数据结构之Kruskal算法(并查集的应用)
Kruskal算法基本思想
假设G=(V,E)是连通图,将G中的边按权值从小到大的顺序排列
1、将n个顶点看成n个集合
2、按权值从大到小的顺序选择边,所选边应满足两个顶点不在同一个顶点集合内,即加入此边后不会在生成树中产生回路,将该边放到生成树边的集合中。同时将该边的两个顶点所在的顶点集合合并。
3、重复2,直到所有的顶点都在同一个顶点集合内。
举个例子
1、首先比较图中的所有边的权值,找到最小的权值的边(1,6),加入生成树的边集中,TE={(1,6)}
2、比较图中其余边的权值,找到最小的权值的边(3,5),且加入此边后不会使TE产生回路,TE={(1,6),(3,5)}
3、比较图中其余边的权值,找到最小的权值的边(2,4),且加入此边后不会使TE产生回路,TE={(1,6),(3,5),(2,4)}
4、比较图中其余边的权值,找到最小的权值的边(5,6),且加入此边后不会使TE产生回路,TE={(1,6),(3,5),(2,4),(5,6)}
5、继续上述算法,找到边(1,3),但加入后将会使得TE产生回路,故舍弃。再找另外一条权值最小的边,找到边(3,6),但加入后也会使得TE产生回路,故舍弃继续寻找。找到最小权值边(2,6)满足条件,故将(2,6)加入TE中,此时TE={(1,6),(3,5),(2,4),(5,6),(2,6)}
现在所生成的最小生成树中已经有了n-1条边。此算法完成。
并查集并查集—-百度百科 参考勇幸|Thinking的博客
并查集:(union-find sets)
一种简单的用途广泛的集合. 并查集是若干个不相交集合,能够实现较快的合并和判断元素所在集合的操作,应用很多,如其求无向图的连通分量个数等。最完美的应用当属:实现Kruskar算法求最小生成树。
并查集的精髓(即它的三种操作,结合实现代码模板进行理解):
1、Make_Set(x) 把每一个元素初始化为一个集合
初始化后每一个元素的父亲节点是它本身,每一个元素的祖先节点也是它本身(也可以根据情况而变)。
2、Find_Set(x) 查找一个元素所在的集合
查找一个元素所在的集合,其精髓是找到这个元素所在集合的祖先!这个才是并查集判断和合并的最终依据。判断两个元素是否属于同一集合,只要看他们所在集合的祖先是否相同即可。
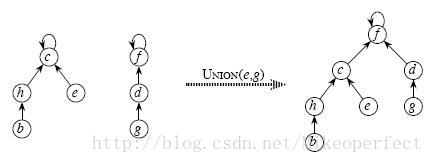
合并两个集合,也是使一个集合的祖先成为另一个集合的祖先,具体见示意图
3、Union(x,y) 合并x,y所在的两个集合
合并两个不相交集合操作很简单:
利用Find_Set找到其中两个集合的祖先,将一个集合的祖先指向另一个集合的祖先。
并查集的优化
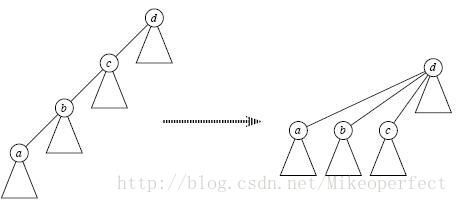
1、Find_Set(x)时 路径压缩
寻找祖先时我们一般采用递归查找,但是当元素很多亦或是整棵树变为一条链时,每次Find_Set(x)都是O(n)的复杂度,有没有办法减小这个复杂度呢?
答案是肯定的,这就是路径压缩,即当我们经过”递推”找到祖先节点后,”回溯”的时候顺便将它的子孙节点都直接指向祖先,这样以后再次Find_Set(x)时复杂度就变成O(1)了,如下图所示;可见,路径压缩方便了以后的查找。
2、Union(x,y)时 按秩合并
即合并的时候将元素少的集合合并到元素多的集合中,这样合并之后树的高度会相对较小。
主要代码
//建立一个新的集合,每一个子节点就是一个数,本身就是他的根节点
void Make_Set(int x)
{
father[x] = x;
R[x] = 0;
}
//通过递归向上查找根节点,回溯时改变当前节点的父节点,直接指向根节点。
int Find_Set(int x)
{
if(x != father[x])
father[x] = Find_set(father[x]);
return father[x];
}
//将根节点设置为-1的非递归方法
int Find_Set2(int x)
{
int y = x;
while(y!= -1)
y = father[y];
return y;
}
//两个集合的合并算法
void Union(int x, int y)
{
int GrandX = Find_set(x);
int GrandY = Find_set(y);
if(GrandX == GrandY)
return;
if(R[GrandX] < R[GrandY])
father[GrandX] = GrandY;
else
{
if(R[GrandX] == R[GrandY])
R[GrandX]++;
father[GrandY] = GrandX;
}
}kruskal算法完整版代码
#includeset,edgeset[i].bv);
v2=seeks(set,edgeset[i].ev);
if(v1!=v2)
{
printf("(%d,%d)%d\n",edgeset[i].bv,edgeset[i].ev,edgeset[i].w);
set[v1]=v2;
}
i++;
}
}
int main()
{
int i,arcnum;
arcnum=createdgeset();
sort(arcnum);
printf("the arcnum from little to big:");
printf("\nbv ev w\n");
for(i=1;i<=arcnum;i++)
printf("%d %d %d\n",edgeset[i].bv,edgeset[i].ev,edgeset[i].w);
kruskal(arcnum);
return 0;
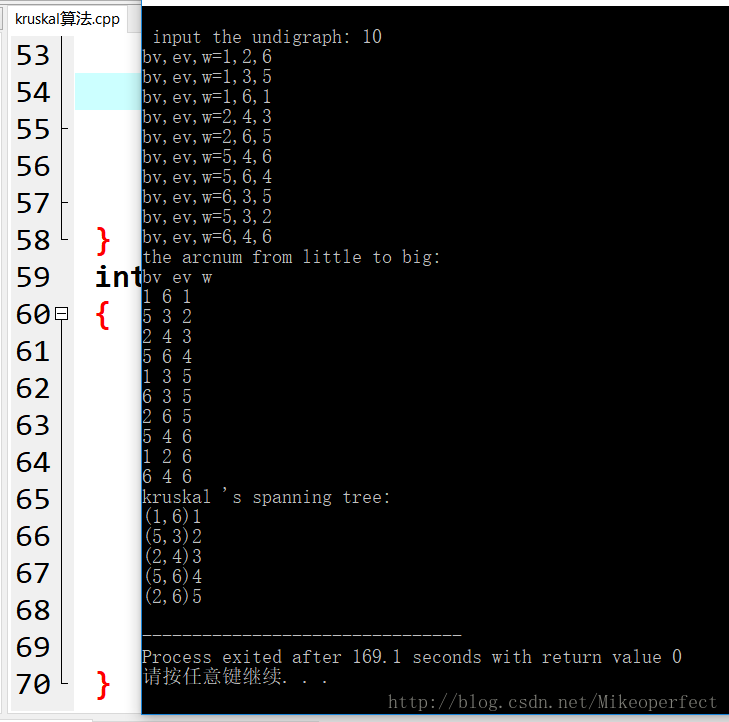
} 运行截图
总结
kruskal算法相比于prim算法而言,要简单不少,prim算法多适用于顶点多的稠密图,而kruskal算法多适用于边数多的稀疏图。kruskal算法其精髓在于运用了并查集的概念,并查集是一个好东西,有时间要好好研究一下它的应用