Python经典面试题
一、Python经典面试题
1、用你觉得最Python的方式来实现a、b元素交换
a,b=b,a
2、Python实现—个单例模式
-
单例模式确保某一个类只有一个实例存在
-
当你希望在整个系统中,某个类只能出现一个实例时,就可以使用单例对象
-
方法:是否是第一次创建对象,如果是首次创建对象,则调用父类
__new__()方法创建对象并返回 如果不是第一创建对象,直接返回第一次创建的对象即可
class Shopping:
instance = None #记录创建的对象,None说明是第一次创建对象
def __new__(cls, *args, **kwargs):
#第一次调用new方法,创建对象并记录
#第2-n次调用new方式时,不创建对象,而是直接放回记录的对象
#判断是否是第一次创建对象
if cls.instance==None:
cls.instance = object.__new__(cls)
return cls.instance
shop1 = Shopping()
shop2 = Shopping()
print(shop1,shop2)
3、简要谈谈你对Python函数式编程的了解
核心关注是解决问题的步骤,将解决问题的每个步骤封装成函数,通过函数的逐步调用,得到问题的处理结果,主要实现方式是函数式编程
4、Python中单个下划线和双下划线都有什么意义?
1、单下划线如:_name
意思是:不能通过from modules import * 导入,如需导入需要:from modules import _name
2、对象前面加双下划线如:__name
意思是:生命对象为私有
5、简要谈谈你对MysQL和Redis的了解
Redis基于内存,读写速度快,也可做持久化,但是内存空间有限,当数据量超过内存空间时,需扩充内存,但内存价格贵。
MySQL基于磁盘,读写速度没有Redis快,但是不受空间容量限制,性价比高。
大多数的应用场景是MySQL(主)+Redis(辅),MySQL做为主存储,Redis用于缓存,加快访问速度。需要高性能的地方使Redis,不需要高性能的地方使用MySQL。存储数据在MySQL和Redis之间做同步
6,列举一些在Linux下常用的命令
1.展示目录列表命令ls(list)
pwd:显示目前的目录
2.切换目录命令cd
3.目录的创建(mkdir)和删除(rmdir)命令
4.文件的创建(touch)和删除(rm)命令
5.文件打包或解压命令tar
6.cp (复制文件或目录)
7.rm (移除文件或目录)
8.mv (移动文件与目录,或修改名称)
9.cat 由第一行开始显示文件内容
tac 从最后一行开始显示,可以看出 tac 是 cat 的倒著写!
nl 显示的时候,顺道输出行号!
more 一页一页的显示文件内容
less 与 more 类似,但是比 more 更好的是,他可以往前翻页!
head 只看头几行
tail 只看尾巴几行
7、列举一些你常用的git命令或操作
1、git init
使用我们指定目录作为Git仓库
2、git add filename
可以使用add… 继续添加任务文件
3、git commit -m “Adding files”
我们将它们提交到仓库
4、我们先从服务器克隆一个库并上传。
git clone ssh://example.com/~/www/project.git
5、现在我们修改之后可以进行推送到服务器。
git push ssh://example.com/~/www/project.git
6、从非默认位置更新到指定的url
git pull http://git.example.com/project.git
7、git status
查看git状态
8、一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有都多种跳法
解法一,用递归
class Solution:
def jumpFloor(self, number):
# write code here
flo = []
for i in range(number):
if i ==0:
flo.append(1)
elif i ==1:
flo.append(2)
else:
flo.append(flo[i-1]+flo[i-2])
return flo.pop()
解法二,用迭代
class Solution:
def jumpFloor(self, number):
# write code here
a,b=1,2
if number==1:
return a
if number == 2:
return b
for i in range(number-1):
a,b = b,a+b
return a
9、用Python实现二分查找算法
二分查找又称折半查找,它是一种效率较高的查找方法
算法思想: 首先,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功
优缺点: 折半查找法的优点是比较次数少,查找速度快,平均性能好;其缺点是要求待查表为有序表,且插入删除困难,因此,折半查找方法适用于不经常变动而查找频繁的有序列表
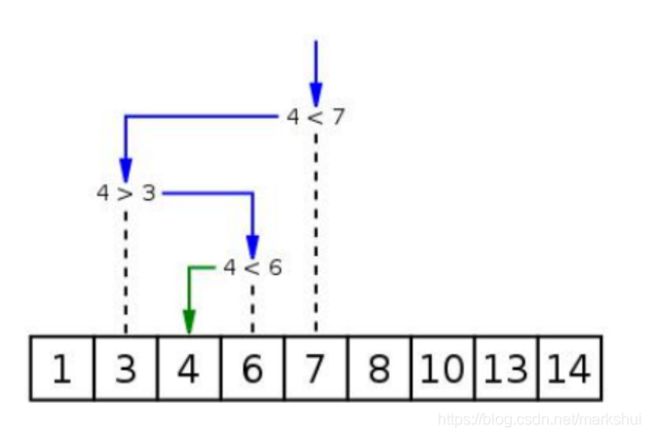
def binary_chop(alist, data):
"""
递归解决二分查找
:param alist:
:return:
"""
n = len(alist)
if n < 1:
return False
mid = n // 2 #
if alist[mid] > data:
return binary_chop(alist[0:mid], data)
elif alist[mid] < data:
return binary_chop(alist[mid + 1:], data)
else:
return True
10、给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那两个整数,并返回他们的数组下标
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
题解:
参考了大神们的解法,通过哈希来求解,这里通过字典来模拟哈希查询的过程
个人理解这种办法相较于方法一其实就是字典记录了 num1 和 num2 的值和位置,而省了再查找 num2 索引的步骤
方法一:
def twoSum(nums, target):
hashmap={
}
for ind,num in enumerate(nums):
hashmap[num] = ind
for i,num in enumerate(nums):
j = hashmap.get(target - num)
if j is not None and i!=j:
return [i,j]
方法二:
不需要 mun2 不需要在整个 dict 中去查找。可以在 num1 之前的 dict 中查找,因此就只需要一次循环可解决
def twoSum(nums, target):
hashmap={
}
for i,num in enumerate(nums):
if hashmap.get(target - num) is not None:
return [i,hashmap.get(target - num)]
hashmap[num] = i #这句不能放在if语句之前,解决list中有重复值或target-num=num的情况