Hadoop学习(四)——Hive学习2
Hadoop学习(四)——Hive学习2
目录:
1、报错:Hive import json data建表报错:
2、报错:Hive load Json数据文件到表中,发现数据全部为null:
3、数据标签:给vType字段打标签:
4、报错:Sqoop从Hive中export数据到SqlServer时驱动问题:
5、Hive启用事务:
1、报错:Hive import json data建表报错:
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Cannot validate serde: org.openx.data.jsonserde.JsonSerDe
解决办法:
(1)进入目录:/usr/hdp/2.4.2.0-258/hive/lib
sudo git clone https://github.com/rcongiu/Hive-JSON-Serde.git

图1.1 截图1
(2)发现pom文件中没有2.4版本的profile,修改pom文件:
2.4.2
1.2.1
2.7.1
hadoop-common
hdp24
false
json-serde-cdh5-shim
UTF-8
json-serde-cdh5-shim
${hdp24.version}
${hdp24.hive.version}
${hdp24.hadoop.version}
cdh5
(3)执行mvn clean package -P hdp24,发现报错:
Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.10:test (default-test) on project json-serde: There are test failures.
这是由于测试代码遇到错误,停止编译,因此需要在该pom文件下该插件上加入这行:
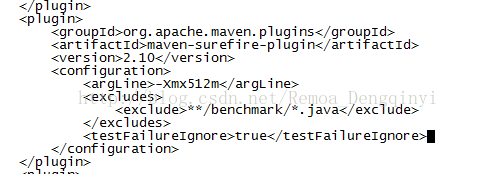
图1.2 截图2
(4)添加后重新执行mvn clean package -P hdp24成功编译,进入该目录:
/usr/hdp/2.4.2.0-258/hive/lib/Hive-JSON-Serde/json-serde/target,查看到如图所示文件:json-serde-1.3.9-SNAPSHOT-jar-with-dependencies.jar

图1.3 截图3
(5)将其加入到hive依赖包classpath下:
hive >add jar /usr/hdp/2.4.2.0-258/hive/lib/Hive-JSON-Serde/json-serde/target/json-serde-1.3.9-SNAPSHOT-jar-with-dependencies.jar;
(6)然后重新执行建表语句即可;
drop table qinyiTest;
create external table qinyiTest(
mid string comment "本帖id",
pid string comment "原帖id",
weibourl string comment "url地址",
content string comment "帖内容",
username string comment "用户名",
postTime string comment "发表时间",
repostsCount string comment "转发数",
commentsCount string comment "评论数",
attitudesCount string comment "点赞数",
spreadLevel string comment "转发层级",
followersCount string comment "粉丝数",
isReal string comment "是否水军",
vType string comment "用户类型"
)
comment "微博传播路径表"
partitioned by(uploaddata string)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' with SERDEPROPERTIES ("ignore.malformed.json" = "true")
stored as INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
;
图1.4 截图4
注意事项:
Hive SerDe(Serialize/Deserilize),序列化和反序列化。
①SerDe可以为表指定列,且对列指定相应的数据。
②当进程在进行远程通信时,彼此可以发送各种类型的数据,无论是什么类型的数据都会以二进制的形式在网络上传送。发送方需要把对象转化为字节序列才可以在网络上传输,称为对象序列化;接收方需要把字节序列恢复为对象,即对象的反序列化。
③Hive的反序列化是对key/value反序列化为hive table中的每个列的值。
2、报错:Hive load Json数据文件到表中,发现数据全部为null:
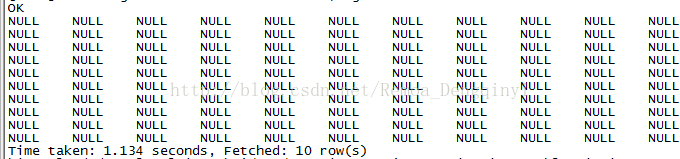
图2.1 截图5
原因:因为使用了序列化包org.openx.data.jsonserde.JsonSerDe,它是不支持格式化的json格式进行load的。
图2.2 截图6
解决办法:
将格式化后的json数据再转化为非格式化的就可以成功load数据了。
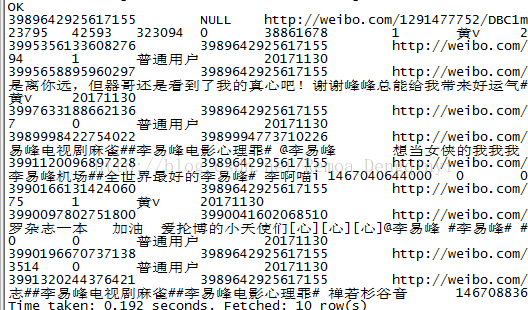
图2.3 截图7
将格式化的json文件转换为非格式化的Java类:
package com.dt.remoa.gen.utils;
import com.dt.remoa.gen.export.hotspread.domain.HotSpreadVO;
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import com.google.gson.stream.JsonReader;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
/**
* 将格式化的json文件转换为非格式化格式再输出
* @author Dengqinyi
* @since 2017/11/30
*/
public class Jsont {
public static void main(String[] args) throws Exception{
InputStream inputStream = new FileInputStream("C:\\Users\\Administrator\\Desktop\\testHive.txt");
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
String line = "";
StringBuffer sb = new StringBuffer();
while ((line = bufferedReader.readLine()) != null){
sb.append(line);
}
bufferedReader.close();
inputStream.close();
String jsonStr = sb.toString();
JsonReader reader = new JsonReader(new StringReader(jsonStr));
reader.setLenient(true);
List hotSpreadVOList = new ArrayList<>();
reader.beginArray();
while(reader.hasNext()){
reader.beginObject();
HotSpreadVO hotSpreadResultVO = new HotSpreadVO();
while(reader.hasNext()){
String tagName = reader.nextName();
if(tagName.equals("mid")){
hotSpreadResultVO.setMid(reader.nextString());
}else if(tagName.equals("pid")){
hotSpreadResultVO.setPid(reader.nextString());
}else if(tagName.equals("weiboUrl")){
hotSpreadResultVO.setWeiboUrl(reader.nextString());
}else if(tagName.equals("content")){
hotSpreadResultVO.setContent(reader.nextString());
}else if(tagName.equals("username")){
hotSpreadResultVO.setUsername(reader.nextString());
}else if(tagName.equals("postTime")){
hotSpreadResultVO.setPostTime(reader.nextLong());
}else if(tagName.equals("repostsCount")){
hotSpreadResultVO.setRepostsCount(reader.nextLong());
}else if(tagName.equals("commentsCount")){
hotSpreadResultVO.setCommentsCount(reader.nextLong());
}else if(tagName.equals("attitudesCount")){
hotSpreadResultVO.setAttitudesCount(reader.nextLong());
}else if(tagName.equals("spreadLevel")){
hotSpreadResultVO.setSpreadLevel(reader.nextInt());
}else if(tagName.equals("followersCount")){
hotSpreadResultVO.setFollowersCount(reader.nextLong());
}else if(tagName.equals("isReal")){
hotSpreadResultVO.setIsReal(reader.nextString());
}else if(tagName.equals("vType")){
hotSpreadResultVO.setvType(reader.nextString());
}
}
hotSpreadVOList.add(hotSpreadResultVO);
reader.endObject();
}
reader.endArray();
FileOutputStream fos = new FileOutputStream(new File("C:\\Users\\Administrator\\Desktop\\testHive2.txt"));
Writer writer = new OutputStreamWriter(fos);
Gson gson = new GsonBuilder().create();
for (int i = 0; i < hotSpreadVOList.size(); i++) {
String result = gson.toJson(hotSpreadVOList.get(i));
writer.write(result);
if(i != hotSpreadVOList.size() - 1){
writer.write("," + "\r\n");
}else{
writer.write("\r\n");
}
writer.flush();
}
writer.close();
}
} package com.dt.remoa.gen.export.hotspread.domain;
public class HotSpreadVO {
/**
* 微博mid
*/
private String mid;
/**
* 被转发微博的mid
*/
private String pid;
/**
* 微博帖链接
*/
private String weiboUrl;
/**
* 微博内容
*/
private String content;
/**
* 用户名
*/
private String username;
/**
* 发布时间
*/
private Long postTime;
/**
* 转发数
*/
private long repostsCount;
/**
* 评论数
*/
private long commentsCount;
/**
* 点赞数
*/
private long attitudesCount;
/**
* 转发层级
*/
private Integer spreadLevel;
/**
* 粉丝数
*/
private Long followersCount;
/**
* 是否去水军
*/
private String isReal;
/**
* 用户属性
*/
private String vType;
public String getMid() {
return mid;
}
public void setMid(String mid) {
this.mid = mid;
}
public String getPid() {
return pid;
}
public void setPid(String pid) {
this.pid = pid;
}
public String getWeiboUrl() {
return weiboUrl;
}
public void setWeiboUrl(String weiboUrl) {
this.weiboUrl = weiboUrl;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public Long getPostTime() {
return postTime;
}
public void setPostTime(Long postTime) {
this.postTime = postTime;
}
public long getRepostsCount() {
return repostsCount;
}
public void setRepostsCount(long repostsCount) {
this.repostsCount = repostsCount;
}
public long getCommentsCount() {
return commentsCount;
}
public void setCommentsCount(long commentsCount) {
this.commentsCount = commentsCount;
}
public long getAttitudesCount() {
return attitudesCount;
}
public void setAttitudesCount(long attitudesCount) {
this.attitudesCount = attitudesCount;
}
public Integer getSpreadLevel() {
return spreadLevel;
}
public void setSpreadLevel(Integer spreadLevel) {
this.spreadLevel = spreadLevel;
}
public Long getFollowersCount() {
return followersCount;
}
public void setFollowersCount(Long followersCount) {
this.followersCount = followersCount;
}
public String getIsReal() {
return isReal;
}
public void setIsReal(String isReal) {
this.isReal = isReal;
}
public String getvType() {
return vType;
}
public void setvType(String vType) {
this.vType = vType;
}
}3、数据标签:给vType字段打标签:
普通用户:打上“L00001”标签;
黄v用户:打上“L00002”标签;
蓝v用户:打上“L00003”标签;
微博达人用户:打上“L00004”标签;
insert overwrite table qinyiTest
partition(uploaddata='20171130')
select
mid,
pid,
weibourl,
content,
username,
postTime,
repostsCount,
commentsCount,
attitudesCount,
spreadLevel,
followersCount,
isReal,
case
when vType='黄v' then 'L00002'
when vType='蓝v' then 'L00003'
when vType='普通用户' then 'L00001'
when vType='微博达人' then 'L00004'
else null
end
as vType
from qinyiTest;查看打标签结果:
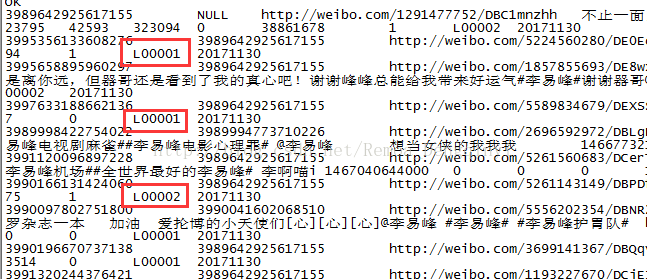
图3.1 截图8
查看标签为微博达人的数量:
select count(1) from qinyiTest where vType='L00004';
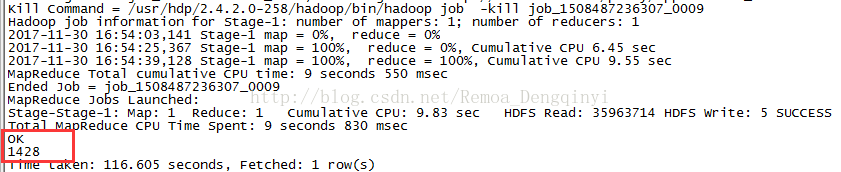
图3.2 截图9
4、报错:Sqoop从Hive中export数据到SqlServer时驱动问题:
sqoop export -Dmapreduce.job.queuename=队列名 --driver com.microsoft.sqlserver.jdbc.SQLServerDriver --connect "jdbc:sqlserver://IP地址:端口 ;databaseName=SQL Server数据库名;user=SQL Server用户名;password=SQL Server密码" --columns 列1,列2,……列n --hcatalog-table hive表名 --hcatalog-database hive数据库名 --table SQLServer表名 --mapreduce-job-name mapReduce作业名
出现报错信息:传入的请求具有过多的参数。该服务器支持最多2100个参数。请减少参数的数目,然后重新发送该请求。

图4.1 截图10
原因分析:
(1)Sqoop不附带第三方JDBC驱动程序,因此需要下载它们到服务器上的lib目录中,sqoop的位置在/usr/hdp/2.4.2.0 -258/sqoop/lib目录下;
(2)通过查看sqljdbc4.1.jar、sqljdbc4.2.jar以及sqljdbc.jar包的底层源码,sqlserver的驱动都是com.microsoft.sqlserver.jdbc.SQLServerDriver的,因此是与--driver参数无关。
(3)因为涉及到表的批量数据导入,而SQL Server本身是有相关机制的,SqlServer 对语句的条数和参数的数量都有限制,分别是 1000 和 2100,因此需要在Sqoop命令的最后加上--batch参数。
解决方法:
在Sqoop命令的最后加上--batch参数。
5、Hive启用事务:
(1)启用事务后,表必须是Bucket表,若存在表没有分桶,则会报错。
(2)只支持ORC模式。(文件压缩)
(3)方法:
在Ambari中,找到导航条Hive -> Configs,首先需要在Ambari上开启ACID事务。
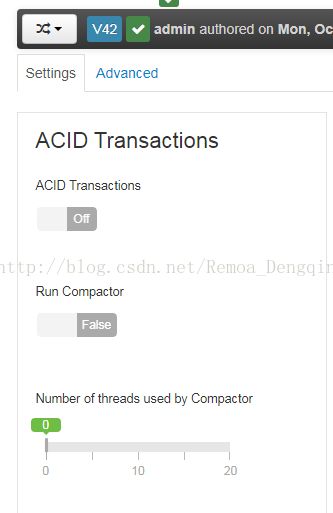
图5.1 截图11
选择Advanced,至少需要给hive-site添加如下六个参数。
(A)hive.support.concurrency true:支持并发操作
(B)hive.enforce.bucketing true:表必须分桶
(C)hive.exec.dynamic.partition.mode nonstrict:允许所有的分区字段都可以使用动态分区
(D)hive.txn.manager org.apache.hadoop.hive.ql.lockmgr.DbTxnManager :
HiveTxnManager的一个实现,它将事务存储在Metastore数据库中。
(E)hive.compactor.initiator.on true:是否在该metastore实例上运行启动器和垃圾清理线程。
(F)hive.compactor.worker.threads 按需求配,配置在该metastore实例上运行的工作线程数目。
可选参数配置:
(A)hive.compactor.worker.timeout 86400:单位为毫秒,即压缩作业在该时间内未完成将被宣布失败,压缩操作被重新排入队列。
(B)hive.txn.max.open.batch 500:事务的最大数量为500。
然后重启Hive。
(4)启用事务创表示例:
CREATE TABLE myuser(
id int,
name string
)
CLUSTERED BY (id) INTO 2 BUCKETS STORED AS ORC
TBLPROPERTIES ("transactional"="true");