A Simple Baseline for Multi-Object Tracking(FairMOT)——原理及代码测试
A Simple Baseline for Multi-Object Tracking(FairMOT)
Paper:https://arxiv.org/abs/2004.01888
Github:https://github.com/ifzhang/FairMOT
这个模型最近在mot上很火,在MOT的多个数据集上取得了很好的成绩,这篇文章想总结自己在阅读和测试代码的时候一下看法。
近年来,作为多目标跟踪的核心组件的目标检测和重新识别取得了显着进展。 但是,很少有人关注在单个网络中完成两项任务以提高推理速度。沿此路径进行的初始尝试最终导致结果降级,这主要是因为未正确学习重新标识分支。 在这项工作中,这篇文章的作者研究了故障背后的根本原因,并因此提出了解决问题的简单基准。 它以30 fps播放速度明显优于公共数据集上的最新技术。
一、文中在简介中提到的问题
1、现状
最先进的方法通常通过两个独立的模型解决该问题:检测模型首先通过对图像中的框进行边界界定来定位感兴趣的对象,然后,关联模型为每个边界框提取重新标识(Re-ID)特征,并根据在特征上定义的某些度量将其链接到现有轨道之一。近年来,分别在对象检测和Re-ID 上取得了显着进步,这反过来又提高了跟踪性能。但是,这些方法无法以视频速率执行推理,因为两个网络不共享功能。
随着多任务学习的成熟,联合检测物体并学习Re-ID特征的单步方法已开始引起更多关注。由于两个模型共享大多数特征,因此它们具有显着减少推理时间的潜力。然而,与两步法相比,单步法的准确性通常会显着下降。特别是,ID开关的数量增加了很多,如实验部分所示。结果表明,将这两项任务结合起来并非易事,应谨慎对待。
2、锚点的对齐不行,无锚点更容易对齐中心

图1:(a)黄色和红色的锚点造成了估计相同的ID(穿蓝色衬衫的人),尽管图像块非常不同。此外,基于锚的方法通常在粗网格上运行。因此,很有可能在锚点(红色或黄色星形)提取的特征未与对象中心对齐。 (b)免锚的做法受歧义的影响较小。
作者对影响跟踪器准确性的关键性因素做了以下的分析:
(1)、基于锚点的方法不适合Re-ID
当前的单步法跟踪器都是基于锚的,因为它们是从对象检测器修改而来的。但是,有两个原因造成了锚点不适合学习Re-ID功能。首先,对应于不同图像补丁的多个锚点可能负责估计同一对象的身份。这导致网络的严重歧义。有关说明,请参见图1。此外,通常会将特征图降级采样8次以平衡精度和速度。这对于检测是可以接受的,但对于ReID来说太粗糙了,因为对象中心可能与在粗略锚点位置提取的用于预测对象身份的特征不对齐。文章中提出解决该问题的方法,是通过将MOT问题处理为位于高分辨率特征图顶部的像素级关键点(对象中心)估计和身份分类问题。
(2)、多层特征聚合
这对于MOT尤为重要,因为Re-ID功能需要利用高维和低维的特征来处理所有大的和小的的物体。在实验中观察到,由于提高了处理尺寸变化的能力,这有助于减少单步法的身份切换。请注意,对于两步方法而言,改进并不那么重要,因为在裁剪和调整大小操作之后,对象将具有相似的比例。
(3)、ReID特征的维数
以前的ReID方法通常学习高维特征,并在其基准上取得了可喜的结果。但是,我们发现低维特征实际上对MOT更好,因为它的训练图像比ReID少(我们不能使用ReID数据集,因为它们仅提供裁剪后的人物图像)。学习低维特征有助于减少过拟合小数据的风险,并提高跟踪的稳健性。
标注:针对于第三点实际存在疑问,一开始公布的Fairmot版本用的reid分支是128维度的,但是后来作者团队在MOT20上刷出了MOTA58.7的指标,也更新了github上的Fairmot模型,这时候用的reid维度已经改为512维度,与通用的reid模型接近。但是在实验中发现reid上效果仍然在人员交集处容易跑其他人身上,应该是没有充分训练。
二、实现结构

图2:我们的一步法MOT跟踪器概述。首先将输入图像馈送到编码器-解码器网络,以提取高分辨率特征图(步幅= 4)。然后,我们添加两个简单的并行头,分别用于预测边界框和Re-ID特征。预测对象中心的特征被提取出来以进行时间边界框链接。
方法的概述如图2所示。首先采用无锚对象检测方法来估计高分辨率特征图上的对象中心。消除锚点减轻了歧义性问题,并且高分辨率特征图的使用使Re-ID特征能够更好地与对象中心对齐。然后,网路中添加了一个并行分支,用于估算用于预测对象身份的逐像素Re-ID特征。特别是,通过学习了低维Re-ID特征,这些特征不仅减少了计算时间,而且提高了特征匹配的稳健性。此外,为骨干网络配备了“深层聚合”运算符,以融合来自多个层的要素,以便处理不同规模的对象。
1、骨干网络(Backbone Network)
文中采用ResNet-34作为骨干网络,为了在精度和速度之间取得良好的平衡。 为了适应不同尺度的对象,将深层聚合(DLA)的变体应用于主干,如图2所示。 与最初的DLA不同,它在低级和高级特征之间有更多的跳过连接,类似于特征金字塔网络(FPN)。 此外,上采样模块中的所有卷积层都被变形卷积层所取代,这样它们就可以根据对象尺度和姿势动态地适应接收域。这些修改也有助于缓解对齐问题。得到的模型命名为DLA-34。将输入图像的大小表示为Himage×Wimage,则输出特征映射的形状为C×H×W,其中H=Himage/4和W=Wimage/4。
2、物体检测分支(Object Detection Branch)
在骨干网络之后,将对象检测视为基于中心的高分辨率特征映射上的边界框回归任务。 特别是将三个并行回归头附加到骨干网络中,分别估计热图、对象中心偏移和框的大小。通过将3×3卷积(有256个通道)应用于骨干网络的输出特征映射来实现每个头,然后是一个1×1卷积层,生成最终目标。
热图头(Heatmap Head)
这个负责估计对象中心的位置。这里采用了基于热图的表示,这是地标点估计任务上的标准。尤其是,热图的维数为1×H×W。 如果热图中某个位置的响应与GT中心重叠,则该响应将是一个。响应随着热图中位置与对象中心之间的距离呈指数衰减。
中心偏移头(Center Offset Head)
这个头负责更精确地定位对象。回想一下,特征映射的步长是四个,这将引入不可忽略的量化误差。这可能在检测中提高很低,但它对于跟踪至关重要,因为Re-ID特征应该根据精确的对象中心提取。 在实验中发现,ReID特征与对象中心的仔细对齐对于性能至关重要。
框大小头(Box Size Head)
这个头负责估计目标包围盒在每个锚位置的高度和宽度。该头与Re-ID特征没有直接关系,但定位精度会影响目标检测性能的评价。
3、身份嵌入分支(Identity Embedding Branch)
身份嵌入分支的目标是生成能够区分不同对象的特征。理想情况下,不同对象之间的距离应该大于同一对象之间的距离。为了实现这一目标,这部分应用了一个卷积层,在骨干特征的顶部有128个核,为每个位置提取身份嵌入特征,得到的特征图为E∈R^(128×W×H), 从特征映射中提取对象在(x,y)处的Re-ID特征Ex,y∈R^(128)。
4、损失函数
1)Heatmap Loss
考虑到正负样本不均衡问题,作者采用了focal loss的形式。

其中M(x,y)表示的是heatmap在(x,y)处存在目标的概率。
2)Offset and Size Loss
采用L1 loss

3)Identity Embedding Loss
从热图上的对象中心(Ecix,Eciy)。 我们在该位置提取一个身份特征向量Exi,yi,并学习将其映射到类分布向量p(K)。作者采用了identification式的分类框架,这里面的L^i(k)就是GT中不同的ID的one-hot表示,损失为:

5、在线跟踪
这部分解释了模型的推断,以及如何使用检测结果和身份嵌入来执行框跟踪。
1)模型推断
网络以大小为1088×608的图像作为输入,这与以前的工作JDE相同。 在预测的热图之上,我们根据热图分数执行非最大抑制(NMS)来提取峰值关键点。我们保留热图分数大于阈值的关键点的位置。然后,根据估计的偏移量和框大小计算相应的包围框。 我们还在估计的对象中心提取标识嵌入。
2)在线框连接
我们使用标准的在线跟踪算法来实现框链接。我们根据第一帧中的估计框初始化了许多跟踪。在随后的帧中,我们根据Re-ID特性和IoU的测量距离将这些框链接到现有的轨迹。我们还使用卡尔曼滤波器来预测当前帧中轨迹的位置。 如果它离链接检测太远,我们将相应的成本设置为无穷大,从而有效地防止了检测与大运动的链接。我们在每个时间步骤中更新跟踪器的外观特性,以处理外观变化,如KCF。
三、实验
1、训练数据集
我们将来自六个公共数据集的训练图像结合起来,组成一个大型的训练数据集,用于人类检测和搜索。特别是ETH和CityPerson数据集只提供边界框注释,因此我们只对它们进行检测分支的训练。CalTech, MOT17, CUHK-SYSU和PRW数据集提供了边界框和身份注释,我们在这些注释上训练了检测和身份嵌入分支。
2、实现细节
用了12的batch size,用Adam训练了30个epochs,前面用10-4学习率,20~27用10-5和10^-6学习率,在两张RTX2080上跑了30小时。
3、对比实验
1)Anchor-based vs. Anchor-free
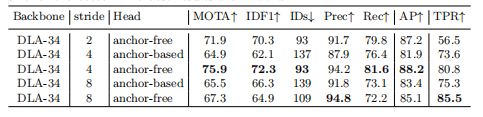
2)不同多尺度融合框架对于Reid的影响


3)Reid的维度的影响

作者公布的在各个MOT数据集上的指标。

四、测试
配置了Github上的开源代码,下载作者开源的模型在其他的数据集测试了下,效果见下图。
检测效果很好,但是仍然存在id switch的问题,尤其是在人群密集的地方,hrnet和dla34的效果差不多,我同时也测试了mot20上训练的dla34模型发现效果并没有达到想象。
杂乱的检测结果实在太多了,这也可能和这个模型在密集场景没有充分训练过拟合了mot20有关。
总结下代码测试后的看法
1、这个模型reid没有充分训练,所以id的切换会比较频繁,即使外观有很大差异,理论上reid训练好的对此应该不存在这个问题。文中把reid 的维数降低了,因为它是一个one-shot的结构,没法用裁剪的reid数据集训练,所以只能减少reid的影响,在新版本提高了。
2、DLA-34在中小型对象上主要优于HR NetV2,在MOT20上行人目标密集,作者也是基于DLA34进行训练。
参考文献:
【1】paper and github(开头已经给出)
【2】https://zhuanlan.zhihu.com/p/127738264
【3】https://zhuanlan.zhihu.com/p/126558285