函数,type1、cid和cff都需要这个特性 * 最后,autohinter模块在FT中是特殊角色,当一个字体驱动没有提供自己的hint引擎时,他可以在字形装载时处理各自的字形轮廓。 我们现在来学习模块是如何描述以及如何被FreeType2库管理的。 1 FT_Module_Class结构 2 FT_Module类型 |
|
|
----
良好的沟通能力 和 积极的行动 是成功的钥匙。
|
|
| [Original][Print] [Top] | |
| Subject: [精华] FreeType 2开发文档 [中译版] Author: gogoliu Posted: 2006-01-23 19:18 Length:492 byte(s) |
|
| [Original][Print] [Top] | |
| 下面3份文档是FreeType 2文档的 中译版,包括《FreeType Glyph Conventions》、《The design of FreeType 2》、和《The FreeType 2 Tutorial》。其中,前两者是在网上找到的,译者不详,并且有些部分没有翻译。我翻译了第三份文档的第一部分,由于翻译水平低,翻译得很死板、机 械,大家凑合着看。第二部分要是没人翻译的话,我会在年后翻译。这3份文档的中译版都有待完善,希望有空余时间和能力的朋友可以帮忙完善它们。 | |
|
----
良好的沟通能力 和 积极的行动 是成功的钥匙。
|
|
| [Original][Print] [Top] | |
| Subject: [精华] Re: FreeType 2开发文档 [中译版] Author: gogoliu Posted: 2006-01-23 19:18 Length:25,574 byte(s) |
||
| [Original][Print] [Top] | ||
| 《The FreeType 2 Tutorial》第一部分中译版 FreeType 2 教程 第一步 -- 简易的字形装载 介绍 这是“FreeType2 教程”的第一部分。它将教会你如何: * 初始化库 * 通过创建一个新的 face 对象来打开一个字体文件 * 以点或者象素的形式选择一个字符大小 * 装载一个字形(glyph)图像,并把它转换为位图 * 渲染一个简单的字符串 * 容易地渲染一个旋转的字符串 1.头文件 下面的内容是编译一个使用了FreeType2库的应用程序所需要的指令。请谨慎阅读,自最近一次版本更新后我们已经更改了少许东西。 1.FreeType2 include 目录 你必须把FreeType2头文件的目录添加到编译包含(include)目录中。 注意,现在在Unix系统,你可以运行freetype-config脚本加上--cflags选项来获得正确的编译标记。这个脚本也可以用来检查安装在你系统中的库的版本,以及需要的库和连接标记。 2. 包含名为ft2build.h的文件 Ft2build.h包含了接下来要#include的公共FreeType2头文件的宏声明。 3. 包含主要的FreeType2 API头文件 你要使用FT_FREETYPE_H宏来完成这个工作,就像下面这样: #include #include FT_FREETYPE_H FT_FREETYPE_H是在ftheader.h中定义的一个特别的宏。Ftheader.h包含了一些安装所特定的宏,这些宏指名了FreeType2 API的其他公共头文件。 你可以阅读“FreeType 2 API参考”的这个部分来获得头文件的完整列表。 #include语句中宏的用法是服从ANSI的。这有几个原因: * 这可以避免一些令人痛苦的与FreeType 1.x公共头文件的冲突。 * 宏名字不受限于DOS的8.3文件命名限制。象FT_MULTIPLE_MASTERS_H或FT_SFNT_NAMES_H这样的名字比真实的文件名ftmm.h和fsnames.h更具可读性并且更容易理解。 * 它允许特别的安装技巧,我们不在这里讨论它。 注意:从FreeType 2.1.6开始,旧式的头文件包含模式将不会再被支持。这意味着现在如果你做了象下面那样的事情,你将得到一个错误: #include #include . . . 2. 初始化库 简单地创建一个FT_Library类型的变量,例如library,然后象下面那样调用函数FT_Init_FreeType: #include #include FT_FREETYPE_H FT_LIBRARY library; . . . Error = FT_Init_FreeType ( &library ); If ( error ) { . . . 当初始化库时发生了一个错误 . . . } 这个函数负责下面的事情: * 它创建一个FreeType 2库的新实例,并且设置句柄library为它。 * 它装载库中FreeType所知道的每一个模块。除了别的以外,你新建的library对象可以优雅地处理TrueType, Type 1, CID-keyed 和OpenType/CFF字体。 就像你所看到的,这个函数返回一个错误代码,如同FreeType API的大部分其他函数一样。值为0的错误代码始终意味着操作成功了,否则,返回值指示错误,library设为NULL。 3.装载一个字体face a.从一个字体文件装载 应用程序通过调用FT_New_Face创建一个新的face对象。一个face对象描述了一个特定的字样和风格。例如,’Times New Roman Regular’和’Times New Roman Italic’对应两个不同的face。 FT_Library library; /* 库的句柄 */ FT_Face face; /* face对象的句柄 */ error = FT_Init_FreeType( &library ); if ( error ) { ... } error = FT_New_Face( library, "/usr/share/fonts/truetype/arial.ttf", 0, &face ); if ( error == FT_Err_Unknown_File_Format ) { ... 可以打开和读这个文件,但不支持它的字体格式 } else if ( error ) { ... 其它的错误码意味着这个字体文件不能打开和读,或者简单的说它损坏了... } 就如你所想到的,FT_NEW_Face打开一个字体文件,然后设法从中提取一个face。它的参数为: Library 一个FreeType库实例的句柄,face对象从中建立 Filepathname 字体文件路径名(一个标准的C字符串) Face_index 某些字体格式允许把几个字体face嵌入到同一个文件中。 这个索引指示你想装载的face。 如果这个值太大,函数将会返回一个错误。Index 0总是正确的。 Face 一个指向新建的face对象的指针。 当失败时其值被置为NULL。 要知道一个字体文件包含多少个face,只要简单地装载它的第一个face(把face_index设置为0),face->num_faces的值就指示出了有多少个face嵌入在该字体文件中。 b.从内存装载 如果你已经把字体文件装载到内存,你可以简单地使用FT_New_Memory_Face为它新建一个face对象,如下所示: FT_Library library; /* 库的句柄 */ FT_Face face; /* face对象的句柄 */ error = FT_Init_FreeType( &library ); if ( error ) { ... } error = FT_New_Memory_Face( library, buffer, /* 缓存的第一个字节 */ size, /* 缓存的大小(以字节表示) */ 0, /* face索引 */ &face ); if ( error ) { ... } 如你所看到的,FT_New_Memory_Face简单地用字体文件缓存的指针和它的大小(以字节计算)代替文件路径。除此之外,它与FT_New_Face的语义一致。 c.从其他来源装载(压缩文件,网络,等) 使用文件路径或者预装载文件到内存是简单的,但还不足够。FreeType 2可以支持通过你自己实现的I/O程序来装载文件。 这是通过FT_Open_Face函数来完成的。FT_Open_Face可以实现使用一个自定义的输入流,选择一个特定的驱动器来打开,乃至当创建该对象时传递外部参数给字体驱动器。我们建议你查阅“FreeType 2参考手册”,学习如何使用它。 4.访问face内容 一个face对象包含该face的全部全局描述信息。通常的,这些数据可以通过分别查询句柄来直接访问,例如face->num_glyphs。 FT_FaceRec结构描述包含了可用字段的完整列表。我们在这里详细描述其中的某些: Num_glyphs 这个值给出了该字体face中可用的字形(glyphs)数目。简单来说,一个字形就是一个字符图像。但它不一定符合一个字符代码。 Flags 一个32位整数,包含一些用来描述face特性的位标记。例如,标记FT_FACE_FLAG_SCALABLE用来指示该face的字体格式是 可伸缩并且该字形图像可以渲染到任何字符象素尺寸。要了解face标记的更多信息,请阅读“FreeType 2 API 参考”。 Units_per_EM 这个字段只对可伸缩格式有效,在其他格式它将会置为0。它指示了EM所覆盖的字体单位的个数。 Num_fixed_size 这个字段给出了当前face中嵌入的位图的个数。简单来说,一个strike就是某一特定字符象素尺寸下的一系列字形图像。例如,一个字体face可以包含象素尺寸为10、12和14的strike。要注意的是即使是可伸缩的字体格式野可以包含嵌入的位图! Fixed_sizes 一个指向FT_Bitmap_Size成员组成的数组的指针。每一个FT_Bitmap_Size指示face中的每一个strike的水平和垂直字符象素尺寸。 注意,通常来说,这不是位图strike的单元尺寸。 5.设置当前象素尺寸 对于特定face中与字符大小相关的信息,FreeType 2使用size对象来构造。例如,当字符大小为12点时,使用一个size对象以1/64象素为单位保存某些规格(如ascender或者文字高度)的值。 当FT_New_Face或它的亲戚被调用,它会自动在face中新建一个size对象,并返回。该size对象可以通过face->size直接访问。 注意:一个face对象可以同时处理一个或多个size对象,但只有很少程序员需要用到这个功能,因而,我们决定简化该API,(例如,每个face对象只拥有一个size对象)但是这个特性我们仍然通过附加的函数提供。 当一个新的face对象建立时,对于可伸缩字体格式,size对象默认值为字符大小水平和垂直均为10象素。对于定长字体格式,这个大小是未定义的,这就是你必须在装载一个字形前设置该值的原因。 使用FT_Set_Char_Size完成该功能。这里有一个例子,它在一个300x300dpi设备上把字符大小设置为16pt。 error = FT_Set_Char_Size( face, /* face对象的句柄 */ 0, /* 以1/64点为单位的字符宽度 */ 16*64, /* 以1/64点为单位的字符高度 */ 300, /* 设备水平分辨率 */ 300 ); /* 设备垂直分辨率 */ 注意: * 字符宽度和高度以1/64点为单位表示。一个点是一个1/72英寸的物理距离。通常,这不等于一个象素。 * 设备的水平和垂直分辨率以每英寸点数(dpi)为单位表示。显示设备(如显示器)的常规值为72dpi或96dpi。这个分辨率是用来从字符点数计算字符象素大小的。 * 字符宽度为0意味着“与字符高度相同”,字符高度为0意味着“与字符宽度相同”。对于其他情况则意味着指定不一样的字符宽度和高度。 * 水平或垂直分辨率为0时表示使用默认值72dpi。 * 第一个参数是face对象的句柄,不是size对象的。 这个函数计算对应字符宽度、高度和设备分辨率的字符象素大小。然而,如果你想自己指定象素大小,你可以简单地调用FT_Set_Pixel_Sizes,就像这样: error = FT_Set_Pixel_Sizes( face, /* face对象句柄 */ 0, /* 象素宽度 */ 16 ); /* 象素高度 */ 这个例子把字符象素设置为16x16象素。如前所说的,尺寸中的任一个为0意味着“与另一个尺寸值相等”。 注意这两个函数都返回错误码。通常,错误会发生在尝试对定长字体格式(如FNT或PCF)设置不在face->fixed_size数组中的象素尺寸值。 6.装载一个字形图像 a.把一个字符码转换为一个字形索引 通常,一个应用程序想通过字符码来装载它的字形图像。字符码是一个特定编码中代表该字符的数值。例如,字符码64代表了ASCII编码中的’A’。 一个face对象包含一个或多个字符表(charmap),字符表是用来转换字符码到字形索引的。例如,很多TrueType字体包含两个字符 表,一个用来转换Unicode字符码到字形索引,另一个用来转换Apple Roman编码到字形索引。这样的字体既可以用在Windows(使用Unicode)和Macintosh(使用Apple Roman)。同时要注意,一个特定的字符表可能没有覆盖完字体里面的全部字形。 当新建一个face对象时,它默认选择 Unicode字符表。如果字体没包含Unicode字符表,FreeType会尝试在字形名的基础上模拟 一个。注意,如果字形名是不标准的那么模拟的字符表有可能遗漏某些字形。对于某些字体,包括符号字体和旧的亚洲手写字体,Unicode模拟是不可能的。 我们将在稍后叙述如何寻找face中特定的字符表。现在我们假设face包含至少一个Unicode字符表,并且在调用FT_New_Face时已经被选中。我们使用FT_Get_Char_Index把一个Unicode字符码转换为字形索引,如下所示: glyph_index = FT_Get_Char_Index( face, charcode ); 这个函数会在face里被选中的字符表中查找与给出的字符码对应的字形索引。如果没有字符表被选中,这个函数简单的返回字符码。 注意,这个函数是FreeType中罕有的不返回错误码的函数中的一个。然而,当一个特定的字符码在face中没有字形图像,函数返回0。按照约定,它对应一个特殊的字形图像――缺失字形,通常会显示一个框或一个空格。 b.从face中装载一个字形 一旦你获得了字形索引,你便可以装载对应的字形图像。在不同的字体中字形图像存储为不同的格式。对于固定尺寸字体格式,如FNT或者PCF,每一 个图像都是一个位图。对于可伸缩字体格式,如TrueType或者Type1,使用名为轮廓(outlines)的矢量形状来描述每一个字形。一些字体格 式可能有更特殊的途径来表示字形(如MetaFont――但这个格式不被支持)。幸运的,FreeType2有足够的灵活性,可以通过一个简单的API支 持任何类型的字形格式。 字形图像存储在一个特别的对象――字形槽(glyph slot)中。就如其名所暗示的,一个字形槽只是一个简单的容器,它一次只能容纳一个字形图像,可以是位图,可以是轮廓,或者其他。每一个face对象都 有一个字形槽对象,可以通过face->glyph来访问。它的字段在FT_GlyphSlotRec结构的文档中解释了。 通过调用FT_Load_Glyph来装载一个字形图像到字形槽中,如下: error = FT_Load_Glyph( face, /* face对象的句柄 */ glyph_index, /* 字形索引 */ load_flags ); /* 装载标志,参考下面 */ load_flags的值是位标志集合,是用来指示某些特殊操作的。其默认值是FT_LOAD_DEFAULT即0。 这个函数会设法从face中装载对应的字形图像: * 如果找到一个对应该字形和象素尺寸的位图,那么它将会被装载到字形槽中。嵌入的位图总是比原生的图像格式优先装载。因为我们假定对一个字形,它有更高质量的版本。这可以用FT_LOAD_NO_BITMAP标志来改变。 * 否则,将装载一个该字形的原生图像,把它伸缩到当前的象素尺寸,并且对应如TrueType和Type1这些格式,也会完成hinted操作。 字段face->glyph->format描述了字形槽中存储的字形图像的格式。如果它的值不是FT_GLYPH_FORMAT_BITMAP,你可以通过FT_Render_Glyph把它直接转换为一个位图。如下: error = FT_Render_Glyph( face->glyph, /* 字形槽 */ render_mode ); /* 渲染模式 */ render_mode参数是一个位标志集合,用来指示如何渲染字形图像。把它设为FT_RENDER_MODE_NORMAL渲染出一个高质量的抗锯齿(256级灰度)位图。这是默认情况,如果你想生成黑白位图,可以使用FT_RENDER_MODE_MONO标志。 一旦你生成了一个字形图像的位图,你可以通过glyph->bitmap(一个简单的位图描述符)直接访问,同时用glyph->bitmap_left和glyph->bitmap_top来指定起始位置。 要注意,bitmap_left是从字形位图当前笔位置到最左边界的水平距离,而bitmap_top是从笔位置(位于基线)到最高边界得垂直距离。他么是正数,指示一个向上的距离。 下一部分将给出字形槽内容的更多细节,以及如何访问特定的字形信息(包括度量)。 c.使用其他字符表 如前面所说的,当一个新face对象创建时,它会寻找一个Unicode字符表并且选择它。当前被选中的字符表可以通过 face->charmap访问。当没有字符表被选中时,该字段为NULL。这种情况在你从一个不含Unicode字符表的字体文件(这种文件现在 非常罕见)创建一个新的FT_Face对象时发生。 有两种途径可以在FreeType 2中选择不同的字符表。最轻松的途径是你所需的编码已经有对应的枚举定义在FT_FREETYPE_H中,例如FT_ENCODING_BIG5。在这种情况下,你可以简单地调用FT_Select_CharMap,如下: error = FT_Select_CharMap( face, /* 目标face对象 */ FT_ENCODING_BIG5 ); /* 编码 */ 另一种途径是手动为face解析字符表。这通过face对象的字段num_charmaps和charmaps(注意这是复数)来访问。如你想到 的,前者是face中的字符表的数目,后者是一个嵌入在face中的指向字符表的指针表(a table of pointers to the charmaps)。 每一个字符表有一些可见的字段,用来更精确地描述它,主要用到的字段是charmap->platform_id和charmap->encoding_id。这两者定义了一个值组合,以更普 通的形式用来描述该字符表。 每一个值组合对应一个特定的编码。例如组合(3,1)对应Unicode。组合列表定义在TrueType规范中,但你也可以使用文件FT_TRUETYPE_IDS_H来处理它们,该文件定义了几个有用的常数。 要选择一个具体的编码,你需要在规范中找到一个对应的值组合,然后在字符表列表中寻找它。别忘记,由于历史的原因,某些编码会对应几个值组合。这里是一些代码: FT_CharMap found = 0; FT_CharMap charmap; int n; for ( n = 0; n < face->num_charmaps; n++ ) { charmap = face->charmaps[n]; if ( charmap->platform_id == my_platform_id && charmap->encoding_id == my_encoding_id ) { found = charmap; break; } } if ( !found ) { ... } /* 现在,选择face对象的字符表*/ error = FT_Set_CharMap( face, found ); if ( error ) { ... } 一旦某个字符表被选中,无论通过FT_Select_CharMap还是通过FT_Set_CharMap,它都会在后面的FT_Get_Char_Index调用使用。 d.字形变换 当字形图像被装载时,可以对该字形图像进行仿射变换。当然,这只适用于可伸缩(矢量)字体格式。 简单地调用FT_Set_Transform来完成这个工作,如下: error = FT_Set_Transform( face, /* 目标face对象 */ &matrix, /* 指向2x2矩阵的指针 */ &delta ); /* 指向2维矢量的指针 */ 这个函数将对指定的face对象设置变换。它的第二个参数是一个指向FT_Matrix结 构的指针。该结构描述了一个2x2仿射矩阵。第三个参数是一个指向FT_Vector结构的指针。该结构描述了一个简单的二维矢量。该矢量用来在2x2变换后对字形图像平移。 注意,矩阵指针可以设置为NULL,在这种情况下将进行恒等变换。矩阵的系数是16.16形式的固定浮点单位。 矢量指针也可以设置为NULL,在这种情况下将使用(0, 0)的delta。矢量坐标以一个象素的1/64为单位表示(即通常所说的26.6固定浮点格式)。 注意:变换将适用于使用FT_Load_Glyph装载的全部字形,并且完全独立于任何hinting处理。这意味着你对一个12象素的字形进行2倍放大变换不会得到与24象素字形相同的结果(除非你禁止hints)。 如果你需要使用非正交变换和最佳hints,你首先必须把你的变换分解为一个伸缩部分和一个旋转/剪切部分。使用伸缩部分来计算一个新的字符象素大小,然后使用旋转/剪切部分来调用FT_Set_Transform。这在本教程的后面部分有详细解释。 同时要注意,对一个字形位图进行非同一性变换将产生错误。 7. 简单的文字渲染 现在我们将给出一个非常简单的例子程序,该例子程序渲染一个8位Latin-1文本字符串,并且假定face包含一个Unicode字符表。 该程序的思想是建立一个循环,在该循环的每一次迭代中装载一个字形图像,把它转换为一个抗锯齿位图,把它绘制到目标表面(surface)上,然后增加当前笔的位置。 a.基本代码 下面的代码完成我们上面提到的简单文本渲染和其他功能。 FT_GlyphSlot slot = face->glyph; /* 一个小捷径 */ int pen_x, pen_y, n; ... initialize library ... ... create face object ... ... set character size ... pen_x = 300; pen_y = 200; for ( n = 0; n < num_chars; n++ ) { FT_UInt glyph_index; /* 从字符码检索字形索引 */ glyph_index = FT_Get_Char_Index( face, text[n] ); /* 装载字形图像到字形槽(将会抹掉先前的字形图像) */ error = FT_Load_Glyph( face, glyph_index, FT_LOAD_DEFAULT ); if ( error ) continue; /* 忽略错误 */ /* 转换为一个抗锯齿位图 */ error = FT_Render_Glyph( face->glyph, ft_render_mode_normal ); if ( error ) continue; /* 现在,绘制到我们的目标表面(surface) */ my_draw_bitmap( &slot->bitmap, pen_x + slot->bitmap_left, pen_y - slot->bitmap_top ); /* 增加笔位置 */ pen_x += slot->advance.x >> 6; pen_y += slot->advance.y >> 6; /* 现在还是没用的 */ } 这个代码需要一些解释: * 我们定义了一个名为slot的句柄,它指向face对象的字形槽。(FT_GlyphSlot类型是一个指针)。这是为了便于避免每次都使用face->glyph->XXX。 * 我们以slot->advance增加笔位置,slot->advance符合字形的步进宽度(也就是通常所说的走格(escapement))。步进矢量以象素的1/64为单位表示,并且在每一次迭代中删减为整数象素。 * 函数my_draw_bitmap不是FreeType的一部分,但必须由应用程序提供以用来绘制位图到目标表面。在这个例子中,该函数以一个FT_Bitmap描述符的指针和它的左上角位置为参数。 * Slot->bitmap_top的值是正数,指字形图像顶点与pen_y的垂直距离。我们假定my_draw_bitmap采用的坐标使用一样的约定(增加Y值对应向下的扫描线)。我们用pen_y减它,而不是加它。 b.精练的代码 下面的代码是上面例子程序的精练版本。它使用了FreeType 2中我们还没有介绍的特性和函数,我们将在下面解释: FT_GlyphSlot slot = face->glyph; /* 一个小捷径 */ FT_UInt glyph_index; int pen_x, pen_y, n; ... initialize library ... ... create face object ... ... set character size ... pen_x = 300; pen_y = 200; for ( n = 0; n < num_chars; n++ ) { /* 装载字形图像到字形槽(将会抹掉先前的字形图像) */ error = FT_Load_Char( face, text[n], FT_LOAD_RENDER ); if ( error ) continue; /* 忽略错误 */ /* 现在,绘制到我们的目标表面(surface) */ my_draw_bitmap( &slot->bitmap, pen_x + slot->bitmap_left, pen_y - slot->bitmap_top ); /* 增加笔位置 */ pen_x += slot->advance.x >> 6; } 我们简化了代码的长度,但它完成相同的工作: * 我们使用函数FT_Loac_Char代替FT_Load_Glyph。如你大概想到的,它相当于先调用GT_Get_Char_Index然后调用FT_Get_Load_Glyph。 * 我们不使用FT_LOAD_DEFAULT作为装载模式,使用FT_LOAD_RENDER。它指示了字形图像必须立即转换为一个抗锯齿位图。这是一个捷径,可以取消明显的调用FT_Render_Glyph,但功能是相同的。 注意,你也可以指定通过附加FT_LOAD_MONOCHROME装载标志来获得一个单色位图。 c.更高级的渲染 现在,让我们来尝试渲染变换文字(例如通过一个环)。我们可以用FT_Set_Transform来完成。这里是示例代码: FT_GlyphSlot slot; FT_Matrix matrix; /* 变换矩阵 */ FT_UInt glyph_index; FT_Vector pen; /* 非变换原点 */ int n; ... initialize library ... ... create face object ... ... set character size ... slot = face->glyph; /* 一个小捷径 */ /* 准备矩阵 */ matrix.xx = (FT_Fixed)( cos( angle ) * 0x10000L ); matrix.xy = (FT_Fixed)(-sin( angle ) * 0x10000L ); matrix.yx = (FT_Fixed)( sin( angle ) * 0x10000L ); matrix.yy = (FT_Fixed)( cos( angle ) * 0x10000L ); /* 26.6 笛卡儿空间坐标中笔的位置,以(300, 200)为起始 */ pen.x = 300 * 64; pen.y = ( my_target_height - 200 ) * 64; for ( n = 0; n < num_chars; n++ ) { /* 设置变换 */ FT_Set_Transform( face, &matrix, &pen ); /* 装载字形图像到字形槽(将会抹掉先前的字形图像) */ error = FT_Load_Char( face, text[n], FT_LOAD_RENDER ); if ( error ) continue; /* 忽略错误 */ /* 现在,绘制到我们的目标表面(变换位置) */ my_draw_bitmap( &slot->bitmap, slot->bitmap_left, my_target_height - slot->bitmap_top ); /* 增加笔位置 */ pen.x += slot->advance.x; pen.y += slot->advance.y; } 一些说明: * 现在我们使用一个FT_Vector类型的矢量来存储笔位置,其坐标以象素的1/64为单位表示,并且倍增。该位置表示在笛卡儿空间。 * 不同于系统典型的对位图使用的坐标系(其最高的扫描线是坐标0),FreeType中,字形图像的装载、变换和描述总是采用笛卡儿坐标系(这意味着增加Y对应向上的扫描线)。因此当我们定义笔位置和计算位图左上角时必须在两个系统之间转换。 * 我们对每一个字形设置变换来指示旋转矩阵以及使用一个delta来移动转换后的图像到当前笔位置(在笛卡儿空间,不是位图空间)。结 果,bitmap_left和bitmap_top的值对应目标空间象素中的位图原点。因此,我们在调用my_draw_bitmap时不在它们的值上加 pen.x或pen.y。 * 步进宽度总会在变换后返回,这就是它可以直接加到当前笔位置的原因。注意,这次它不会四舍五入。 一个例子完整的源代码可以在这里找到。 要很注意,虽然这个例子比前面的更复杂,但是变换效果是完全一致的。因此它可以作为一个替换(但更强大)。 然而该例子有少许缺点,我们将在本教程的下一部分中解释和解决。 结论 在这个部分,你已经学习了FreeType2的基础以及渲染旋转文字的充分知识。 下一部分将深入了解FreeType 2 API更详细的资料,它可以让你直接访问字形度量标准和字形图像,还能让你学习到如何处理缩放、hinting、自居调整,等等。 第三部分将讨论模块、缓存和其他高级主题,如如何在一个face中使用多个尺寸对象。【这部分还没有编写】 |
|
|
|
----
良好的沟通能力 和 积极的行动 是成功的钥匙。
|
||
| [Original][Print] [Top] | ||
| Subject: Re: FreeType 2开发文档 [中译版] Author: gogoliu Posted: 2006-03-13 23:39 Length:37,333 byte(s) |
|||||
| [Original][Print] [Top] | |||||
| 《The FreeType 2 Tutorial》第二部分中译版
对于垂直文本排列,基线是垂直的,与垂直轴一致:
|
|||||