Kubernetes_pod
Kubernetes Pod
文章目录
-
-
- Kubernetes Pod
- @[toc]
-
-
- Pod组成
- Pod与容器与Node的关系
- Pod资源定义文件
- Pod用法
- 静态Pod
- Pod的资源配置
- Pod生命周期与重启策略
-
- 生命周期
- 重启策略
- Pod的共享资源
-
- 网络
- 存储
- Pod EndPoint和Volume
- 在这里插入图片描述
-
-
- Pod配置管理
-
- configMap
-
- 使用场景
- 创建configMap
- Pod使用configMap
- configMap限制条件
- Pod健康检查
-
- LivenessProbe
- ReadinessProbe
- 用法
- Pod调度
-
- Deployment/RC--全自动调度
- NodeSelector--定向调度
- NodeAffinity--Node亲和性调度
- PodAffinity--Pod亲和与互斥调度策略
- Taints和Tolerations
-
- Toleration规则
- DaemonSet--在每个Node上调度一个Pod
- Job--批处理调度
- CronJob--定时任务
- Pod扩容和缩容
-
- 手动扩容和缩容模式
- 自动扩容和缩容模式
- Pod升级和回滚
-
- Deployment升级
-
- 方式
- 做法
- 保证服务不停
- Deployment回滚
-
- kubectl rolling-update命令
- Downward API(在容器内获取Pod信息)
-
- 环境变量方式--将Pod信息注入为环境变量
- 环境变量方式--将容器资源信息注入为环境变量
- volume挂载方式
文章目录
-
-
- Kubernetes Pod
- @[toc]
-
-
- Pod组成
- Pod与容器与Node的关系
- Pod资源定义文件
- Pod用法
- 静态Pod
- Pod的资源配置
- Pod生命周期与重启策略
-
- 生命周期
- 重启策略
- Pod的共享资源
-
- 网络
- 存储
- Pod EndPoint和Volume
-
- 在这里插入图片描述
-
-
- Pod配置管理
-
- configMap
-
- 使用场景
- 创建configMap
- Pod使用configMap
- configMap限制条件
- Pod健康检查
-
- LivenessProbe
- ReadinessProbe
- 用法
- Pod调度
-
- Deployment/RC--全自动调度
- NodeSelector--定向调度
- NodeAffinity--Node亲和性调度
- PodAffinity--Pod亲和与互斥调度策略
- Taints和Tolerations
-
- Toleration规则
- DaemonSet--在每个Node上调度一个Pod
- Job--批处理调度
- CronJob--定时任务
- Pod扩容和缩容
-
- 手动扩容和缩容模式
- 自动扩容和缩容模式
- Pod升级和回滚
-
- Deployment升级
-
- 方式
- 做法
- 保证服务不停
- Deployment回滚
-
- kubectl rolling-update命令
- Downward API(在容器内获取Pod信息)
-
- 环境变量方式--将Pod信息注入为环境变量
- 环境变量方式--将容器资源信息注入为环境变量
- volume挂载方式
-
-
Kubernetes中调度的最基本单位Pod。
kube-controller-manager用来控制Pod的状态和生命周期。
Pod代表着集群中运行的进程。
Pod组成
每个pod都有一个根容器,Pause容器。
Pause容器,又叫Infra容器,官方使用的是gcr.io/google_containers/pause-amd64:3.0容器,也可以自己定义。kubernetes中的pause容器主要为每个业务容器提供以下功能:
- 在pod中担任Linux命名空间共享的基础;
- 启用pid命名空间,开启init进程。
Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pasuse容器,每个Pod还包含一个或多个紧密相关的用户业务容器。用户业务容器可以只有一个也可以有多个:
- 一个Pod中运行一个容器。“每个Pod中一个容器”的模式是最常见的用法;在这种使用方式中,你可以把Pod想象成是单个容器的封装,kuberentes管理的是Pod而不是直接管理容器。
- 在一个Pod中同时运行多个容器。一个Pod中也可以同时封装几个需要紧密耦合互相协作的容器,它们之间共享资源。
Kubernetes为每个Pod都分配了IP,为Pod IP,一个Pod里的多个容器共享Pod IP地址。Kubernetes要求底层网络支持集群内任意两个Pod之间的TCP/IP直接通信,通过虚拟二层网络技术来实现,因此,一个Pod里的容器与另外主机上的Pod容器可以直接通信。

使用该结构的理由:
- 在一组容器作为一个单元的情况下,我们难以对“整体”简单地进行判断及有效地进行行动。例如,一个容器死亡了,是整体死亡吗?一个Pause容器作为Pod的根容器,以它的状态代表整个容器组的状态就可以解决这个问题。
- Pod里的多个业务容器共享Pasuse容器的IP,共享Pause容器挂载的Volume,这样可以简化业务容器之间的通信问题,也很好地解决了他们之间的文件共享问题。
Pod与容器与Node的关系
Pod的两种类型:普通的Pod及静态的Pod,后者不存放在Kubernetes的etcd存储里,而是存放再某个具体的Node上的一个具体文件中,并且只在此Node上启动运行。而普通的Pod一旦被创建,就会被放入到etcd中存储,随后会被Kubernetes Master调度到某个具体的Node上并进行绑定,随后改Pod被对应的Node上的Kubelet京城实例化成一组相关的Docker 容器并启动起来。在默认情况下,当Pod里的某个容器停止时,Kubernetes,会自动检测到这个问题并且重新启动这个Pod(重启Pod里的所有容器),如果Pod所在的Node宕机,则会将这个Node上的所有Pod重新调度到其他节点上。
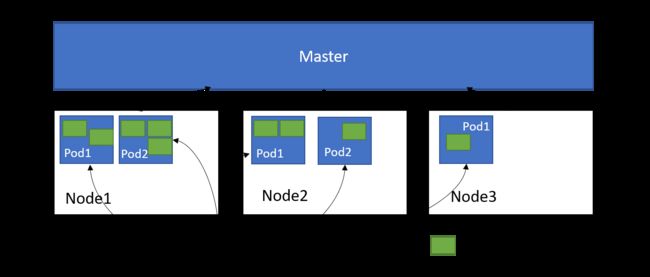
Pod资源定义文件
Kubernetes里的所有资源对象都可以采用yaml或者JSON格式的文件阿里定义或描述:
出自[资源定义文件][https://www.cnblogs.com/FRESHMANS/p/8444214.html]
# yaml格式的pod定义文件完整内容:
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #必选,Pod所属的命名空间
labels: #自定义标签
- name: string #自定义标签名字
annotations: #自定义注释列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存清楚,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always | Never | OnFailure] #Pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork: false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {
} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
Pod用法
在使用Dokcer时,可以使用docker run命令创建并启动一个容器。Kubernetes系统中对长时间运行容器的要求是:其主程序需要一直在前台执行。如果启动脚本为
nohup ./run.sh &
那kubelet创建包含这个容器的Pod之后运行完该命令,即认为Pod执行结束,将立刻销毁该Pod。如果为该配置ReplicaController,则系统将会监控到该Pod已经终止,之后根据RC定义的副本数量,又重新创建一个Pod。一旦创建新的Pod,又重复之前的动作,那就陷入死循环。因此,Docker镜像内主程序必须以一个前台命令作为启动命令。
从前面知道Pod可以由一个或多个容器组成,所以对应的yaml如下:
apiVersion: v1
kind: Pod
metadata:
name: redis-php
labels:
name: redis-php
spec:
containers:
- name: frontend
image: kubeguid/guestbook-php-frontend:localredis
ports:
- containerPort: 80
- name: redis
image: kubeguid/redis-master
ports:
- conatainerPort: 6379
$ kubectl create -f frontend-localredis-pod.yaml
静态Pod
静态Pod是有kubelet进行管理的仅存在于特定Node上的Pod。不能通过API Server进行管理,无法与ReplicationController、Deployment或者DaemonSet进行关联,并且kubelet也无法对他们进行健康检查。静态Pod总是由kubelet进行创建,并且只是在kubelet所在的Node上运行。由于静态Pod只受所在节点的kubelet控制,可以有效预防通过kubectl、或管理工具操作的误删除,可以用来部署核心组件应用。保障应用服务总是运行稳定数量和提供稳定服务。
创建静态Pod的两种方式:
-
配置文件方式
需要设置kubelet的启动参数“–config”,指定kubelet需要监控的配置文件所在的目录,kubelet会定期扫描该目录,并根据改目录中的.yaml或者.json文件进行创建操作。配置完后,要重启kubelet服务。
假设配置目录为/etc/kubelet.d,配置启动参数:–config=/etc/kubelet.d/,重启kubelet服务。
由于静态Pod无法通过API Server直接管理,所以在Master节点尝试删除这个Pod,将会器变成Pending状态,且不会被删除。删除这个Pod只能到这个Node上,将其定义文件从/etc/kubelet.d/中移除。
-
HTTP方式
通过设置kubelet的启动参数“–manifest-url”,kubelet将会定期从该URL地址下载Pod的定义文件,并以.yaml或.json文件的格式进行解析,然后创建Pod。
Pod的资源配置
当前可以设置限额的计算资源有CPU与Memory两种,其中CPU的资源单位为CPU(Core)的数量,是一个绝对值非相对值。在Kubernetes里,通常以千分之一的CPU配额为最小单位,用m来表示。通常一个容器的CPU配额被定义为100300m,即占用0.10.3个CPU。由于CPU配额是一个绝对值,所以无论在拥有一个Core的机器上,还是拥有48个Core的机器上,100m这个配额所代表的的CPU的使用量是一样的。Memory配额也是一个绝对值。
在Kubernetes里,一个计算资源进行配额限定需要设定以下两个参数
- Request:该资源的最小申请量,系统必须满足要求。
- Limits:改资源最大允许使用的量,不能被突破,当容器视图使用超过这个量的资源时,可能会被Kubernetes kill并重启。
通常我们会把Request设置为一个比较小的数值,符合容器平时的工作附在情况下的资源需求,而把Limit设置为峰值附在情况下资源占用的最大量。
1Mi = 1024 * 1024
1M = 1000 * 1000
spec:
containers:
- name: db
image: mysql
resources:
requests:
memory: "64Mi"
cpu: "250m"
Limits:
memory: "128Mi"
cpu: "500m"
Pod生命周期与重启策略
生命周期
Pod 的 status 字段是一个 PodStatus 对象,PodStatus中有一个 phase 字段。
Pod 的相位(phase)是 Pod 在其生命周期中的简单宏观概述。
下面是 phase 可能的值:
- 挂起(Pending):API Server 已经创建该Pod,但Pod内还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程。
- 运行中(Running):该 Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
- 成功(Succeeded):Pod 中的所有容器都被成功终止,并且不会再重启。
- 失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。
- 未知(Unknown):因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败。
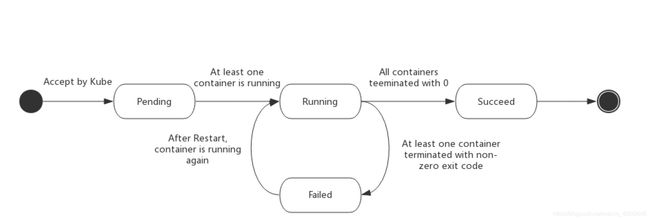
重启策略
Pod的重启策略(RestartPolicy)应用于Pod内的所有容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet根据RestartPolicy的设置来进行相应的操作。
Pod重启策略如下:
- Always(默认):当容器失败时,由kubelet自动重启该容器;
- OnFailure:当容器终止运行且退出码不为0时,由kubelete自动重启该容器;
- Never:不论容器运行状态如何,kubelet都不会重启该容器。
Pod的重启策略与控制方面息息相关,当前可用于管理Pod的控制器包括ReplicationController、Job、DaemonSet及直接通过kubelet管理(静态Pod)。每种控制器对Pod的重启策略要求如下:
- RC和DaemonSet:必须设置为Always,需要保证该容器持续进行;
- Job:OnFailue或Nerver,确保容器执行完成后不再重启;
- kubelet:在Pod失效时自动重启它,不论将RestartPolicy设置为什么值,也不会对Pod进行健康检查。
Pod的共享资源
网络
每个Pod都会被分配一个唯一的IP地址。Pod中的所有容器共享网络空间,包括IP地址和端口。Pod内部的容器可以使用localhost互相通信。Pod中的容器与外界通信时,必须分配共享网络资源(例如使用宿主机的端口映射)
存储
可以为一个Pod指定多个共享的Volume。Pod中的所有容器都可以访问共享的volume。Volume也可以用来持久化Pod中的存储资源,以防容器重启后文件丢失。
Pod EndPoint和Volume
Pod的IP加上这里的容器端口,就组成了EndPoint,它代表着此Pod里的一个服务进程的对外通信地址。一个Pod可能存在多个EndPoint的情况。
Pod Volume是定义在Pod之上,然后被各个容器挂载到自己的文件系统中。
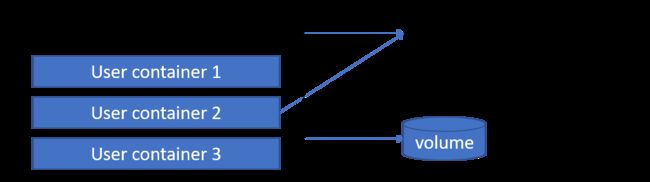
Pod配置管理
configMap
kubernetes从v1.2开始加入,许多应用程序会从配置文件、命令行参数或环境变量中读取配置信息。这些配置信息需要与docker image解耦,你总不能每修改一个配置就重做一个image吧?ConfigMap API给我们提供了向容器中注入配置信息的机制,ConfigMap可以被用来保存单个属性,也可以用来保存整个配置文件或者JSON二进制大对象。
使用场景
- 生成为容器内的环境变量
- 设置容器启动命令的启动参数
- 以volume的形式挂载为容器内部的文件或目录
创建configMap
-
通过yaml文件创建
apiVersion: v1 kind: ConfigMap metadata: name: cm-appvars data: apploglevel: info appdatadir: /var/data$ kubectl create -f cm-appvars.yaml -
通过kubectl命令行方式创建
不使用yaml文件,直接通过kubectl create configmap也可以创建ConfigMap:
- 通过–from-file参数从文件中进行创建,可以指定key的名称,也可以在一个命令行中创建包含多个key的ConfigMap
- 通过–from-file参数从目录中进行创建,该目录下的每个配置文件名都被设置为key,文件的内容设置为value
- –from-literal从文本中进行创建,直接将指定key#=value#创建为ConfigMap的内容
Pod使用configMap
容器应用对ConfigMap的使用有以下方法:
-
通过环境变量方式使用ConfigMap
以上面创建的ConfigMap为例,Pod的yaml文件如下:
apiVersion: v1 kind: Pod metadata: name: cm-test-pod spec: containers: - name: cm-test image: busybox command: [ "/bin/sh","-c","env | grep APP" ] env: - name: APPLOGLEVEL valueFrom: configMapKeyRef: name: cm-appvars key: apploglevel - name: APPDATADIR valueFrom: configMapKeyRef: name: cm-appvars key: appdatadir restartPolicy: Never在kubernetes v1.6加入字段envFrom,实现在Pod环境内将ConfigMap中所有定义的key=value自动生成环境变量
apiVersion: v1 kind: Pod metadata: name: cm-test-pod spec: containers: - name: cm-test image: busybox command: [ "/bin/sh","-c","env | grep APP" ] envFrom: configMapKeyRef: name: my-appvars restartPolicy: Never注意:如果环境变量的命名不规范([a-zA-Z_][a-zA-Z_0-9]*),系统将跳过该条环境变量的创建,但不影响Pod的启动。
-
通过volumeMount使用ConfigMap
apiVersion: v1 kind: Pod metadata: name: cm-test-app spec: containers: - name: cm-test-app image: kubeguide/tomcat-app:v1 ports: - containerPort: 8080 volumeMounts: - name: serverxml #引用volume名 mountPath: /configfiles # 挂载到容器内的目录 volumes: - name: serverxml configMap: name: cm-appconfigfiles items: - key: key-serverxml path: server.xml # value将server.xml文件名进行挂载 - key: key-loggingproperties path: logging.properties # value将logging.properties文件名挂载创建Pod之后,在/configfiles下就会有server.xml和logging.properties。
如果在引用configMap的时候不指定items,则使用volumeMount方式在容器内的目录为每一个item生成一个文件名为key的文件。
configMap限制条件
- ConfigMap必须在Pod之前创建
- ConfigMap受namespace限制,只有处于相同Namespaces中的Pod可以引用它
- ConfigMap中的配额管理还未能实现
- kubelet只支持可以被API Server管理的Pod使用ConfigMap
Pod健康检查
通过两种探针来检查,如下:
LivenessProbe
用于判断容器是否存活(running状态),如果LivenessProbe探针探测到容器不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含LivenessProbe探针,那kubelet认为LivenessProbe返回值都是success;
ReadinessProbe
用于判断容器是否启动完成(read状态),可以接受请求。有时,应用程序暂时无法对外部流量提供服务。 例如,应用程序可能需要在启动期间加载大量数据或配置文件。 在这种情况下,你不想杀死应用程序,但你也不想发送请求。如果ReadinessProbe探针检测到失败,则Pod的状态将被修改。Endpoint Controller将从Service的EndPoint中删除包含该容器所在Pod的Endpoint。
二者区别
用法
kubelet定期执行LivenessProbe探针来诊断容器的健康状况,下面yaml文件中提到的两个时间:
- initialDelaySeconds:启动容器后进行首次健康检查的等待时间,单位为s;
- timeoutSeconds:健康检查发送请求后等待响应的超时时间,单位为s。当超时发生时,kubelet会认为容器已经无法提供服务,将会重启容器。
实现方式如下:
-
ExecAction:在容器内部执行一个命令,如果该命令的返回码为0,则表示容器健康。
apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness-exec spec: containers: - name: liveness image: gcr.io/google_containers/busybox args: - /bin/sh - -c - echo ok > /temp/health; sleep 10; rm -rf /tmp/health; sleep 600 livenessProbe: exec: command: - cat - /tmp/health initialDelaySeconds: 15 timeoutSeconds: 1 -
TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP连接,则表明容器健康
apiVersion: v1 kind: Pod metadata: name: pod-with-healthcheck spec: containers: - name: nginx image: nginx ports: - containerPort: 80 livenessProbe: tcpSocket: port: 80 initialDelaySeconds: 30 timeoutSeconds: 1 -
HTTPGetAction:通过容器的IP地址、端口号及路径调用HTTP Get方法,如果响应的状态码大于等于200且小于400,则认为容器状态健康。
下面例子,kubelet定时发送HTTP请求到localhost:80/_status/healthz来进行容器应用的健康检查
apiVersion: v1 kind: Pod metadata: name: pod-with-healthcheck spec: containers: - name: nginx image: nginx ports: - containerPort: 80 livenessProbe: httpGet: path: /_status/healthz port: 80 initialDelaySeconds: 30 timeoutSeconds: 1
Pod调度
在Kubernetes中,Pod大部分场景下都只是容器的载体,为了完成对一组Pod的调度与自动控制功能。因此,内建了很多controller(控制器),这些相当于一个状态机,用来控制Pod的具体状态和行为。
Deployment/RC–全自动调度
Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义(declarative)方法,用来替代以前的ReplicationController 来方便的管理应用。
使用Deployment来创建ReplicaSet。ReplicaSet在后台创建pod。
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
从调度策略上来说,这3个Nginx Pod由系统全自动完成调度。它们各自最终运行在哪个节点上,完全由Master的Scheduler经过一系列算法计算得出,用户无法干预调度过程和结果。
注意,在创建Deployment时使用–record参数,就可以在CHANGE-CAUSE列看到每个版本的使用命令。
NodeSelector–定向调度
Kubernetes Master上的Scheduler服务(kube-scheduler进程)负责实现Pod的调度,整个调度过程通过执行一系列复杂的算法,最终为每个Pod计算出一个最佳的目标节点,这一过程是自动完成的,通常我们无法知道Pod最终会被调度傲哪个节点上。在实际情况中,也可能需要将Pod调度到指定的Node上,可以通过Node的标签和Pod的nodeSelector属性相匹配,来达到上述目的,前提是Node要先打上标签。如果我们给多个Node都定义了相同的标签,则scheduler将会根据调度算法从这组Node中挑选一个可用的Node进行Pod调度。
注意:如果指定的标签在集群内node上都没有,即使有别的可使用的Node,Pod也会调度失败。
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master
labels:
name: redis-master
spec:
replicas: 1
selector:
name: redis-master
template:
metadata:
labels:
name: redis-master
spec:
containers:
- name: master
image: kubeguid/redis-master
ports:
- containerPort: 6379
nodeSelector:
zone: north
NodeSelector通过标签的方式,简单地实现了限制Pod所在节点的方法。亲和性调度机制则极大地扩展了Pod的调度能力。
NodeAffinity–Node亲和性调度
NodeAffinity意为Node亲和力的调度策略,意于替换NodeSelector的调度策略。
- RequiredDuringSchedulingIgnoredDuringExecution:必须满足指定的规则才可以调度Pod到Node上,与nodeSelector只是语法不通,也相当于硬限制
- PreferredDuringSchedulingIgnoredDuringExecution:强调优先满足指定规则,调度器会尝试调度Pod到Node上,但并不强求,相当于软限制。多个优先级规则还可以设置权重值,以定义执行的先后顺序。
IgnoredDuringExecution表示如果一个Pod所在的节点在Pod运行期间标签发生了变化,不再符合该Pod的节点亲和性需求,则系统将忽略Node上的Label的变化,该Pod能继续在该节点上运行。
下面例子,requiredDuringSchedulingIgnoredDuringExecution要求只运行在amd64的节点上,preferredDuringSchedulingIgnoredDuringExecution尽量运行在“磁盘类型为ssd”的节点上。
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: beta.kubernetes.io/arch
operation: In
values:
- amd64
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disk-type
operation: In
values:
- ssd
containers:
- name: with-node-affinity
image: gcr.io/google_containers/pause:2.0
规则设置
- 如果同时定义了nodeSelector和nodeAffinity,那么必须两个条件都得到满足,Pod才能最终运行在指定的Node上;
- 如果nodeAffinity指定多个nodeSelectorTerms, 那么值需要其中一个能够匹配成功的node即可;
- 如果nodeSelectorTerms中有多个matchExpressions,则一个节点必须满足所有matchExpressions才能运行该Pod。
PodAffinity–Pod亲和与互斥调度策略
从v1.4开始引入
根据节点上正在运行的Pod的标签而不是节点的标签进行判断和调度,要求对节点和Pod两个条件进行匹配。
和节点亲和相同,Pod亲和与互斥的条件设置也是requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoreDuringExecution。Pod亲和性定义于Pod.spec.affinity.podAffinity。Pod间的互斥性则定义于同一层的podAntiAffinity。
apiVersion: v1
kind: Pod
metadata:
name: anti-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operation: In
values:
- S1
topologyKey: failure-domain.beta.kubernetes.io/zone
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operation: In
values:
- nginx
topologyKey: kubernetes.io/hostname
containers:
- name: anti-affinity
image: gcr.io/google_containers/pause:2.0
topologyKey为节点所属的topology范围
- kubernetes.io/hostname
- failure-domain.beta.kubernetes.io/zone
- failure-domain.beta.kubernetes.io/region
Taints和Tolerations
NodeAffinity是Pod上定义的一个属性,使得Pod能够被调度到某些Node上面。Taint则相反,它让node拒绝Pod的运行。Taint和Toleration搭配使用,让Pod避开那些不合适的Node。Toleration是Pod的属性,除非Pod明确声明能够容忍这些Taint,否则无法在有这些Taint的Node上运行。宣告了Toleration,表示这些 pod 可以(但不要求)被调度到具有相应 Taint 的Node上。
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
Toleration规则
- toleration声明中的key和effect需要和Taint设置的保持一致;
- operator的值为Existes,则无须指定value;
- operator的值是Equal并且value相等;
- 空的key配合Existes操作符能够匹配所有的key和value;
- 空的effect匹配所有的effect。
系统允许在同一个Node上设置多个Taint,也可以在Pod上设置多个Toleration。Kubernetes调度器处理多个Taint和Toleration的逻辑顺序为:
首先列出节点中所有的Taint
然后忽略Pod的Tolersation能够匹配的部分,剩下的没有忽略掉的Taint就是对Pod的效果了。
除非下列特殊情况:
- 如果剩余的Taint中存在effect=NoSchedule,则调度器不会把该Pod调度单到这个node上;
- 如果剩余Taint没有NoSchedule效果,但是有PreferNoSchedule效果,则调度器会尝试不把这个Pod指派给这个节点;
- 如果剩余Taint的效果有NoExecute的,并且这个Pod已经在该节点上运行,则会被驱逐;如果没有在该节点上运行,也不会再被调度到该节点上。
例子
$kubectl taint nodes node1 key1=value1:NoSchedule
$kubectl taint nodes node1 key1=value1:NoExecute
$kubectl taint nodes node1 key2=value1:NoSchedule
tolerations:
- key: "key1"
operator: "Equal"
value1: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value1: "value1"
effect: "NoExecute"
该Pod无法被调度到node1上,因为第三个Taint没有匹配的Toleration,如果Pod已经在node1上运行,然后又加上第三个Taint那Pod可以继续在node1上运行。但是,如果加上的Taint的effect是NoExecute,那在该node上没有匹配这个Taint的Pod会马上被驱逐。虽然,会被驱逐,kubernetes有个参数tolerationSeconds,表示Pod可以做哎Taint添加到Node之后还能在这个Node上运行的时间
tolerations:
- key: "key1"
operator: "Equal"
value1: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
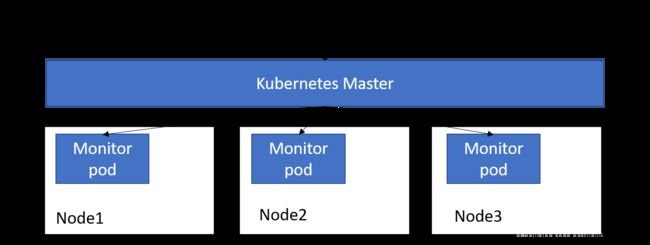
DaemonSet–在每个Node上调度一个Pod
DaemonSet是Kubernetes v1.2新增的一种资源对象。
DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
应用场景:
- 在每个Node上运行一个GlusterFS存储或者Ceph存储Daemon进程;
- 在每个Node上运行一个日志采集程序,例如Fluentd或者Logstach;
- 在每个Node上运行一个性能监控程序,例如Prometheus。
Job–批处理调度
kubernetes v1.2开始加入
Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
CronJob–定时任务
kubernetes v1.5开始加入
apiVersion: batch/v2aplha1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobemplate:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- data; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
Pod扩容和缩容
Kubernetes对Pod的扩容和缩容操作提供了手动和自动两种模式,手动模式通过执行Kubernetes scale命令对一个Deloyment/RC进行Pod副本数量的自动设置,即可一键完成。自动模式则需要用户根据某个性能指标或者自定义业务指标,并制定Pod副本数量的范围,系统将自动在这个范围内根据性能指标的变化进行调整。
手动扩容和缩容模式
$ kubectl scale deployment nginx-deployment --replicas 5
将replicas设置为比当前Pod副本数量更小的数字,系统会自动“杀掉”一些运行中的Pod,以实现缩容
自动扩容和缩容模式
Horizontal Pod Autoscaler(HPA)控制器,用于实现基于CPU使用率进行自动Pod扩容和缩容的功能。HPA控制器基于Master的kube-controller-manager服务启动参数 --hoizaontal-pod-autoscaler-sync-period定义的时长(默认30s),周期性地监测目标Pod的CPU使用率,并在满足条件时对ReplicationController或Deployment中的Pod副本数量进行调整,以符合用户定义的平均Pod CPU使用率。Pod CPU使用率来源于Heapster组件,所以要先装好Heapster。
创建HPA时可以使用kubectl autoscale命令进行快速创建或者使用yaml配置文件进行创建。在创建HPA之前,需要已经存在一个Deployment/RC对象,并且改Deployment/RC中的Pod必须定义resource.requests.cpu的资源请求值,如果不设置该值,则Heapster将无法采集到该Pod的CPU使用情况,会导致HPA无法正常工作。
$ kubectl autoscale deployment php-apache --min=1 --max=10 --cpu-percent=50
在1~10之间调整副本数量,以使得平均Pod CPU使用率维持在50%
Pod升级和回滚
当集群中的某个服务需要升级时,我们需要停止目前与该服务相关的所有Pod,然后下载新版本镜像并创建新的Pod。如果集群规模比较大,则这个工作就变成一个挑战,而且先全部停止然后逐步升级的方式会导致较长时间的服务不可用。Kubernetes提供了滚动升级功能来解决这类问题。
Deployment升级
如果Pod是通过Deployment创建的,则用户可以在运行时修改Deployment的Pod定义或者镜像名称,并应用到Deployment对象上,系统自己就可以完成更新操作。
方式
- Recreate(重建):设置spec.strategy.type=Recreate,表示Deployment正在更新,会先杀掉所有正在运行的 Pod,然后创建新的Pod
- RollingUpdate(滚动更新):设置spec.strategy.type=RollingUpdate,表示Deployment会以滚动更新的方式来逐个更新Pod。同时,通过设置spec.strategy.rollingUpdate下的两个参数maxUnavailable和maxSurge来控制滚动更新的过程。
做法
-
通过kubectl set image命令
$ kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1 -
通过kubectl edit命令修改Deployment的配置
$ kubectl edit deployment/nginx-deployment

保证服务不停
Deployment需要确保在整个更新过程中只有一定数量的Pod可能处于不可用状态,在默认情况下,Deployment确保可用的Pod总数至少为所需的副本的数量减(DESIRED)1,也就是最多1个不可用(maxUnavailable=1)。Deployment还需要确保在整个更新过程中Pod的总数量不会超过所需的副本数太多,在默认情况下,Deployment确保Pod的总数最多比所需的Pod数多1个,也就是最多1个浪涌值(maxSurge=1)。从v1.6开始,maxUnavailable和maxSurge的默认值为副本数量的25%。这样才可以在升级的过程中保证服务不会被中断。
Deployment回滚
-
撤销本次发布并回滚到上一个版本或指定版本
$ kubectl rollout undo deployment/nginx-deployment $ kubectl rollout undo depolyment/nginx-deployment --to-revision=2 -
暂停,然后恢复Deployment
对于一次复杂的Deplyment配置修改,为了避免频繁触发Deployment的更新操作,可以先暂停Deployment的更新操作,然后进行配置修改,再恢复Deployment,一次性触发完整的更新操作,就可以避免不必要的Deployment更新操作。
#暂停Deployment的更新操作 $ kubectl rollout pause deployment/nginx-deployment $ kubectl set image deploy/nginx-deployment nginx-nginx:1.9.1 # 恢复Deployment的操作 $ kubectl rollout resume deploy nginx-deployment
kubectl rolling-update命令
kubectl rolling-update命令创建一个新的RC,然后自动控制旧RC中的Pod副本的数量减少到0,同时新的RC中的Pod副本的数量从0逐步增加到目标值,来完成Pod的升级。
注意:
- 系统要求新的RC需要与旧的RC在相同的命名空间
- RC的名字不能与旧的RC名字相同
- 在selector中应至少一个Label与旧的RC的Label不同,以标识其为新的RC
$ kubectl rolling-update redis-master -f redis-master-controller-v2.yaml
或
# 旧的RC被删除,新的RC仍将使用就的RC的名字
$ kubectl rolling-update redis-master --image=redis-master:2.0
恢复到更新前版本
$ kubectl rolling-update redis-master --image=kubeguid/redis-master:2.0 --rollback
RC的滚动升级不具有Deployment在应用版本升级过程中的历史记录、新旧版本数量的精细控制等功能,RC将逐渐被RS和Deployment所取代。
Downward API(在容器内获取Pod信息)
在某些集群中,集群中的每个节点都需要将自身的标识(ID)及进程绑定的IP地址等信息事先写入配置文件,进程启动时读取这些信息,然后发布到某个类似服务注册中心的地方以实现集群节点的自动发现功能。此时,Downward API就可以派上用场,具体做法如下
环境变量方式–将Pod信息注入为环境变量
通过Downward API将Pod的IP、名称和所在Namespace注入容器和环境变量中
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
images: busybox
command: [ "/bin/sh","-c","env" ]
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
restartPolicy: Never
目前Downward API提供下列变量:
- metadata.name:Pod的名称
- status.podIP:Pod的IP地址
- metadata.namespace:Pod所在的Namespace
环境变量方式–将容器资源信息注入为环境变量
通过Downward API将container的资源请求和限制信息注入容器的环境变量
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod-container-vars
spec:
containers:
- name: test-container
image: busybox
imagePullPolicy: Never
command: [ "sh","-c" ]
args:
- while true; do
echo -en '\n'
printenv MY_CPU_REQUEST MY_CPU_LIMIT;
printenv MY_MEM_REQUEST MY_MEM_LIMIT;
sleep 3600;
done;
resources:
requests:
memory: "32Mi"
cpu: "125m"
limits:
memory: "64Mi"
cpu: "250m"
env:
- name: MY_CPU_REQUEST
valueFrom:
resourceFieldRef:
containerName: test-container
resource: requests.cpu
- name: MY_CPU_LIMIT
valueFrom:
resourceFieldRef:
containerName: test-container
resource: limits.cpu
- name: MY_MEM_REQUEST
valueFrom:
resourceFieldRef:
containerName: test-container
resource: requests.memory
- name: MY_MEM_LIMIT
valueFrom:
resourceFieldRef:
containerName: test-container
resource: limits.memory
restartPolicy: Never
resourceFieldRef可以将容器的资源请求和资源限制等配置设置为容器内容部的环境变量:
- requests.cpu:容器的CPU请求值
- limits.cpu:容器的CPU限制值
- requests.memory:容器的memory请求值
- limits.memory:容器的memory限制值
volume挂载方式
通过Downward API将Pod的Label、Annotation列表通过volume挂载为容器内的一个文件
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod-volume
labels:
zone: us-est-coast
cluster: test-cluster1
rack: rack-22
annotations:
build: two
builder: jack
spec:
containers:
- name: test-container
image: busybox
imagePullPolicy: Never
command: [ "sh","-c" ]
args:
- while true; do
if [[ -e /etc/labels ]]; then
echo -en '\n\n'; cat /etc/labels; fi;
if [[ -e /etc/annotations ]]; then
echo -en '\n\n'; cat /etc/annotations; fi;
sleep 3600;
done
volumeMounts:
- name: podinfo
mountPath: /etc
readOnly: false
volumes:
- name: podinfo
downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "annotations"
fieldRef:
fieldPath: metadata.annotations
通过items的设置,将会以path的名称生成文件。
资料来源:
- 《Kubernetes 权威指南》纪念版
- kubernetes handbook
- Pod定义文件