MySql面试笔记
文章目录
-
- MySql
-
- 索引的分类
- B树与B+树
-
- B树
- B+树
- 面试常见问题
- 四大特性
-
- 隔离级别
-
- 快照读和当前读
- MVCC
- binlog
- redolog
- undolog
- 锁
-
- 锁的粒度
- 乐观锁
- 悲观锁
-
- 锁的分类
- 共享锁
- 排他锁
- 行锁
-
- 间隙锁
- 表锁
- 死锁
- 面试常见问题
- 分析
-
- 分析行锁定
MySql
索引的分类
1️⃣从存储结构上来划分:BTree索引(B-Tree索引或B+Tree索引),Hash索引,Full-Index全文索引,R-Tree索引
2️⃣从应用层次来分:普通索引,唯一索引,复合索引
3️⃣根据数据的物理顺序与键值的逻辑顺序关系:聚集索引,非聚集索引
B树与B+树
B树
B-Tree能加快数据的访问速度,因为存储引擎不再需要进行全表扫描来获取数据,数据分布在各个节点之中。

B+树
是B-Tree的改进版本,同时也是数据库索引索引所采用的存储结构。数据都在叶子节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree需要获取所有节点,相比之下B+Tree效率更高。
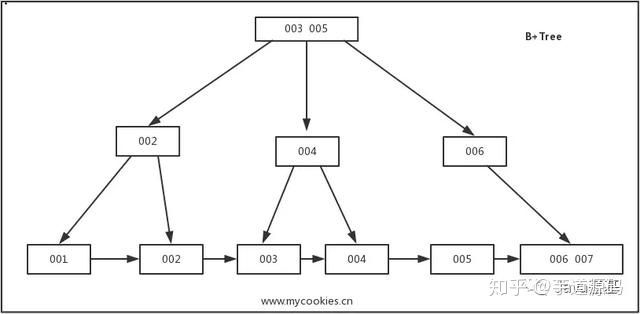
从上面分析可以看到,无论是B还是B+树,出度d越大,索引性能越好,而出度的上限取决于节点内key和data的大小
面试常见问题
- 问:Innodb使用B+树而不使用B树的原因
先从数据结构的角度来答: 应该知道B-树和B+树最重要的一个区别就是B+树只有叶节点存放数据,其余节点用来索引,而B-树是每个索引节点都会有Data域。这就决定了B+树更适合用来存储外部数据,也就是所谓的磁盘数据。
从Mysql(Inoodb)的角度来:B+树是用来充当索引的,一般来说索引非常大,尤其是关系性数据库这种数据量大的索引能达到亿级别,所以为了减少内存的占用,索引也会被存储在磁盘上。
那么Mysql如何衡量查询效率呢?磁盘IO次数。B-树(B类树)的特点就是每层节点数目非常多,层数很少,目的就是为了就少磁盘IO次数,当查询数据的时候,最好的情况就是很快找到目标索引,然后读取数据,使用B+树就能很好的完成这个目的,但是B-树的每个节点都有data域(指针),这无疑增大了节点大小,说白了增加了磁盘IO次数(磁盘IO一次读出的数据量大小是固定的,单个数据变大,每次读出的就少,IO次数增多,一次IO多耗时啊!),而B+树除了叶子节点其它节点并不存储数据,节点小,磁盘IO次数就少。这是优点之一。
另一个优点是什么,B+树所有的Data域在叶子节点,一般来说都会进行一个优化,就是将所有的叶子节点用指针串起来。这样遍历叶子节点就能获得全部数据,这样就能进行区间访问啦。(数据库索引采用B+树的主要原因是 B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低))至于MongoDB为什么使用B-树而不是B+树,可以从它的设计角度来考虑,它并不是传统的关系性数据库,而是以Json格式作为存储的nosql,目的就是高性能,高可用,易扩展。首先它摆脱了关系模型,上面所述的优点2需求就没那么强烈了,其次Mysql由于使用B+树,数据都在叶节点上,每次查询都需要访问到叶节点,而MongoDB使用B-树,所有节点都有Data域,只要找到指定索引就可以进行访问,无疑单次查询平均快于Mysql(但侧面来看Mysql至少平均查询耗时差不多)。
总体来说,Mysql选用B+树和MongoDB选用B-树还是以自己的需求来选择的。
B树相对于红黑树的区别在大规模数据存储的时候,红黑树往往出现由于树的深度过大而造成磁盘IO读写过于频繁,进而导致效率低下的情况。为什么会出现这样的情况,我们知道要获取磁盘上数据,必须先通过磁盘移动臂移动到数据所在的柱面,然后找到指定盘面,接着旋转盘面找到数据所在的磁道,最后对数据进行读写。磁盘IO代价主要花费在查找所需的柱面上,树的深度过大会造成磁盘IO频繁读写。根据磁盘查找存取的次数往往由树的高度所决定,所以,只要我们通过某种较好的树结构减少树的结构尽量减少树的高度,B树可以有多个子女,从几十到上千,可以降低树的高度。
- 问:为什么索引结构默认使用B-Tree,而不是hash,二叉树,红黑树?
hash:虽然可以快速定位,但是没有顺序,IO复杂度高。
二叉树:树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且IO代价高。
红黑树:树的高度随着数据量增加而增加,IO代价高。
- 问:为什么官方建议使用自增长主键作为索引?
结合B+Tree的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率。
- 问:聚集索引和非聚集索引的区别?
聚集索引和非聚集索引都是B+树的形式,只不过聚集索引(主键)的叶子节点存放了整行的数据;而非聚集索引(如复合、前缀、唯一索引)则存放的是主键。
四大特性
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WfzkFIjq-1595987772314)(C:\Users\卢本伟\AppData\Roaming\Typora\typora-user-images\1591275546851.png)]
- 事务的原子性是通过undolog实现的
- 事务的持久性是通过redolog实现的
- 事务的隔离性是通过 读写锁+MVCC 来实现的
- 事务的一致性是通过原子性、持久性、隔离性来实现的
隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 可能 | 可能 | 可能 |
| 读已提交 | 不可能 | 可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | 通过MVCC、间隙锁&临键锁解决读数据情况下的幻读,修改数据下的幻读未解决 |
| 串行话 | 不可能 | 不可能 | 不可能 |
不同事务隔离级别,其实是一致性和并发性的一种权衡与折衷
快照读和当前读
在RR级别中,通过MVCC机制,虽然让数据变得可重复读,但我们读到的数据可能是历史数据,不是数据库最新的数据。这种读取历史数据的方式,我们叫它快照读 (snapshot read),而读取数据库最新版本数据的方式,叫当前读 (current read)。
- select 快照读
当执行select操作是innodb默认会执行快照读,会记录下这次select后的结果,之后select 的时候就会返回这次快照的数据,即使其他事务提交了不会影响当前select的数据,这就实现了可重复读了。快照的生成当在第一次执行select的时候,也就是说假设当A开启了事务,然后没有执行任何操作,这时候B insert了一条数据然后commit,这时候A执行 select,那么返回的数据中就会有B添加的那条数据。之后无论再有其他事务commit都没有关系,因为快照已经生成了,后面的select都是根据快照来的。
- 当前读
对于会对数据修改的操作(update、insert、delete)都是采用当前读的模式。在执行这几个操作时会读取最新的记录,即使是别的事务提交的数据也可以查询到。假设要update一条记录,但是在另一个事务中已经delete掉这条数据并且commit了,如果update就会产生冲突,所以在update的时候需要知道最新的数据。也正是因为这样所以才导致上面我们测试的那种情况。
select的当前读需要手动加锁:
select * from table where ? lock in share mode;
select * from table where ? for update;
MVCC
这就是Mysql的MVCC,通过版本链,实现多版本,可并发读-写,写-读。通过ReadView生成策略的不同实现不同的隔离级别。
怎么通过MVCC实现并发读-写呢,假如现在有A事务在修改数据,暂未提交,此时有B事务读取数据,正常A事务会上排他锁,不运行其他事务读取,现在有了MVCC,B事务也可以读取到,不过读取到的是A事务未修改前的数据,因为事务A的版本号虽然小于事务B,但是B事务的SELECT起来的时候,在全局维护的一个当前事务ID中发现了事务A,所以不能够读取事务A修改后的数据,只能读取修改前的数据,因此实现了可并发读-写。
binlog
redolog
redolog的存在是为了:当我们修改数据的时候,写完内存了,但数据还没真正落到磁盘的时候,此时我们的数据库挂了,我们可以根据redolog来对数据进行恢复,流程如下图
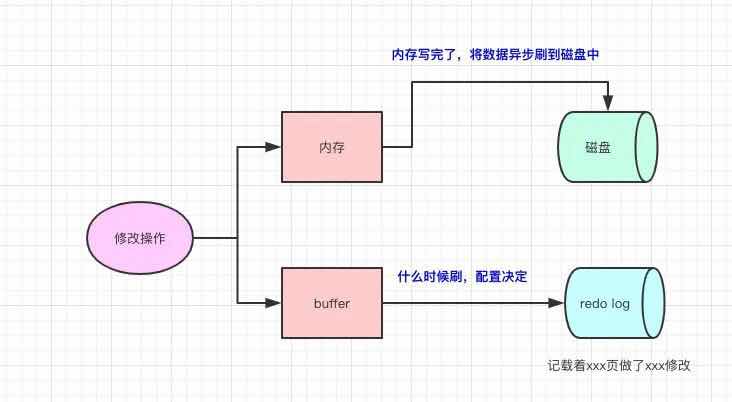
优点:写入redolog是顺序I/O,所以写入速度很快,并且redolog记载的是物理变化(xxx页做了xxx修改),文件的体积很小,恢复的速度很快
需要记住的是如果我们内存的数据已经刷到了磁盘,那redolog的数据就无效了。所以redolog不会存储着历史所有数据的变更,文件的内容会被覆盖
undolog
锁
锁的粒度
行级锁、页级锁、表级锁
乐观锁
用数据版本(Version)记录机制实现,这是乐观锁最常用的一种实现方式。何谓数据版本?即为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加1。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据。
悲观锁
锁的分类
- 共享锁(简称S锁,属于行锁)
- 排他锁(简称X锁,属于h行锁)
- 意向共享锁intention Shared Locks (简称IS锁,属于表锁)
- 意向排他锁intention Exclusive Locks (简称IX锁,属于表锁)
- 自增锁 AUTO-INC Locks
共享锁
共享锁就是指多个事务对于同一数据可以共享一把锁,都能访问数据库,但是只能读不能修改。
//事务A
select * from student where id = 1 lock in share mode;
//事务B
select * from student where id = 1 lock in share mode;
//事务B
update student set name = 'heihei' where id = 1; //无法修改,阻塞直到事务A提交事务才可修改成功
排他锁
排他锁不能和其他锁并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的锁,只有当前事务才能对数据进行读取或修改
//事务A
select * from student where id = 1 for update;
//事务B
select * from student where id = 1 for update;
select * from student where id = 1 lock in share mode;
事务B阻塞,直到事务A提交事务才会运行
行锁
- InnoDB的行锁是针对索引加的锁,不是针对记录加的锁。并且该索引不能失效,否则都会从行锁升级为表锁。行级锁都是基于索引的,如果一条SQL语句用不到索引是不会使用行级锁的,会使用表级锁。
- 行锁的劣势:相对于表锁开销大;加锁慢;会出现死锁
- 行锁的优势:锁的粒度小,发生锁冲突的概率低;处理并发的能力强
- 加锁的方式:自动加锁。对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁;对于普通SELECT语句,InnoDB不会加任何锁;当然我们也可以显示的加锁
行锁变表锁似乎是一个坑,可MySQL没有这么无聊给你挖坑。这是因为MySQL有自己的执行计划。 当你需要更新一张较大表的大部分甚至全表的数据时。而你又傻乎乎地用索引作为检索条件。一不小心开启了行锁(没毛病啊!保证数据的一致性!)。可MySQL却认为大量对一张表使用行锁,会导致事务执行效率低,从而可能造成其他事务长时间锁等待和更多的锁冲突问题,性能严重下降。所以MySQL会将行锁升级为表锁,即实际上并没有使用索引。 我们仔细想想也能理解,既然整张表的大部分数据都要更新数据,在一行一行地加锁效率则更低。其实我们可以通过explain命令查看MySQL的执行计划,你会发现key为null。表明MySQL实际上并没有使用索引,行锁升级为表锁也和上面的结论一致。
间隙锁
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。
举例子,假如table表中只有101条记录,其id的值分别是1,2,…,100,101,下面是SQL:
select * from table where id > 100 for update;
这是一个范围条件的检索,InnoDB不仅会对符合条件的id值为101的记录加锁,也会对id大于101(这些记录并不存在)的“间隙”加锁。使用间隙锁的目的:一方面是防止幻读,以满足相关隔离级别的要求;二是为了满足其恢复和复制的需要。
还要特别说明的是,InnoDB除了通过范围条件加锁时使用间隙锁外,如果使用相等条件请求给一个不存在的记录加锁,InnoDB也会使用间隙锁。举个例子,假如table表中只有101条记录,其id的值分别是1,2,…,100,101,下面是SQL:
事务1:
select * from emp where empid = 102 for update;
事务2:
insert into emp(empid,...) values(201,...); //阻塞等待
所以,根据上面的几种情况,要知道若执行的条件是范围过大,则InnoDB会将整个范围内所有的索引键值全部锁定,很容易对性能造成影响。
表锁
只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
死锁
降低死锁的概率:
- 按同一顺序访问对象。
- 避免事务中的用户交互。
- 保持事务简短并在一个批处理中。
- 使用低隔离级别。
- 使用绑定连接。
面试常见问题
-
问:update时锁粒度情况
分两种情况:
一种带索引:行锁
一种不带索引:表锁
主要看有没有使用到索引
-
问:什么场景下用表锁
第一种情况:全表更新。事务需要更新大部分或全部数据,且表又比较大。若使用行锁,会导致事务执行效率低,从而可能造成其他事务长时间锁等待和更多的锁冲突。
第二种情况:多表查询。事务涉及多个表,比较复杂的关联查询,很可能引起死锁,造成大量事务回滚。这种情况若能一次性锁定事务涉及的表,从而可以避免死锁、减少数据库因事务回滚带来的开销。
第三种情况:属性值重复率高。当“值重复率”高时,MySQL 不会把这个“普通索引”当做索引,即造成了一个没有索引的 SQL,此时引发表锁。
分析
分析行锁定
通过检查InnoDB_row_lock状态变量分析系统中行锁的争夺情况
mysql> show status like 'innodb_row_lock';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 0 |
| Innodb_row_lock_time_avg | 0 |
| Innodb_row_lock_time_max | 0 |
| Innodb_row_lock_waits | 0 |
+-------------------------------+-------+
- innodb_row_lock_current_waits: 当前正在等待锁定的数量
- innodb_row_lock_time: 从系统启动到现在锁定总时间长度;非常重要的参数,
- innodb_row_lock_time_avg: 每次等待所花平均时间;非常重要的参数,
- innodb_row_lock_time_max: 从系统启动到现在等待最常的一次所花的时间;
- innodb_row_lock_waits: 系统启动后到现在总共等待的次数;非常重要的参数。直接决定优化的方向和策略。