FER基于卷积神经网络: 处理少量数据和训练样本订单FER with CNN:Coping with few data and the training sample order
1.摘要
面部表情识别在过去的10年中一直是一个活跃的研究领域,其应用领域不断扩大,包括阿凡达动画、神经营销和社交机器人。面部表情的识别对于机器学习方法来说不是一个简单的问题,因为人们表现表情的方式可能会有很大的差异。即使是同一个人面部表情相同的图像,其亮度、背景和姿势也可能不同,如果考虑到不同的主题(由于形状、种族等方面的差异),这些变化会得到强调。虽然在文献中对人脸表情识别的研究非常多,但是在训练和测试所提出的算法的同时,很少有研究能够避免混合对象进行公平的评价。人脸表情识别一直是计算机视觉领域的一个难题。在这项工作中,我们提出了一个简单的面部表情识别的解决方案,它结合了卷积神经网络和特定的图像预处理步骤。卷积神经网络利用大数据实现了更高的精度。然而,目前还没有一个具有足够数据集的公共数据集可以用于深度架构的面部表情识别。因此,为了解决这一问题,我们采用了一些预处理技术,仅从人脸图像中提取特定的表情特征,并在训练过程中探索样本的表示顺序。实验用来评估我们的技术进行了使用三个主要使用公共数据库(CKþ,JAFFE和BU-3DFE)。研究了各预处理操作对图像正确率的影响。该方法:达到竞争结果相比与其他面部表情识别方法——96.76%的准确性CK+数据库——这是快速训练,和它允许实时面部表情识别与标准电脑。
1. 介绍(Introduction)
面部表情是人类情感识别的重要特征之一。它是由达尔文在他的书《人类和动物情感的表达》中第一次提到。根据Li和Jain[3]的说法,面部表情可以被定义为对一个人内在情绪状态、意图或社会交流做出的反应。目前,人脸表情自动识别有着广泛的应用,如数据驱动动画、神经营销、交互游戏、社交机器人等许多人机交互系统。根据Li和Jain[3]的说法,面部表情可以被定义为对一个人内在情绪状态、意图或社会交流做出的反应。目前,人脸表情自动识别有着广泛的应用,如数据驱动动画、神经营销、交互游戏、社交机器人等许多人机交互系统。文献中的许多工作并没有采用统一的评价方法(例如在训练和测试中没有科目重叠),因此呈现出误导的高准确度,但并不能代表大多数人脸表情识别问题的真实场景。另一方面,关于环境不受控制的数据库和跨数据库评估的准确性较低。为了克服这些限制,一些研究工作已经尝试使计算机达到与人类相同的精度,下面将重点介绍其中的一些例子:这个问题对于计算机来说仍然是一个挑战,因为很难将表情的特征空间分离开来,即两个不同表情中的人脸特征可能在特征空间中非常接近,而面部特征则来自两个表情相同的受试者也许彼此很远。此外,一些表达式像例如,“悲伤”和“恐惧”在某些情况下非常相似 。

图1显示了三个表情愉快的受试者。从图中可以看出,图像之间的差异很大,不仅表现在被摄者的表达方式上,还表现在灯光、亮度、姿态和背景上。这个图还举例说明了另一个与面部表情识别相关的挑战,即不受控制的训练测试场景(训练图像与测试图像在环境条件和受试者种族方面可能有很大的不同)。评估这些场景下人脸表情识别的一种方法是用一个数据库训练该方法,然后用另一个数据库(可能来自不同的民族)测试该方法。我们按照这种方法给出结果。面部表情识别系统主要分为两大类:一类是静态图像识别系统[7-13],另一类是动态图像序列识别系统[14-17]。基于静态的方法不使用时间信息,即特征向量只包含当前输入图像的信息。另一方面,基于序列的方法使用图像的时间信息来识别从一个或多个帧捕获的表达式。面部表情识别的自动化系统接收预期的输入(静态图像或图像序列),通常输出六个基本表情之一(例如,愤怒、悲伤、惊讶、高兴、厌恶和恐惧);一些系统也能识别自然性表达。这项工作将侧重于基于静态图像的方法,并将考虑六和七个表达式集(6个基本加中性),用于受控和非受控场景。如Li和Jain[3]所述,面部表情自动分析包括三个步骤:面部采集、面部数据提取和表示、面部表情识别。人脸采集主要分为两个步骤:人脸检测[18-21]和头位姿估计[22-24]。人脸采集后,需要提取面部表情引起的面部变化。这些变化通常使用基于几何特征的方法[25 - 27,21]或基于外观的方法[25,8 -]来提取11,28,13)。提取的特征通常用向量表示,称为特征向量。基于几何特征的方法处理的是嘴巴、眼睛、鼻子和眉毛等面部特征的形状和位置。表示人脸几何的特征向量由人脸成分或人脸特征点组成。基于外观的方法使用从整个面部或特定区域提取的特征向量;这些特征向量是通过应用于整个人脸图像[3]的图像滤波器获得的。一旦有了与面部表情相关的特征向量,就可以进行表情识别。Liu等人[7]认为,表情识别系统基本上采用了三种训练过程:特征学习、特征选择和分类器构建,顺序如下。特征学习阶段负责提取与面部表情相关的所有特征。特征选择选择最能代表面部表情的特征。在最大限度地增加类间变化的同时,应尽量减少表达式的类内变化[8]。最小化表达式的类内变化是一个问题,因为具有相同表达式的不同个体的图像在像素空间中相距很远。最大化类间差异也很困难,因为同一个人在不同表达式中的图像可能在像素空间[29]中非常接近。在整个过程的最后,根据所选择的特征,使用一个分类器(或一组分类器,每个表情对应一个分类器)来推断面部表情。深度多层神经网络是成功应用于人脸表情识别问题的技术之一[30-32,14,10,11,13]。该技术包括面部表情识别的三个步骤(特征的学习、选择和分类)。近十年来,神经网络的研究一直致力于寻找一种训练深层多层神经网络(即具有一层或两层以上隐层的网络)的方法,以提高其精度。根据Bengio[35]的说法,直到2006年,许多新的尝试都收效甚微。卷积神经网络(Convolutional Neural Networks, CNNs)是Lecun等人在1998年提出的,虽然有些陈旧。当使用更深层次的体系结构(即具有许多层)和新的培训技术时,[36]在学习具有高抽象级别的特性方面表现得非常有效。一般来说,这种层次网络具有交替的层类型,包括卷积层、子采样层和完全连接层。卷积层的特征是内核的大小和生成的映射的数量。内核在生成一个映射的输入图像的有效区域上移动。子采样层通过减小映射大小[37]来增加内核的位置不变性。子采样层通过减小映射大小[37]来增加内核的位置不变性。子采样层的主要类型是最大池和平均池[37]。CNN的全连接层与一般神经网络的全连接层相似,其神经元与前一层完全连接(一般为卷积层、子采样层甚至全连通层)。(一般为卷积层、子采样层甚至全连通层)。神经网络的学习过程包括寻找最佳突触的权重。监督学习可以使用梯度下降法,CNN的主要优势之一是,模型的输入是原始图像,而不是一组手工编码的特性。除了使用深度架构的方法外,文献中还有很多其他的方法,但是这些方法的评估的一些方面仍然值得关注。例如,验证方法可以在[38-42,30,10]中进行改进,以考虑测试集中的受试者不在训练集中的情况(即没有受试者重叠的测试),在[38,1,43,44],可以提高[7,43,16]中的识别时间,以便进行实时评价。试图应对这些限制,同时保持一个简单的解决方案,在这篇文章中,我们提出一个深度学习方法结合标准方法,如图像的标准化,合成训练样本生成(例如,真实图像和人工旋转、平移和缩放)和卷积神经网络,成一个简单的解决方案,可以实现非常高的准确率96.76% CK+数据库6表达式,即国家将最新。与文献及整体方法相比,训练时间明显缩短。我们已经使用扩展的方法检查了系统的性能Cohn-Kanade (CKþ)数据库[4],日本女性面部表情(JAFFE)数据库[5]和宾厄姆顿大学3 d[6]面部表情(BU-3DFE)数据库,实现更好的准确性CK+数据库,它包含更多的样本深度学习技术(重要)比JAFFE和BU-3DFE数据库。此外,我们还执行了广泛的验证,包括跨数据库测试(即使用一个数据库培训方法,并使用另一个数据库评估方法的准确性)。总之,这项工作的主要贡献是:
一、一种实时有效的面部表情识别方法;
二、图像预处理在人脸表情识别中的应用研究
三、一套人脸归一化(空间和强度)的预处理操作,以减少对受控环境的需求和处理数据的缺乏;
四、一项研究,以处理训练期间样本的呈现顺序所导致的准确性变化;
五、研究不同文化和环境下的系统性能(跨数据库评估)。
这项工作扩展了在第28西卜拉比中提出的(图形、图案和图像会议)如下:
一、深入文献综述,扩大结果对比;
二、结果介绍了使用一个新的实现基于不同的框架(从事先,基于Matlab实现[46],咖啡,一个Cþþ基础实现
,从而将总训练时间减少了近四倍;
三、结果显示,识别时间减少,现在是实时的;
四、由于训练时间较长,方法变化较小(见下文),结果显示准确率较高;
五、包括改进的实验方法,如使用训练、验证和测试集,而不是只使用训练和测试集;
六、它提供了包括跨数据库测试在内的更完整的评估
方法上的改变使精确度提高如下:
a.合成样本的生成过程略有不同,使得它们之间的变化较大(现在合成样本可以是旋转、缩放或平移的原始图像,而不只是旋转);
b.我们增加了合成样品的数量,从30个增加到70个(由上一项所激发);
c.逻辑回归损失函数被SoftmaxWithLoss函数替换(在第3节中描述)。
本文的其余部分组织如下:下一节介绍最新的相关工作,第3节描述所提议的方法。在第四章中,我们做了一些实验来评估我们的系统,并与最近的几种面部表情识别方法进行了比较。
最后,我们在第5节中总结。
2. 相关工作(Related work)
近几十年来,随着识别性能的不断提高,人脸表情识别方法得到了广泛的发展。最近这一进展的一个重要部分是由于深度学习方法的出现而取得的[7,10,12],更具体地说是卷积神经网络[14,11],这是一种深度学习方法。这些方法之所以成为可行,是因为:现在有大量的数据可用来训练学习方法,以及在这方面的进步。前者对于具有深度体系结构的训练网络至关重要,而后者对于训练过程所需的低成本高性能数值计算至关重要。面部表情识别研究的综述可在[3,48]中找到。
最近的一些面部表情识别方法主要集中在不受控制的环境中(如非正面人脸、图像部分重叠、自发表情等),这仍然是一个具有挑战性的问题[12,49,50]。BDBN由一组分类器组成,作者将其命名为弱分类器。每个弱分类器负责对一个表达式进行分类。他们的方法在一个独特的框架内迭代执行三个学习阶段(特征学习、特征选择和分类器构建)。他们的实验使用了两个静态图像的公共数据库Cohn -Kanade[4]和JAFFE[51]的检测准确率分别为96.7%和96.7%、91.8%,分别。他们也进行实验控制的场景中,使用跨数据库配置(训练CK+在JAFFE上测试),取得了68.0%的准确性。所有图像首先根据给定的眼坐标进行预处理,即进行对齐和裁剪。训练和测试采用的是一个对所有的分类策略,即对每个表达式使用一个二进制分类器。训练网络需要大约8天的时间。将识别结果作为弱分类器的函数进行计算。将识别结果作为弱分类器的函数进行计算。在他们的方法中,他们使用6或7个分类器,这取决于要识别的表达式的数量(每个表达式一个)。每个分类器需要30 ms来识别每个表达式,总的识别时间约为0.21 s。识别时间由作者报告使用6核2.4 GHz PC。
Song等人开发了一个面部表情识别系统,该系统使用深度卷积神经网络,在智能手机上运行。该网络由五层和6.5万个神经元。作者认为,在使用少量训练数据和如此庞大的网络时,过度拟合是很常见的。因此,作者采用数据增强技术来增加训练数据量,并在网络训练中使用了drop-out[52]。实验使用CK+[4]数据集,和其他三个作者创建的数据集。CK+数据集的图像首先出现关注区域包含面部变化引起的一个表达式。作者的实验遵循一个10倍交叉验证,但他们没有提到是否有相同主题的图像在一个以上的折叠。因此,我们假设训练集和测试集中的受试者之间存在重叠。CK+数据库中实现99.2%的准确性而认识到只有五个表达式(愤怒、高兴、悲伤、惊讶和中性)。
Burkert等人也提出了一种基于卷积神经网络的方法。作者声称他们的方法独立于任何手工特征提取(即使用原始图像作为输入)。作者声称他们的方法独立于任何手工特征提取(即使用原始图像作为输入)。他们的网络架构由四个部分组成。第一部分负责数据的自动预处理,其余部分进行特征提取。所提取的特征由网络末端的全连通层划分为一个给定的表达式。
建议的架构包括15层(7个卷积层,5个池化层,2个全连接层,1个归一化层)。他们评估方法与CK+数据库和MMI数据库,分别实现99.6%和98.63%的准确性。尽管准确性很高,但在他们的实验方法中,他们并不能保证用于训练的对象不会用于测试。正如我们将在第4节中讨论的,这是一个重要的限制,为了对面部表情识别方法进行公正的评估,应该实施这一限制[44,53]。
Liu等人为了探索表情可以分解为多个面部表情动作单元的心理学理论,[12]提出了一个动作单元(action unit, AU)激发深层网络(deep networks, AUDN)。作者声称该方法能够学习:
(i)信息丰富的局部外观变化;(ii)结合局部变化的最佳方法;(iii)并采用高层代表进行最终的表情识别。实验是在CK+[4],MMI[54]和SFEW[55]数据集上进行。后者包含在不受控制的场景下从各种电影中捕获的图像,代表真实的环境。实验采用交叉验证的方法进行,训练组和测试组之间没有受试者重叠,并评估六个基本表达式。方法达到93.70%的精度在CK+数据库中,MMI数据库中的75.85%和30.14% SFEW数据库。
Ali等人提出了一种用于多民族面部表情识别的增强神经网络集成。该模型由三个主要步骤组成:首先对一组二值神经网络进行训练,然后将这些神经网络的预测组合成集合,最后用这些集合检测表达式的存在性。多元文化的面部表情数据库是由作者用三个不同数据库的图像创建的,其中包括来自日本的图像(JAFFE),台湾(TFEID),白种人(RaFD)和摩洛哥受试者。作者报告了识别五种表情的结果(愤怒、快乐、悲伤、惊讶和恐惧)用两种不同的实验方法。首先,在多文化数据库中对系统进行培训和评估,准确率为93.75%。第二次实验是在控制较少的环境下对所提出的方法进行评价。该方法使用TFEID和RaFD两个数据库进行训练,并在JAFFE数据库中进行评价,准确率为48.67%。
Shan等人使用局部二进制模式进行了一项研究(LBP)作为特征提取器。他们将模板匹配、支持向量机(SVM)、线性判别分析和线性规划等不同的机器学习技术相结合并进行比较,以识别面部表情。作者还进行了一项研究来分析图像分辨率精度的结果的影响,得出结论:基于几何特征的方法不能处理低分辨率的图像很好,而那些基于外观,如伽柏小波和LBP,对图像分辨率不是很敏感。最好的结果实现了他们的工作是一个使用SVM和LBP95.1%精度CK+数据库。使用跨数据库验证(使用CK+和测试与JAFFE)来评估该系统在控制较少的情况下,作者实现了41.3%的准确性。首先使用眼睛位置裁剪图像。实验设置为10倍交叉验证方案,没有受试者重叠。作者没有提到培训和识别时间。提出了一种基于视频的人脸表情识别系统。他们开发了一个3D- cnn,其图像序列(从中性到最终表达式)使用5个连续帧作为3D输入。因此,CNN的输入是hw * *5(其中H和W分别为图像的高度和宽度,和5是帧数)。作者认为三维CNN方法可以处理一定程度的位移和变形不变性。使用这种方法,他们的准确率达到95%,但是该方法依赖于包含从中性到表达式的完整运动的序列。实验仅在一个不寻常的数据集上对10个人进行。作者没有提到培训和识别时间。
Fan和Tjahjadi提出的另一种基于视频的方法采用基于梯度直方图和光流的时空框架。该方法包括预处理、特征提取和分类三个阶段。在预处理阶段,对人脸地标进行检测,并进行人脸对齐(以减少头部姿态的变化)。在特征提取阶段,我们使用了一个框架,该框架集成了从表情引起的面部形状变化中提取的动态信息。在最后阶段的分类中,采用了基于RBF核的SVM分类器。实验进行了使用CK+和MMI数据库。识别的精确度CK+数据库七表情MMI数据库中为83.7%,为74.3%。训练时间没有提到,识别时间约为350 ms /图像CK+数据库和520 ms的MMI数据库。
与上述方法相比,这项工作:提出了一种精度高的CK+和JAFFE数据库(包括跨数据库验证)和一个更小的培训和评估时间与Liu et al. [7,12], Shan et al. [8] and Fan and Tjahjadi [16]相比较;一种比Song等人([10]和Bukert等人)更健壮的评估方法(训练和测试之间没有主题重叠)。识别6和7的表达,而不是只识别5或6个by Song et al. [10], Bukert et al. [11] and Ali et al;在三个主要使用的数据库上验证所提出的方法,以便与文献中的其他方法进行公平的比较,而不是使用不常见的非公共数据库,如
Byeon和Kwak[14]。这里提到的许多工作都呈现出非常高的准确性,无法与我们的方法进行公平的比较,因为它们允许训练和测试集中的主题重叠。我们的方法在考虑这些重叠场景的情况下进行的初步实验也表明,不需要太多努力,准确率接近100%。
3.面部表情识别系统(Facial expression recognition system
)
我们的人脸表情识别系统在一个分类器(CNN)中完成了三个学习阶段。提出的系统主要有两个部分构成训练和测试,在训练过程中,系统接收到包含人脸灰度图像的训练数据,这些图像具有各自的表情id和眼睛中心位置,系统学习一组网络权值。为了保证训练效果不受示例呈现顺序的影响,我们将一些图像分离出来作为验证,并从一组以不同顺序呈现的样本进行的训练中选择最终的最佳权值集。在测试过程中,系统接收到人脸的灰度图像及其各自的眼睛中心位置,并利用训练中学习到的最终网络权值输出预测的表情。系统概述如图2所示。在训练阶段,综合生成新的图像来增加数据库的大小。然后,进行旋转校正,使眼睛与水平轴对齐。随后,对图像进行裁剪以删除背景信息,只保留表达式的特定特征。采用下采样的方法对同一位置的不同图像进行特征提取。然后对图像强度进行归一化。用归一化图像训练卷积神经网络。训练阶段的输出是考虑到不同顺序的数据,经过几轮训练后,利用验证数据得出的一轮的权值集合,该轮的权值达到最佳效果。测试阶段使用与训练阶段相同的方法:空间归一化、裁剪、下采样和强度归一化。它的输出是六个基本表达式之一的一个数字——id。表达式表示为整数(0 - angry, 1 -, 2 - fear, 3 - happy, 4 - sad, 5 - surprise)
3.1合成样品代(Synthetic sample generation
)
不幸的是,由于眼睛检测程序的不完善,所使用的空间归一化并不足以确保所有人脸的眼睛都能正确对齐。幸运的是,
CNN非常擅长学习变换不变函数(即可以处理失真的图像[56])。然而,深度学习方法的主要问题之一是在训练阶段需要大量的数据来正确地执行[56]任务。不幸的是,公共数据集中可用的数据量不足以在我们的应用程序中实现这种行为。
为了解决这个问题,Simard等人[56]提出生成合成图像(即带有人工旋转、平移和倾斜的真实图像)来增加数据库,这个过程称为数据扩充。作者展示了应用翻译、旋转和倾斜组合来增加数据库的好处。这个想法后,在本文中,我们使用一个2 d高斯分布(σ= 3像素和μ= 0)引入随机噪声在眼睛的中心的位置。综合图像的生成考虑了标准化版本的噪声眼位置。对于每幅图像,都会生成70张额外的合成图像。
从图3中可以看出,两只眼睛的点都是以原始位置为中心的高斯分布产生的。因此,新的眼睛中心位置与原来的位置相同,但受到高斯噪声的干扰。由于归一化过程的新值不是真实的眼睛中心,因此生成的图像要么会被平移、旋转和/或缩放所干扰,要么根本不会被干扰。标准差σ= 3像素的经验选择需要注意的是,合成数据仅用于训练。
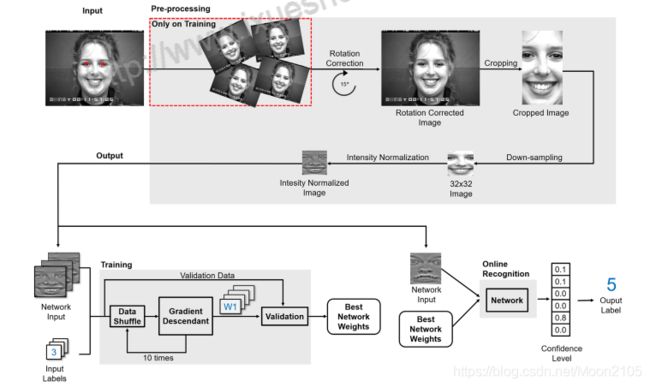
图2所示。人脸表情识别系统概述。该系统分为两个主要阶段:培训和测试。训练阶段将人脸、眼睛位置、表情id作为一组图像的输入,经过几轮训练,考虑不同顺序的数据,输出验证数据得到的最优结果的轮权值集。测试阶段接收来自学习步骤和具有眼睛位置的人脸图像的权重集,输出图像的表情id

图3所示。合成样品生成的说明。高斯合成样本生成过程增加了数据库的大小和变异,增加了噪声
(高斯σ= 3像素)图像中考虑控制环境。使用归一化步骤和新的视点生成新的图像。绿色的十字架是原始的视点,而红色的是合成的视点。(要解释图中对颜色的引用,请参考本文的web版本。)
3.2旋转校正(Rotation correctio)
数据库中的图像,以及真实环境中的图像,即使是同一主题的图像,其旋转、亮度和大小也各不相同。这些变化与面部表情无关,会影响系统的准确率。为了解决这个问题,面区域(通过旋转归一化)与地平线和中心点对齐,以纠正可能的几何问题,如旋转和平移。要实现这种对齐,需要两个信息,面部图像和双眼的中心。在文献中已经有很多方法能够高精度地找到眼睛和其他面部点[57-61],而这并不是这项工作的重点。Cheng等[61]开发了一种CUDA版本的DRMF[60],允许实时检测面部关键点,同时即使在面部部分被遮挡的情况下也能准确检测这些关键点(眼距RMSE低于0.05)。
为了实现人脸对齐,应用旋转变换使眼睛与图像的水平轴对齐,并使用由眼睛位置定义的仿射平移将人脸集中到图像的特定点。旋转使从一个眼睛中心到另一个眼睛中心的线段形成的角度,水平轴为零。图像中的旋转和平移与面部表情无关,因此需要去除,以免对系统的准确率产生负面影响。旋转校正程序如图4所示。:这个过程的输入可以是原始图像,也可以是合成图像。对于合成生成的图像,由于眼睛中心是被随机高斯噪声干扰的真实位置,旋转校正可能无法与水平轴完美对齐。因此,它会生成被旋转和平移干扰的图像,这增加了训练示例中的变化。
3.3图像裁剪
如图2所示,原始图像有很多背景信息,这些背景信息对于表达式分类过程并不重要。这个信息会降低分类的准确性,因为分类器还有一个问题需要解决,那就是区分背景和前景。这个信息会降低分类的准确性,因为分类器还有一个问题需要解决,那就是区分背景和前景。裁剪之后,删除所有没有特定表达式信息的图像部分。裁剪区域还试图去除面部不影响表情的部分(例如耳朵、前额等)。裁剪之后,删除所有没有特定表达式信息的图像部分。裁剪区域还试图去除面部不影响表情的部分(例如耳朵、前额等)。因此,感兴趣的区域是根据眼睛间距离的比值来定义的。因此,我们的方法能够处理不同的人和图像大小,无需人工干预。裁剪区域由垂直因子4.5(眼睛上方区域为1.3,眼睛下方区域为3.2)划分,该因子应用于眼睛中点到右眼中心的距离。水平裁剪区域以2.4倍的系数对相同距离进行划分。这些因子值是由经验确定的。图5显示了这个过程的一个例子。
3.4下采样(down-sampling)
对网络进行降采样操作,减小图像大小,保证尺度归一化,即所有图像中人脸成分(眼睛、嘴巴、眉毛等)的位置相同。下采样采用线性插值方法。重新采样后,可以保证眼睛的中心大致处于相同的位置。这个过程帮助CNN了解与每个特定表达相关的区域。下采样还可以在GPU中执行卷积,因为目前大多数显卡内存有限。最后的图像是下降采样,使用线性插值,到32×32像素。
3.5归一化强度(Intensity normalization)
即使是同一个人在同一表情下的图像,其亮度和对比度也会发生变化,从而增加了特征向量的变化。这种变化增加了分类器必须为每个表达式解决的问题的复杂性。为了减少这些问题,采用了强度标准化。采用了一种从[62]中描述的仿生技术改编而来的方法,称为对比均衡。归一化基本上分为两步:首先进行减法局部对比度归一化;其次,采用分裂的局部对比归一化。在第一步中,每个像素的值从相邻像素的高斯加权平均值中减去。在第二步中,每个像素除以其邻域的标准差。这两个过程的邻域都使用一个7×7像素的内核(根据经验选择)。图6给出了这个过程的一个例子。
等式(1)为强度归一化过程中每个新像素值的计算方法:
 (1)
(1)
x′是新的像素值,x是原始的像素值,μnhgx Gaussian-weighted平均x的邻居,和σnhgx的标准差是x的邻居。

图4所示旋转校正的例子。使用从一个眼睛中心到另一个眼睛中心的线段(红线)和横轴(蓝线)旋转未校正的输入图像(左)(右)。10°只是一个可能的修正的例子。(要解释图中对颜色的引用,请参考本文的web版本。)

图5所示图像裁剪的例子。空间标准化使用inter-eyes距离(α)的一半。出现输入图像(左)(右)使用水平因素(α* 2.4)作物在水平和垂直因素(α为1.3 * 4.5考虑上述地区下面的眼睛3.2,该地区)作物在垂直。这个操作的目的是去除所有非表情特征,如背景和头发。

图6所示强度归一化的说明。图中显示了原始强度(左)和强度标准化版本(右)的图像。
3.6卷积神经网络(CNN)
我们的卷积神经网络结构如图7所示。网络接收32x32灰度图像作为输入,输出每个表达式的置信度。具有最大值的类用作图像中的表达式。我们的CNN架构包括两个卷积层,2个子采样层和1个全连接层。CNN的第一层是卷积层,它应用一个5×5的卷积核,输出32张28×28像素的图像。这一层之后是子采样层,它使用最大池(内核大小为2×2)来将图像减小到其大小的一半。然后,一个新的卷积层用a进行64次卷积7×7核映射前一层,然后再进行另一个子采样,再用2×2核。输出被给予一个完全连接的隐藏层,它有256个神经元。最后,网络有6或7个输出节点(每个输出其置信级别的表达式对应一个节点),它们完全连接到上一层。
网络的第一层(卷积层)的目的是提取基本的视觉特征,如有向边缘、端点、角和一般形状,如Lecun等人描述的[36]在人脸表情识别问题中,检测到的特征主要是眼睛、眉毛和嘴唇的形状、棱角和边缘。一旦特征被检测到,它的准确位置就不那么重要了,只是相对于其他特征的相对位置。例如,眉毛的绝对位置并不重要,但它们与眼睛的距离都很大。例如,惊讶表情。

图7所示建议的卷积中立网络架构。它由五层组成:两个卷积层、两个子采样层和一个完全连接层。
这个精确的位置不仅无关紧要,而且还可能造成问题,因为它可以自然地根据同一表达中不同的主题而变化。第二层(子采样层)降低了特征图的空间分辨率。根据Lecun等人的研究。该操作的目的是降低前一层提取的特征位置在新地图中编码的精度。接下来的两层,一个卷积层和一个子采样层,目的是做和前一层相同的操作,但在较低的层次上处理特征,识别上下文元素(人脸元素),而不是简单的形状、边缘和角。卷积集和子采样层的串联实现了对输入的几何变换高度不变性。最后一个隐藏层(一个完全连接的层)接收学习到的一组特性,并在每个考虑的表达式中输出给定特性的置信级别。该网络采用随机梯度下降法计算神经元间突触权值,该方法由Buttou[63]提出。这些卷积和全连接层的突触的初始值是由Glorot等[64]提出的Xavier填充器生成的,该填充器根据输入和输出神经元的数量自动确定初始化的规模。损耗是使用软最大输出(称为软maxwithloss)的逻辑函数来计算的。神经元的激活功能是一个ReLu(整流线性单元),定义为f (z) = max(z, 0)。
4. 实验和讨论(Experiments and discussions)
实验使用了面部表情识别研究领域的三个公共数据库数据库扩展Cohn-Kanade (CKþ)[4],日本女性面部表情(JAFFE)数据库[5]和宾厄姆顿大学三维面部表情(BU-3DFE)数据库[6]。计算精度考虑一个分类器分类所有学习的表达式。此外,为了与文献中的一些方法进行公平的比较,我们还考虑到每个表达式都有一个二进制分类器,如[7]中所使用的。预处理步骤的实现了自身的使用OpenCV, C++和基于GPU的CNN库(caffe[47])。所有的实验都是使用英特尔酷睿i7进行的3.4 GHz与NVIDA GeForce GTX 660 CUDA的能力,有GPU 1.5 Gb内存。实验环境为Linux Ubuntu 12.04,使用NVIDIA CUDA框架6.5安装cuDNN库。预处理步骤(轮作校正、裁剪、下采样和强度归一化)仅花费0.02秒,网络识别(分类步骤)平均花费0.01秒。在本节中,我们研究了每个归一化步骤对方法精度的影响。首先,我们描述了用于实验的数据库。其次,对用于评价系统精度的指标进行了说明。
最后给出了调优实验结果以及各预处理步骤的影响。第四,对不同数据库的结果进行了详细的展示和讨论。最后,对几种常用的面部表情识别方法进行了比较,讨论了该方法的局限性。
4.1数据库(database)
提出了系统训练和测试使用CKþ数据库[4],[5]JAFFE数据库和数据库BU-3DFE [6]。CK+数据库包括100名大学生,年龄在18到30岁之间。数据库中的受试者中65%是女性,15%是非裔美国人,3%是亚洲人或美国南方人。这些图像是由直接位于被摄对象前方的摄像机拍摄的。学生们被要求表演一系列的表情。每个序列以中性表达式开始和结束。数据库中的所有图像都是640×
480像素阵列,具有8位精度的灰度值。每个图像都有一个描述符文件及其面部点,这些点用于规范化面部表情图像。利用人脸动作编码系统对数据库中的人脸点进行编码(流式细胞仪)[66]。数据库创建者使用活动外观模型(AAMs)自动提取面部点。该数据库包含以下表情的图片:中性、愤怒、蔑视、厌恶、恐惧、高兴、悲伤和惊讶。对最近的主要方法做一个公平的比较
[16,7,44,43,67,8],在我们的实验中没有使用轻蔑表情图像。一些例子CKþ数据库的图像图8所示。为了公平地评价所提出的方法,数据库被分成8组,组与组之间没有主题重叠(即如果一个主题的图像在一个组中,那么同一主题的图像将不会在任何其他组中)。每组包含大约12个受试者。这种方法确保测试组没有来自训练组的受试者,并且在文献[16、44、43、67-69、8、7、70]中也使用了许多方法。如Girard等人[53]所讨论的,这种方法(训练/测试组中的不同主题和交叉验证)确保了分类器的通用性。Zavaschi等人也讨论并支持这种数据分离过程。他们使用相同的方法进行了两个实验,只是改变了数据组分离的方式。在一个实验中,组中包含同一受试者的图像(不是相同的图像),而在另一个实验中,组中保证同一受试者的图像不在同一训练和测试组中。在第一个实验中,准确率达到99.40%,第二个实验准确率下降到88.90%。

图8所示CK+数据库中图像的例子。在(1)中,中性表达。在(2)中,the surprise expression。在(3)中,厌恶的表情。在(4)中,恐惧的表情。
这一结果表明,在培训/测试组中不使用相同的对象进行评估的方法(我们认为这是一种更公平的评估)的准确性通常低于那些不保证这种约束的方法。我们也用我们的方法通过初步实验证实了这些结果。
为了验证该方法的通用性,还进行了一些跨数据库的实验。这些实验使用了JAFFE和BU-3DFE数据库。JAFFE数据库包括来自10名日本女性受试者的213幅图像。在这个数据库中,六个基本表达式中的每一个都有大约4张图像,每个受试者的中性表达式各有一张图像。数据集中的所有图像都是256×256像素阵列灰度值的8位精度。由于这个数据库比较小,所以每组都是被subject分开的,即每组只包含一个subject的图片,所以形成了10组。一些例子JAFFE数据库图像如图9所示。
另一个用于评估该方法的数据库是宾厄姆顿大学三维面部表情(BU-3DFE)[6]。的BU-3DFE数据库包含64名受试者(56%为女性,44%为男性),年龄在18岁至70岁之间,有多种种族/种族祖先,包括白人、黑人、东亚人、中东亚裔、印度裔和拉美裔。数据集中的所有图像都是156×209像素阵列。该数据库也分为8组,组与组之间没有主题重叠。每组包含约8名受试者。bu3dfe数据库图像的一些例子如图10所示。
所有的数据库都包含许多相同主题的图像,这些图像对于每个表达式都非常相似。因此,在本研究中,我们只使用了每个被试的3个表达框架(即表达能力最强的框架)和1个中性表达框架(即表达能力最差的框架)。这种方法后,生成的数据库大小如下,CK+数据库2100个样本(没有合成样品)JAFFE数据库213个样品(不含合成样品)、14910个样品(含合成样品)、BU-3DFE数据库1344个样品(不含合成样品)、94080个样品(含合成样品)。
4.2指标(Metrics)
为了使所提出的方法与文献进行公平的比较,计算精度采用了两种不同的方法。在第一种方法中,对所有基本表达式使用一个分类器。该精度仅用n类分类器每次表达式的平均分类精度Cnclass计算,即每次表达式的数据量对该表达式的命中次数,见下式:

其中HitE为表达式E中的命中次数,TE为该表达式的样本总数,n为要考虑的表达式个数。
在第二种方法中,每个表达式的一个二进制分类器执行一个对所有表达式的分类,如[7]中所建议的那样。用这种方法,图像被呈现给n个二进制分类器,其中n是被分类的表达式的个数。如果图像包含一个特定的表达式,每个分类器的目标都是回答“是”,或者“不”。例如,如果一个图像包含惊喜表达式,惊喜分类器应该回答“是”,而其他五个分类器应该回答“不是”。这个分类器与第3节中介绍的体系结构的唯一区别是,每个分类器只需要两个输出。该精度是使用每个表达式的二进制分类器精度CbinE的平均值Cbin计算的,即一个表达式的命中次数加上一个非表达式的命中次数除以总数据量,见下式:

其中HitE为表达式E中的命中次数,即分类器E响应“是”的次数,被测图像为表达式E。HitNE是分类器E响应“no”的次数,被测试图像不是表达式E。T是被测试图像的总数,n是要考虑的表达式个数。
4.3预处理优化(Pre-processing tuning)
如前所述,该方法结合了预处理步骤,目的是去除面部图像的非表达特定特征和卷积神经网络,将预处理后的图像分类为6个(或7个)表达式中的一个。在本节中,我们将介绍预处理步骤中每个操作对分类精度的影响。由于这些实验的目的只是为了显示操作的影响,我们使用了简化版的方法。在这里,我们随机生成样本到网络的顺序,并使用一个简单的k-fold交叉验证的8组之间的CK+数据库。数据库分为训练两套(与7组)和测试(与1组)。该训练共进行了8次,每次仅使用2000个epoch。计算每个表达式(C6classE)和所有表达式(C6class)的总体平均精度。
(a)没有预处理。第一个实验是使用原始数据库进行的,没有任何干预,图像预处理。只需对图像进行下采样,使其大小与CNN的输入相同。在本实验中,所有表达式的平均准确率为C6class = 53.57%。每个表达式的精度如表1所示。所示精度是Eq.(2)对所有运行的平均值。
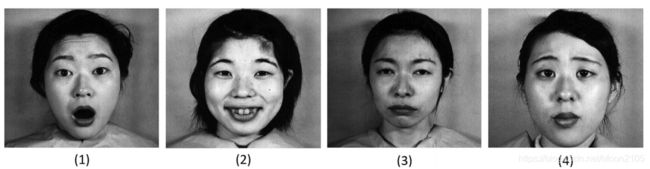
图9所示。JAFFE数据库中的图像示例。在(1)中,the surprise expression。在(2)中, the happy expression。在(3)中,主语 the sad expression。In(4),the sad expression。
 图10所示bu3dfe数据库中的图像示例(1)the fear expression。(2)主语用的是中性表达。(3) the fear expression。(4)the fear expression
图10所示bu3dfe数据库中的图像示例(1)the fear expression。(2)主语用的是中性表达。(3) the fear expression。(4)the fear expression
从表1中可以看出,仅使用CNN而不进行任何图像预处理,与文献方法相比识别率非常低。我们相信CK+数据库中的样本的变异和数量很小,不允许卷积神经网络学习如何处理姿势,环境和方差。此外,它不使用网络输入中可用的全部图像空间来表示人脸。我们相信CK+数据库中的样本的变异和数量很小,不允许卷积神经网络学习如何处理姿势,环境和方差。此外,它不使用网络输入中可用的全部图像空间来表示人脸。
(b)图像裁剪。为了提高我们的方法性能,正如第3节所解释的,在训练和测试步骤中,都会自动裁剪图像以去除非表达的特定区域。结果,所有表达式的平均准确率提高到C6class = 71.67%。每个表达式的精度如表1所示。这里也进行了下采样,因为所提出的网络输入是固定的32×32像素图像。
与之前的结果相比,我们可以注意到只添加裁剪过程可以显著提高识别率。准确率提高的主要原因是随着裁剪的进行,我们删除了分类器需要处理的大量不必要的信息,以确定主题表达式,更好地利用网络输入中可用的图像空间。
(c)旋转校正。在训练和测试步骤中,对图像进行旋转校正(和下采样),以去除与表情面部变化无关的旋转(可以是特定位置的,也可以是由相机运动引起的)。所有表达式的平均准确率为C6class = 61.55%。
注意,这个结果只应用了旋转校正,而没有应用裁剪。与未进行预处理的结果相比,其精度提高了8.00%左右。这种增加可能是由于网络需要处理的变化较小造成的。通过旋转校正,人脸元素(眼睛、嘴巴、眉毛)大多停留在相同的像素空间内,但仍然受到背景的影响,没有使用网络输入中可用的全部图像空间来表示人脸,如a)。
(d)空间标准化。如前所述,分别进行图像裁剪和旋转校正,提高了分类器的精度。这是因为这两个过程都降低了问题的复杂性。在这里,我们讨论了由图像裁剪、旋转校正和下采样组成的全空间归一化。结合运算,所有表达式的平均准确率为C6class = 87.86%。
正如预期的那样,在预处理步骤中加入这两个程序可以提高精度。这是因为从图像中删除了许多与表达式无关的变量。虽然卷积神经网络可以处理这些变化,但我们需要一个更大的数据库(我们没有),也许还需要一个更复杂的体系结构。
(e)强度归一化。空间归一化过程显著提高了系统的整体精度。强度归一化用于去除图像在训练和测试两个步骤中的亮度变化。本实验仅使用强度归一化。它使用了与前面描述的相同的方法。所有表达式的平均准确率为C6class = 57.00%。
可以看出,仅仅使用强度归一化,分类器的准确率也有了轻微的提高。
(f)空间强度归一化。结合空间(轮作校正、裁剪及下采样)正常情况下,我们去掉大部分与面部表情无关的变化,只留下与姿势或环境无关的特定表情变化。这个实验是用之前描述的同样的方法做的。所有表达的平均准确率为C6class = 86.67%。每个表达式的精度如表1所示。
 表1
表1
预处理步骤CKþ数据库调优:(a)没有预处理;(b)只是种植;(c)只是旋转校正;(d)修剪和轮作纠正;(e)只有强度正常化;(f)的标准化;(g)空间归一化和合成样品;(h)正规化和合成样品
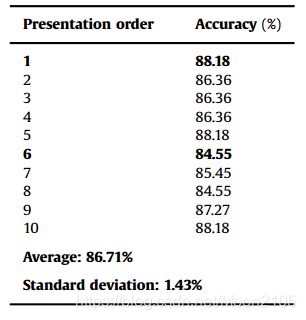 表2
表2
演示顺序对准确性的影响。
可以看出,这两种归一化方法的精度都低于只使用空间归一化的方法。恐惧表情的结果准确率非常低,降低了整体识别的平均水平。
(g)空间归一化和合成样品。空间归一化和强度归一化以及空间归一化的结果给人一种错误的印象,即强度归一化可能会降低方法的精度。为了验证这个假设,我们进行了一个新的实验,只使用空间归一化过程和额外的合成样本进行训练。合成样品的一代,三十多的样本为每个图像生成使用3像素的高斯标准偏差(θ= 3)。所有的平均精度表达式C6class = 89.11%。每个表达式的精度表示为表1。
该结果提高了空间归一化的精度(87.86%)。但是,在接下来的实验中,使用标准化和合成样本生成的方法,其精度都要优于此,这表明合成样本生成过程确实提高了分类器的鲁棒性(由样本的增加及其变化所驱动)。
(h)空间归一化、强度归一化和合成样品。该方法采用空间归一化、强度归一化和合成样本生成三个预处理步骤,取得了较好的效果。本实验采用的方法与前面描述的相同。所有表达的平均准确率为C6class = 89.79%。实验结果表明,空间归一化、强度归一化、合成样品归一化三种方法相结合的效果优于单独使用。
表1显示了平均精度为每个表达式使用所有的预处理步骤已经讨论过CKþ数据库:(a)没有预处理,(b)裁剪,(c)旋转校正,
(d)空间归一化(裁剪和旋转校正),(e)强度归一化,(f)同时归一化(空间和强度),(g)使用合成样本的空间归一化,(h)同时归一化和合成样本。使用6类分类器(C6classE)计算精度。获得的最佳准确度用粗体突出显示。
4.4结果(results)
如前所述,采用了一种简化的训练/测试方法来评估预处理步骤的影响。与只使用训练集和测试集的调优实验不同,本节将每个实验的数据库分为三个主要的组:训练集、验证集和测试集。
此外,还提到了使用梯度下降法对网络进行训练。在训练过程中,这些方法可能会受到样本呈现给网络的顺序的影响,从而导致准确性的变化。从表2中可以看出,只有随着训练样本的顺序发生变化,准确率才会增加(或减少)约4.00%(如粗体高亮显示的值所示)。表2显示了相同训练的准确性,执行了10次,每次训练样本的呈现顺序都是随机的。为了减少这种精度变化的影响,我们提出了一种基于不同训练的验证集选择最佳网络权值的训练方法,如图2所示。因此,我们实验的最终精度结果是使用10次运行中最优运行的网络权值来计算的,并有一个精度测量的验证集。每次运行都有训练样本的随机表示顺序。验证集中最佳运行的权重稍后用于评估测试集并计算最终的精度。
为了验证所提出的方法可以很好地处理其他数据库,甚至在未知的环境中,还进行了buo - 3dfe数据库、JAFFE数据库和跨数据库的实验。实验与其他数据库遵循相同的方法,CK+数据库。在跨数据库的实验中,使用CK+数据库和计算精度评估使用JAFFE的BU-3DFE数据库或数据库。在跨数据库实验中,没有来自BU-3DFE数据库或网络训练中使用了JAFFE数据库。
CK+数据库实验。数据库被分成8组无重叠的受试者(每组约12名受试者)。七组组成训练集,第八组(也约有12名受试者)在验证集和测试集之间共享,其中11名受试者用于验证,1名受试者用于测试。我们的实验遵循k-fold交叉验证配置,其中,每一次,一个组分开进行验证/测试,另七个组进行训练。对每一个验证和测试主体的配置进行10次训练,改变训练图像的呈现顺序。验证组用于为训练期间的每次运行选择最佳历元,并选择具有最佳表示顺序的运行。基于这些信息(最好的时代和演示顺序),最好的选择和网络权值用于计算测试集的准确性。这个实验配置,网络的训练执行960倍(8组* 12个主题/组* 10分不同的呈现顺序)。每次跑步训练只需要2分钟,因此整个系统的训练大约需要20分钟(2分钟* 10次)整个实验时间约为32小时(包括培训、验证和测试的所有组合)。本实验结果以96次运行(每组8次* 12个受试者* 1次最佳配置)的平均值计算10分)。
表3显示了C6class和Cbin的最佳结果(使用规范化和合成样本)。由此可见,二值分类器方法提高了分类精度。之所以会发生这种情况,是因为用这种方法可以达到6次命中,而不是只使用一个分类器,其中每个样本只有一个机会被正确分类。采用二进制分类器方法与文献中仅报告这些结果的一些方法进行了公平的比较。我们认为六类分类器(C6class)是一种较为公平的评价方法。然而,当我们只对一个表达式感兴趣时,Cbin分类方法是一种有用的方法。表中报告的标准差是基于所有受试者的运行情况。
所示的训练参数值表3如表4所示。在其他数据库上的实验中也使用了相同的参数值
利用表3的结果,为六类分类器创建了表5所示的混淆矩阵。
根据六类分类器的结果,我们可以看出厌恶、高兴和惊讶的表情准确率都在98%以上。而愤怒和恐惧的表情分别为93%和96%。sad表达的识别率最低,仅为84.52%。看看这个混淆矩阵,悲伤的表情和惊讶的表情在大多数情况下都是混淆的。这说明这两个表达式的特征在像素空间上没有很好的分离,在某些情况下非常相似。图11给出了一些分类错误的例子。
图12展示了学习到的内核和为每个卷积层生成的映射。在第一卷积层中,输入图像由32个学习核处理,生成32个输出映射。在第二个卷积层中,64个学习核分别用于生成新的映射前一层的32张地图。图12所示的内核使用CK+数据库在培训中学到的六种基本的表情。从图中可以看出,经过第二卷积层后,生成的地图聚焦在眼睛、嘴巴和鼻子附近的区域。事实上,心理学研究表明,这些区域对面部表情分析更为关键[71]。
我们不仅可以识别六个表达式,还可以识别中性表达式,从而产生一个能够识别七个表达式的分类器。七个表情分类器的结果CK+数据库,使用同样的方法six-class如表6所示。表中报告的标准偏差是在所有受试者的运行之间。可以看出,对于二值分类器方法,我们的准确率略有下降,从98.90%下降到98.80%。另一方面,在七类分类器中,下降幅度更大,从96.7%到95.7%之间。
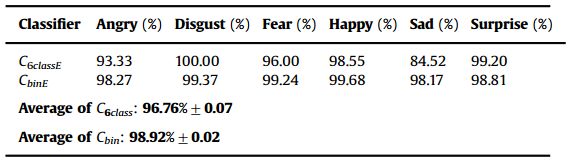 表3
表3
精度分类器使用所有处理步骤和合成样品六个表情CK+数据库
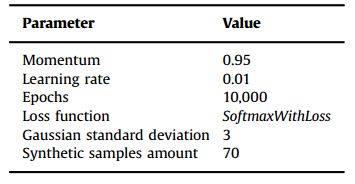 表4
表4
训练参数
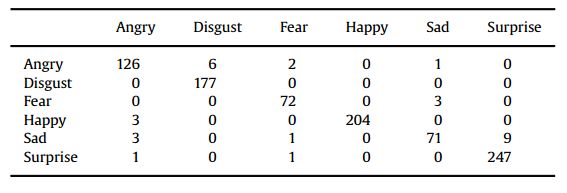 表5
表5
混淆矩阵使用的标准化和合成样品六个表情CK+数据库
之所以会发生这种情况,是因为在七类分类器方法中,网络中包含了一个额外的输出。另一方面,在二进制类方法中,插入了一个新的分类器,保持其他分类器不变。这七个表达式的混淆矩阵如表7所示。BU-3DFE数据库实验。这个实验遵循相同的方法作为CKþ数据库,唯一的区别是,在BU-3DFE数据库组织只有8个主题。这个实验的结果被计算为64次跑步的平均值(每组8个折叠* 8个受试者* 10次跑步中的1次最佳配置)。这个实验的结果被计算为64次跑步的平均值(每组8个折叠* 8个受试者* 10次跑步中的1次最佳配置)。可以看到,BU-3DFE的准确性下降而CK+数据库。一个可能的原因是,这个数据库有更多学科从不同种族和光照条件,并小于CK+。此外,我们在7个表达式上提高了Cbin分类器的精度,而在7个表达式上降低了Cnclass分类器的精度。本实验关于6个和7个表达式的混淆矩阵分别见表13和表14附录(附录A)。
buo - 3dfe数据库包含六个基本表情和中性表情中的人脸三维模型。该数据库通常用于三维数据的三维重建和人脸表情识别。该数据库通常用于三维数据的三维重建和人脸表情识别。然而,在这项工作中,仅仅使用受试者的二维图像来识别表情。文献中也有其他的研究,其面部表情识别精度较高,但使用三维信息来推断表情[72-74]。在实际环境中,对该方法更好的评价是跨数据库实验,即用一个数据库训练该方法,用另一个数据库(在本例中是BU-3 dfe)进行测试。
为了进行跨数据库实验,对七组数据进行了统计分析CK+数据库被用来训练网络,一个是用来验证集(选择最佳网络权重基于最好的时代表示训练集的顺序)。使用BU -3DFE对网络进行测试。培训进行了8次,每次使用不同的验证集。我们运行每个配置(培训集和验证集)10次,每个配置在培训样本中呈现的顺序不同。在跨数据库实验中,计算结果的平均值8次运行考虑不同组合的训练和验证集(10次运行中8次折叠* 1次最佳配置),显示所有用于测试网络的BU-3DFE图像。结果如下所示表9所示。
本实验中关于6个和7个表达式的混淆矩阵分别见表15和表16附录(附录A)。
JAFFE数据库实验。这个实验是一种稍微不同的方法从CKþBU-3DFE实验关于群体的数量。JAFFE数据库包含仅来自10个受试者的图像,因此,与文献中其他作品一样[7,8],图像被分成10组,每组只有一个主题。试验采用10倍交叉验证法进行,训练组包括8名受试者,验证组1名受试者,试验组1名受试者。这个实验的结果被计算为10的平均值。两个分类器的6个和7个表达式的结果如表8所示。表中报告的标准偏差是在所有受试者的运行之间。
 图11所示。在(1)中,预期的表情是悲伤的,但方法返回恐惧。在(2)中,预期的表情是愤怒的,但方法返回恐惧。在(3)中,预期的表情是悲伤的,但方法返回愤怒。在(4)中,预期的表情是愤怒,但方法返回悲伤。
图11所示。在(1)中,预期的表情是悲伤的,但方法返回恐惧。在(2)中,预期的表情是愤怒的,但方法返回恐惧。在(3)中,预期的表情是悲伤的,但方法返回愤怒。在(4)中,预期的表情是愤怒,但方法返回悲伤。
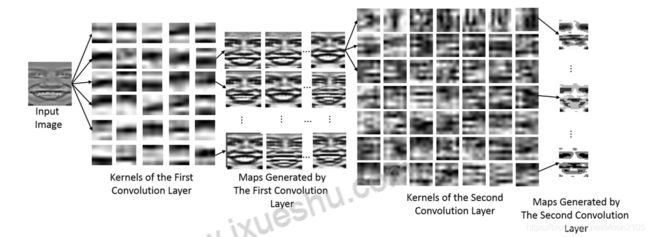 图12所示。说明学习的内核和为每个卷积层生成的映射。在第一卷积层中,输入图像由32个学习核处理,生成32个输出映射。在第二个卷积层中,使用64个学习核为前一层的32个映射中的每一个生成新的映射。这个图像中没有表示子采样层。只显示了第一层的32个内核和第二层的64个内核中的一个子集。生成的映射经过了均衡,以实现更好的可视化。
图12所示。说明学习的内核和为每个卷积层生成的映射。在第一卷积层中,输入图像由32个学习核处理,生成32个输出映射。在第二个卷积层中,使用64个学习核为前一层的32个映射中的每一个生成新的映射。这个图像中没有表示子采样层。只显示了第一层的32个内核和第二层的64个内核中的一个子集。生成的映射经过了均衡,以实现更好的可视化。
 表6
表6
精确的分类器使用所有的处理步骤和合成样本的七个表达式
 表7
表7
混淆矩阵使用的标准化和合成样品七表情CKþ数据库
 表8.对buo - 3dfe和JAFFE数据库使用6和7(6个基本加中性)表达式的准确性。
表8.对buo - 3dfe和JAFFE数据库使用6和7(6个基本加中性)表达式的准确性。
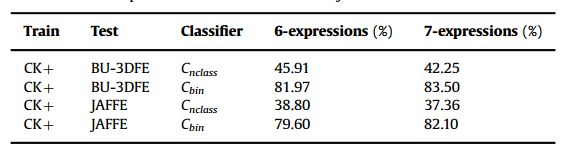 表9
表9
用于BU-3DFE和JAFFE数据库的跨数据库实验。
表8中可以看到,而CK+和BU -3def结果表明,该方法的精度明显下降。在其他作品[7,8,44]中也有类似的情况发生,主要是由于数据库较小。Girard et al.[53]研究了人脸动作(或表情)识别方法在训练阶段为达到良好的准确性所需要的数据量。在他们的一个实验中,随着训练集从8个受试者增加到64个受试者,识别率从63%到94%不等。一旦JAFFE数据集包含的图像只有10,它是不公平的比较结果与CKþ或BU3DFE包含的数据集,分别为100例和64例。在这项工作中使用的技术更强调了数据量小的问题。卷积神经网络通常需要大量的数据来调整其参数。因此,文献中还有其他方法不需要如此大量的数据,因此可以获得比本文方法更好的结果[44,8]。本实验关于6个和7个表达式的混淆矩阵分别见附录表17和表18。并对其进行了跨数据库实验JAFFE数据库。在这个实验中网络只训练和验证在CK+数据库和在JAFFE数据库上进行了测试。本实验采用与BU-3DFE相同的方法。跨数据库实验的结果计算为8次运行的平均值,以考虑不同的训练集和验证集组合(8倍*)10次运行中的1次最佳配置)显示所有测试网络的JAFFE图像。实验结果如下所示表9所示。表9中报告的准确性较低的一个原因是培训对象和测试对象之间的文化差异。而在BU-3DFE我们有一些科目相同的种族的CKþ数据库,并不发生在相同JAFFE数据库。本实验中关于6个和7个表达式的混淆矩阵分别见表19和表20附录(附录A)。
4.5比较(comparison)
表10总结了本节给出的所有结果,通过改变图像预处理步骤,展示了该方法的发展。
如表10所示,使用归一化过程和合成样例可以获得最佳性能(如粗体显示的行所示)。这个表只是用一个简化的训练方法,总结了为选择该分类器的最佳配置而进行的实验。
 表10
表10
预处理的比较。

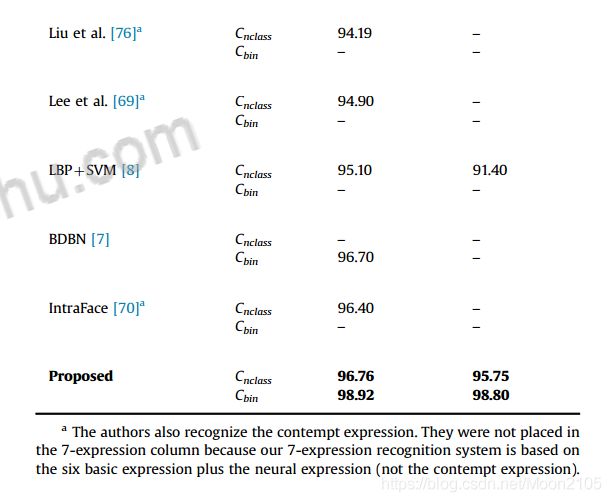 表11
表11
比较CK+数据库
表11显示了CK+结果数据库使用完整的验证方法(通过训练,验证集和测试集)解释说。在本表中,我们将提出的方法与文献中使用相同实验方法的其他方法(即进行k-fold交叉验证,并确保培训和测试组中没有相同的主题)进行了比较。表11中可以看到,该方法实现竞争结果CK+数据库中的所有实验配置(因为它可以看到行以粗体突出显示)。
表11中可以看到,该方法实现竞争结果CK+数据库中的所有实验配置(因为它可以看到行以粗体突出显示)。此外,训练和验证的时间也比其他的小。的总时间与CK+训练系统是整个实验时间约20分钟。包括该方法的所有k-fold配置32 h,实时识别(只有
每幅图像0.01 s),每秒可处理近100幅图像。与Liu等人的[7]相比,他们的训练时间为8天,每幅图像的识别时间约为0.21 s。注意,我们忽略了用于计算时间的硬件。Shan等人[8]和Zhon等人[68]没有报告训练和验证时间。Lee等[69]提出的方法在人脸表情识别前需要进行人工图像预处理。值得注意的是,尽管文献中有一些其他方法报告的准确性高于我们的方法结果是不可比较的。如前所述,一种公平的面部表情识别评价方法应该保证受试者的图像不同时出现在训练集和测试集中。在不受此约束的情况下获得的精度优于给出的结果。这些方法中的一些随机选择数据到折叠中[39-42]。还有一些方法只选择数据库的一个子集
(或六个基本表达式的子集)来评估准确性(79 - 81年,13)。里维拉等。[43]还报告说99.50%的准确性在CK[82]数据库中,这是一个之前版本的CK+[4]数据库对象和图像序列较少。然而,表11中可以看到,结果与CK+往往比的CK。一些方法在文献[67]8日7日JAFFE数据库中也表现crossdatabase实验(CKþ数据库中的训练和测试JAFFE)。在跨数据库实验中,将这些工作与这些方法进行比较,如表12所示。一些方法在文献[67]8日7日JAFFE数据库中也表现crossdatabase实验(CKþ数据库中的训练和测试JAFFE)。在跨数据库实验中,将这些工作与这些方法进行比较,如表12所示。在我们的文献综述中,我们没有发现任何使用BU-3DFE进行跨数据库评估来进行表达识别的工作。用粗体突出显示了该方法在JAFFE数据库跨数据库实验中的结果。与Shan等人的[8]方法相比,使用7个表达式和Cnclass分类器,我们的准确率要低4%左右。他们没有报告这六个基本表达的结果。另一方面,与Liu等人的[7]相比,采用二值分类器方法,该方法的准确率显著提高,从68.0%提高到82.0%。Ali等人的[13]在工作中也进行了跨数据库验证,在RAFD数据库中训练的准确率为48.67%,在JAFFE数据库中测试的准确率为48.67%。不幸的是,由于实验方法的差异,我们无法与我们的结果进行比较。第一个是数据库,在我们的案例中进行了训练与CK+数据库,而他们RAFD数据库。其次,他们只认识五种表情(愤怒、高兴、惊讶、悲伤和恐惧)。
4.6限制(limitations)
如前所述,提出的方法需要每只眼睛的位置作为图像预处理步骤。采用文献[59,61]中的方法,可以方便地将眼检测纳入系统中,同时保持整个方法(包括眼检测)的实时性。此外,如表1所示,一些表达式,如sad的准确率约为84%,而整个方法的准确率约为96%。这表明,这些类别之间的差异不足以将它们分开。解决这个问题的一种方法是为这些表达式创建一个专门的分类器,用作第二个分类器。该方法的另一个局限性是输入图像与受试者正面的受控环境。所有这些限制都可以用一组大量的训练数据加以解决,这将使一个能够处理这些限制的更深层次的网络成为可能。
5 结论(conclusion)
本文提出了一种结合卷积等标准方法的人脸表情识别系统具体的神经网络图像预处理步骤。实验表明,归一化方法的结合大大提高了方法的精度。结果表明,与文献中使用相同的面部表情数据库和实验方法的方法相比,我们的方法取得了较好的竞争结果,提出了一种较为简单的解决方案。此外,它需要更少的时间来训练和它的识别是在实时执行。最后,跨数据库实验表明,该方法也适用于未知环境,测试图像采集条件和对象与训练图像不同,但仍有改进的空间。如第1节所述,使用卷积神经网络的目的是减少对手工编码特性的需求。它的输入可以是原始图像,而不是已经选择的一组特性。之所以会发生这种情况,是因为这个神经网络模型能够学习一组特征,这些特征能够最好地对所需的分类进行建模。为了完成这样的学习,卷积神经网络需要大量的数据,而我们没有。这是深层架构的一个约束,其动机是在培训期间需要调整的大量参数。为了解决这个问题(我们有限的数据),对图像进行预处理操作,以减少图像之间的变化,并选择要学习的特征子集,从而减少了对大量数据的需求。如果我们有一组更好的图像,有更多的变化和更多的样本(数以百万计),这些预处理操作就不需要达到报告的精度,甚至可以改进跨数据库验证。如果我们有一组更好的图像,有更多的变化和更多的样本(数以百万计),这些预处理操作就不需要达到报告的精度,甚至可以改进跨数据库验证。已经训练模型被用作pre-trained特征提取器插入作为输入一个简单的两层神经网络训练与CK+数据库。本实验未进行预处理操作。尽管实验简单,但是所取得的结果是有希望的,甚至增加了跨数据库实验的准确性(见第4节),而降低了相同数据库实验的准确性。这些结果表明,这种类型的深度学习方法可以更好地生成人脸表情识别的判别模型,使其能够在不受控制的场景下工作,这是目前该领域面临的挑战之一。作为未来的工作,该特征提取方法的应用将在其他问题上进行研究。此外,我们还想研究其他学习方法,以提高方法在未知环境下的鲁棒性(如光照条件、文化等)。此外,将使用Parkhi等人提出的面部描述符进行更多的测试。[83],使用精细的调整技术,其目的是调整一个已经训练好的深层神经网络,以专注于更具体的特征(在我们的例子中是表达式)。
附录A(Appendix A)
 表13
表13
用于bu3dfe数据库上的六个表达式的混淆矩阵
 表14
表14
用于bu3dfe数据库上的7个表达式的混淆矩阵。
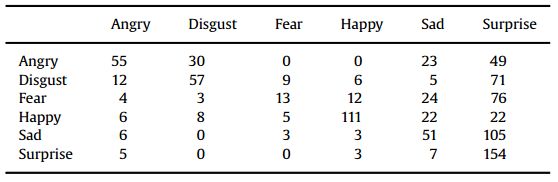 表15
表15
在跨数据库实验中,对bu3dfe数据库上的六个表达式进行混淆矩阵
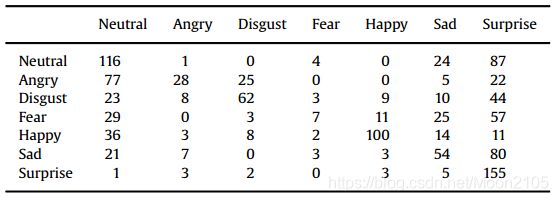 表16
表16
在跨数据库实验中,对bu3dfe数据库上的7个表达式进行混淆矩阵。
 表17
表17
JAFFE数据库上六个表达式的混淆矩阵
 表18
表18
JAFFE数据库中7个表达式的混淆矩阵。
 表19
表19
在跨数据库实验中,JAFFE数据库上六个表达式的混淆矩阵
 表20
表20
在跨数据库实验中,JAFFE数据库上的7个表达式的混淆矩阵