mmap内核源码分析,基于内核版本3.10(一)
最近项目需要使用到mmap,因此对mmap内核中的实现进行学习,该博客基于Linux-3.10,相近版本可以做参考,如果版本跨度大需结合对应版本来进行学习。
一个用户态程序可以通过调用libc中的mmap(),将一个已打开文件的内容映射到它的用户空间。
mmap用户态函数原型:mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset)。
参数fd代表着一个已打开文件,offset为文件中的起点,而start为映射到用户空间中的起始地址,length则为长度。还有两个参数prot和flags,前者用于对所映射区间的访问模式,如可写、可执行等,后者则用于其他控制目的。
这里对用户态的mmap就不进行过多的讲解了,直接通过系统调用来进行内核态mmap的具体实现的学习。
用户态mmap通过系统调用sys_mmap2陷入内核,使用Source Insight打开Linux-3.10的内核源码(https://blog.csdn.net/SweeNeil/article/details/83684938)
unsigned long sys_mmap2(unsigned long addr, size_t len,
unsigned long prot, unsigned long flags,
unsigned long fd, unsigned long pgoff)
{
return do_mmap2(addr, len, prot, flags, fd, pgoff, PAGE_SHIFT-12);
}在sys_mmap2中直接返回了do_mmap2,然后我们跳转到do_mmap2来进行查看相关内容:
static inline unsigned long do_mmap2(unsigned long addr, size_t len,
unsigned long prot, unsigned long flags,
unsigned long fd, unsigned long off, int shift)
{
unsigned long ret = -EINVAL;
if (!arch_validate_prot(prot))
goto out;
if (shift) {
if (off & ((1 << shift) - 1))
goto out;
off >>= shift;
}
ret = sys_mmap_pgoff(addr, len, prot, flags, fd, off);
out:
return ret;
}do_mmap2是一个内联函数,其中主要调用了sys_mmap_pgoff函数,然后继续跳转到sys_mmap_pgoff函数,在使用Source Insight进行跳转查看时,发现该函数同样为一个系统调用,但是未找到函数体,其函数声明如下:
asmlinkage long sys_mmap_pgoff(unsigned long addr, unsigned long len,
unsigned long prot, unsigned long flags,
unsigned long fd, unsigned long pgoff);猜测在sys_mmap_pgoff中同样是调用的一个do_mmap_pgoff的函数(如果大家找到了欢迎评论说明),根据查找到的mmap内核代码的其他博客,可知应该是调用了do_mmap_pgoff。查看do_mmap_pgoff函数,找到了两个do_mmap_pgoff函数。一是在./mm/mmap.c中定义的函数do_mmap_pgoff,一个是在/mm/nommu.c中定义的do_mmap_pgoff函数。
到底哪一个为在执行mmap时被调用的函数呢,我们先打开这两个文件进行分析,看一下这两个文件是否有相应的描述信息,首先打开/mm/mmap.c,发现文件并没有什么描述信息,只有一个作者的信息,然后再打开/mm/nommu.c文件,发现了如下内容:
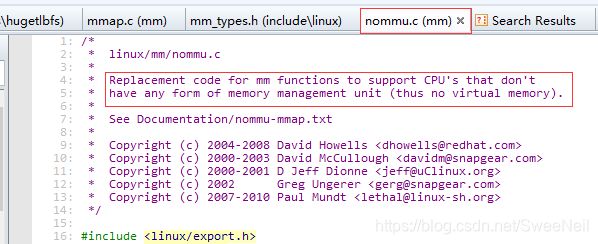
通过上面的描述信息可知,nommu.c中的代码就是mm函数的替换代码,用于支持没有任何形式的内存管理单元的CPU,其实这一点我们也可以从文件名nommu.c猜测这里面的代码应该是在没有MMU时会被运行的。
因此我们可以先对/mm/mmap.c中的do_mmap_pgoff进行分析:
1、/mm/mmap.c——>do_mmap_pgoff函数
在mm/mmap.c中查找到了函数do_mmap_pgoff的函数代码如下:
unsigned long do_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, unsigned long pgoff,
unsigned long *populate)
{
struct mm_struct * mm = current->mm;
struct inode *inode;
vm_flags_t vm_flags;
*populate = 0;
/*
* Does the application expect PROT_READ to imply PROT_EXEC?
*
* (the exception is when the underlying filesystem is noexec
* mounted, in which case we dont add PROT_EXEC.)
*/
if ((prot & PROT_READ) && (current->personality & READ_IMPLIES_EXEC))
if (!(file && (file->f_path.mnt->mnt_flags & MNT_NOEXEC)))
prot |= PROT_EXEC;
if (!len)
return -EINVAL;
if (!(flags & MAP_FIXED))
addr = round_hint_to_min(addr);
/* Careful about overflows.. */
len = PAGE_ALIGN(len);
if (!len)
return -ENOMEM;
/* offset overflow? */
if ((pgoff + (len >> PAGE_SHIFT)) < pgoff)
return -EOVERFLOW;
/* Too many mappings? */
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
/* Obtain the address to map to. we verify (or select) it and ensure
* that it represents a valid section of the address space.
*/
addr = get_unmapped_area(file, addr, len, pgoff, flags);
if (addr & ~PAGE_MASK)
return addr;
/* Do simple checking here so the lower-level routines won't have
* to. we assume access permissions have been handled by the open
* of the memory object, so we don't do any here.
*/
vm_flags = calc_vm_prot_bits(prot) | calc_vm_flag_bits(flags) |
mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
if (flags & MAP_LOCKED)
if (!can_do_mlock())
return -EPERM;
/* mlock MCL_FUTURE? */
if (vm_flags & VM_LOCKED) {
unsigned long locked, lock_limit;
locked = len >> PAGE_SHIFT;
locked += mm->locked_vm;
lock_limit = rlimit(RLIMIT_MEMLOCK);
lock_limit >>= PAGE_SHIFT;
if (locked > lock_limit && !capable(CAP_IPC_LOCK))
return -EAGAIN;
}
inode = file ? file_inode(file) : NULL;
if (file) {
switch (flags & MAP_TYPE) {
case MAP_SHARED:
if ((prot&PROT_WRITE) && !(file->f_mode&FMODE_WRITE))
return -EACCES;
/*
* Make sure we don't allow writing to an append-only
* file..
*/
if (IS_APPEND(inode) && (file->f_mode & FMODE_WRITE))
return -EACCES;
/*
* Make sure there are no mandatory locks on the file.
*/
if (locks_verify_locked(inode))
return -EAGAIN;
vm_flags |= VM_SHARED | VM_MAYSHARE;
if (!(file->f_mode & FMODE_WRITE))
vm_flags &= ~(VM_MAYWRITE | VM_SHARED);
/* fall through */
case MAP_PRIVATE:
if (!(file->f_mode & FMODE_READ))
return -EACCES;
if (file->f_path.mnt->mnt_flags & MNT_NOEXEC) {
if (vm_flags & VM_EXEC)
return -EPERM;
vm_flags &= ~VM_MAYEXEC;
}
if (!file->f_op || !file->f_op->mmap)
return -ENODEV;
break;
default:
return -EINVAL;
}
} else {
switch (flags & MAP_TYPE) {
case MAP_SHARED:
/*
* Ignore pgoff.
*/
pgoff = 0;
vm_flags |= VM_SHARED | VM_MAYSHARE;
break;
case MAP_PRIVATE:
/*
* Set pgoff according to addr for anon_vma.
*/
pgoff = addr >> PAGE_SHIFT;
break;
default:
return -EINVAL;
}
}
/*
* Set 'VM_NORESERVE' if we should not account for the
* memory use of this mapping.
*/
if (flags & MAP_NORESERVE) {
/* We honor MAP_NORESERVE if allowed to overcommit */
if (sysctl_overcommit_memory != OVERCOMMIT_NEVER)
vm_flags |= VM_NORESERVE;
/* hugetlb applies strict overcommit unless MAP_NORESERVE */
if (file && is_file_hugepages(file))
vm_flags |= VM_NORESERVE;
}
addr = mmap_region(file, addr, len, vm_flags, pgoff);
if (!IS_ERR_VALUE(addr) &&
((vm_flags & VM_LOCKED) ||
(flags & (MAP_POPULATE | MAP_NONBLOCK)) == MAP_POPULATE))
*populate = len;
return addr;
}从上述代码可以发现,在do_mmap_pgoff中调用了一个名为get_unmapped_area的函数,进入到该函数中,查看该函数的具体功能:
unsigned long
get_unmapped_area(struct file *file, unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags)
{
unsigned long (*get_area)(struct file *, unsigned long,
unsigned long, unsigned long, unsigned long);
unsigned long error = arch_mmap_check(addr, len, flags);
if (error)
return error;
/* Careful about overflows.. */
if (len > TASK_SIZE)
return -ENOMEM;
get_area = current->mm->get_unmapped_area;
if (file && file->f_op && file->f_op->get_unmapped_area)
get_area = file->f_op->get_unmapped_area;
addr = get_area(file, addr, len, pgoff, flags);
if (IS_ERR_VALUE(addr))
return addr;
if (addr > TASK_SIZE - len)
return -ENOMEM;
if (addr & ~PAGE_MASK)
return -EINVAL;
addr = arch_rebalance_pgtables(addr, len);
error = security_mmap_addr(addr);
return error ? error : addr;
}
从上述代码可以发现在get_unmapped_area中主要进行了匿名映射与文件映射的区分。如果为匿名映射,直接使用mm->get_unmapped_are直接获取虚拟内存空间(VMA),如果为文件映射,那么从file->f_op->get_unmapped_area中获取虚拟内存空间。
那么这个地址空间具体到底是怎么分配的呢,我们继续往下看,通过上述分析,说明get_unmapped_area并非真正实现分配虚拟内存空间的目的,它向下根据匿名映射和文件映射两种情况还调用了相应的函数,不过实现的函数名已经不是get_unmapped_area了,而是以函数指针的形式被调用执行。
在《深入理解Linux内核》这本书中,对get_unmapped_area函数有如下描述:
函数get_unmapped_area()调用文件对象的get_unmapped_area方法,如果已定义,就为文件的内存映射分配一个合适的线性地址区间。磁盘文件系统不会定义这么一个方法,那么get_unmapped_area就会调用内存描述符的get_unmapped_area方法。
对于这种钩子类型的函数,在其中必定存在大量的赋值,使用Source Insight直接Jump to Definition已经不能满足我们查看代码的需求了,因此使用Project->Search Project来进行查看
查询到了大量的结果如下:

可以看到对于get_unmapped_area在不同的应用场景下有不同的实现,通过查看这些具体实现然后分析得到他们大多数都有一个共同的特点那就是调用了一个名为:vm_unmapped_area 的函数

我们进入到vm_unmapped_area函数中来探究一下该函数的具体实现:
static inline unsigned long
vm_unmapped_area(struct vm_unmapped_area_info *info)
{
if (!(info->flags & VM_UNMAPPED_AREA_TOPDOWN))
return unmapped_area(info);
else
return unmapped_area_topdown(info);
}我们看到在vm_unmapped_area函数中,根据标志位来确定具体调用的函数,首先我们进入到第一个函数unmapped_area中:
unsigned long unmapped_area(struct vm_unmapped_area_info *info)
{
/*
* We implement the search by looking for an rbtree node that
* immediately follows a suitable gap. That is,
* - gap_start = vma->vm_prev->vm_end <= info->high_limit - length;
* - gap_end = vma->vm_start >= info->low_limit + length;
* - gap_end - gap_start >= length
*/
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma;
unsigned long length, low_limit, high_limit, gap_start, gap_end;
/* Adjust search length to account for worst case alignment overhead */
length = info->length + info->align_mask;
if (length < info->length)
return -ENOMEM;
/* Adjust search limits by the desired length */
if (info->high_limit < length)
return -ENOMEM;
high_limit = info->high_limit - length;
if (info->low_limit > high_limit)
return -ENOMEM;
low_limit = info->low_limit + length;
/* Check if rbtree root looks promising */
if (RB_EMPTY_ROOT(&mm->mm_rb))
goto check_highest;
vma = rb_entry(mm->mm_rb.rb_node, struct vm_area_struct, vm_rb);
if (vma->rb_subtree_gap < length)
goto check_highest;
while (true) {
/* Visit left subtree if it looks promising */
gap_end = vma->vm_start;
if (gap_end >= low_limit && vma->vm_rb.rb_left) {
struct vm_area_struct *left =
rb_entry(vma->vm_rb.rb_left,
struct vm_area_struct, vm_rb);
if (left->rb_subtree_gap >= length) {
vma = left;
continue;
}
}
gap_start = vma->vm_prev ? vma->vm_prev->vm_end : 0;
check_current:
/* Check if current node has a suitable gap */
if (gap_start > high_limit)
return -ENOMEM;
if (gap_end >= low_limit && gap_end - gap_start >= length)
goto found;
/* Visit right subtree if it looks promising */
if (vma->vm_rb.rb_right) {
struct vm_area_struct *right =
rb_entry(vma->vm_rb.rb_right,
struct vm_area_struct, vm_rb);
if (right->rb_subtree_gap >= length) {
vma = right;
continue;
}
}
/* Go back up the rbtree to find next candidate node */
while (true) {
struct rb_node *prev = &vma->vm_rb;
if (!rb_parent(prev))
goto check_highest;
vma = rb_entry(rb_parent(prev),
struct vm_area_struct, vm_rb);
if (prev == vma->vm_rb.rb_left) {
gap_start = vma->vm_prev->vm_end;
gap_end = vma->vm_start;
goto check_current;
}
}
}
check_highest:
/* Check highest gap, which does not precede any rbtree node */
gap_start = mm->highest_vm_end;
gap_end = ULONG_MAX; /* Only for VM_BUG_ON below */
if (gap_start > high_limit)
return -ENOMEM;
found:
/* We found a suitable gap. Clip it with the original low_limit. */
if (gap_start < info->low_limit)
gap_start = info->low_limit;
/* Adjust gap address to the desired alignment */
gap_start += (info->align_offset - gap_start) & info->align_mask;
VM_BUG_ON(gap_start + info->length > info->high_limit);
VM_BUG_ON(gap_start + info->length > gap_end);
return gap_start;
}从中可以看到这应该就是具体的分配函数了,同理unmapped_area_topdown的实现也是如此,函数unmapped_area_topdown的实现就位于unmapped_area代码的正下方,在/mm/mmap.c中,至此我们就追踪到了这里,大致了解了mmap的内核实现流程。
至于nommu.c中的do_mmap_pgoff可以通过与上述一致的阅读代码的方式来进行学习。
欢迎大家评论交流讨论~
参考内容:
1、Linux-3.10内核源代码
2、《深入理解Linux内核》