Hbase 学习笔记
HBASE由Google的Bigtable设计而来的面向列族的存储的非关系数据库,主要偏向适合数据分析。
优点和缺点
列式数据库优点,列式数据库会把相同列的数据都放在一块即列为单位存储。当我们查询某一列的时候只需要调出相应的块即可,这样还可以减少很多I/O。
高压缩比
如果数据元素间的相似性很高的话可以进行大幅度的压缩,相似度越高压缩比越大。即节约了空间又减少了I/O,从而提高性能。
高并发,极易扩展
Hbase的极易扩展主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,通过横向添加RegionSever的机器,提升Hbase上层的处理能力。
一个是基于存储的扩展(HDFS),通过添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
稀疏性
稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
半结构化或非结构化数据:
对于数据结构字段不够确定或杂乱无章非常难按一个概念去进行抽取的数据适合用HBase,因为HBase支持动态添加列。
多版本号数据:
依据Row key和Column key定位到的Value能够有随意数量的版本号值,因此对于须要存储变动历史记录的数据,用HBase是很方便的。比方某个用户的Address变更,用户的Address变更记录也许也是具有研究意义的。
业务场景简单:
不需要太多的关系型数据库特性,列入交叉列,交叉表,事务,连接等。
Hbase的缺点:
单一RowKey固有的局限性决定了它不可能有效地支持多条件查询
不适合于大范围扫描查询
不直接支持 SQL 的语句查询
HBASE整个架构图
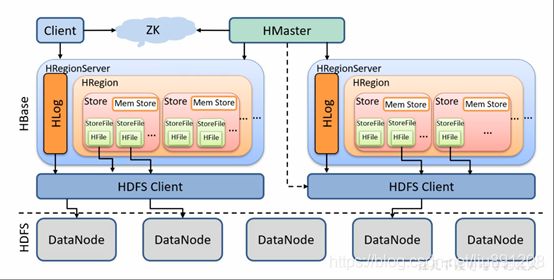
HMaster负责对region分配到具体的Region server,并监控Region server状态(差分合并),数据库表DDL(元数据操作)操作,维护整个集群的负载均衡。
Zookeeper的作用是HBase系统中的分布式协调服务,协调内容是选举Master。在HBase中,Zookeeper的另外一个功能是通过心跳维护分布式Session,记录各个Region server的在线状态。
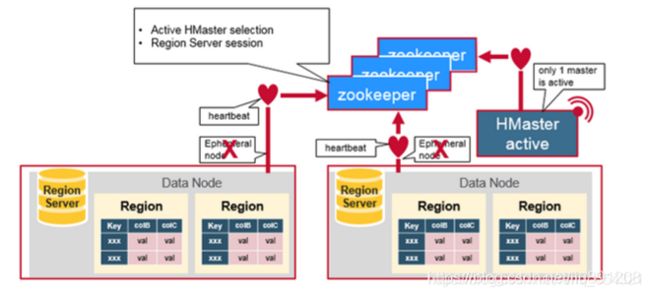
此外,Zookeeper还记录了META表的路由信息。
Region Server合并差分region ,对数据dml进行增删改查,Region server直接对接用户的读写请求,是真正的“干活”的节点。运行在HDFS DataNode上的Region server包含如下几个部分:
- WAL 预写日志:既Write Ahead Log。WAL是HDFS分布式文件系统中的一个文件。WAL用来存储尚未写入永久性存储区中的新数据。WAL也用来在服务器发生故障时进行数据恢复。
- MemStore写缓存:其中存储了从WAL中写入但尚未写入硬盘的数据。数据持久化存储之前,首先会写入内存, 进行排序操作,内存中数据量达到一定规模后会批量写入磁盘。每一个region中的每一个column family对应一个MemStore。
- Block Cache 读缓存: 在内存中存储频繁读取的数据,当读缓存满时,使用"最近最少使用(LRU)算法"替换数据。
- Hfiles数据文件,以有序KeyValue的格式持久化存储数据。同一行不同列的数据会分别存储多个KeyValue,每个KeyValue里都包含rowkey数据,因此rowkey的长度应该尽量短。
写操作
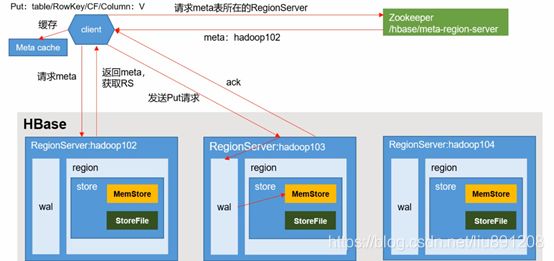

注意:META table中保存了集群region的地址信息,记录了当前要查的表由哪些Region server服务,哪些region存在哪Region server,同时META table也是存在指定的Region server里,这个位置信息由ZooKeeper中会保存。
META table的结构如下:
键:region的起始键,region id。
值:Region server
数据到Region server 后,后面的就由Region server服务。
1)将数据写入到WAL,写入WAL后客户端即收到ACK响应。
2)WAL数据会写入到MemStore中
3)当MemStore积累了足够的数据,整个MemStore中的数据集会一次性Flush写入HFile。由于MemStore中的KeyValues是有序的,Flush写入过程是磁盘顺序写入,因此Flush速度很快。注:在FlusH的时候,在同一个FlusH(同一个内存中)里面不会保留过期的版本(小事件搓的被覆盖的)数据,会把被覆盖的数据删除掉,然后再把数据FlusH到HFILE里。删除标记会保留。
4)这样频繁的Flush会形成很多小的HFile,当积累到一定层度执行Compaction(合并)来合并小的HFile,将对应于某一个Column family的所有HFile重新整理并合并为一个HFile,并在这一过程中删除已经删除或过期的cell,更新现有cell的值。
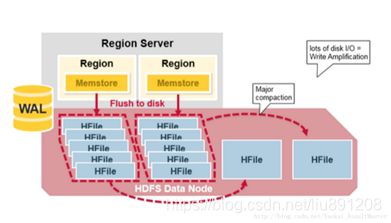
小合并会保留过期的版本(小事件搓的被覆盖的)数据
大合并不会保留过期的版本(小事件搓的被覆盖的)数据,会把被覆盖的数据删除掉,不会保留删除标记
读操作
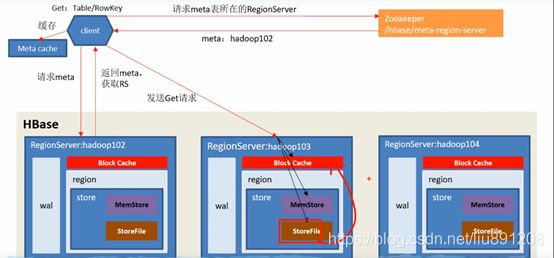
到达Region server 后
首先,扫描器查找读缓存BlockCache,当需要内存时,使用LRU算法替换最近最少使用的缓存
然后,扫描器查找写缓存MemStore,写缓存包含着最近的写入数据
最后,如果扫描器没有在BlockCache和MemStore中找到该行数据的全部KeyValues,那么扫描器会使用BlockCache索引和布隆过滤器把HFile加载到内存,查找制定行的数据。
布隆过滤器(Bloom Filter)的使用
HBase的Get/Scan操作流程,是通过BloomFilter进行过滤,减少不必要的stroreFile读取。

BloomFilter是一个列族级别的配置属性,如果在表中设置了BloomFilter,那么HBase会在生成StoreFile时,包含一份BloomFilter结构的数据,称其为MetaBlock;MetaBlock与DataBlock(真实的KeyValue数据)一起由LRUBlockCache维护,所以开启BloomFilter会有一定的存储及内存cache开销。
HBase中的Bloomfilter的类型包括:
ROW:根据KeyValue中的row来过滤storefile。
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r3 cf:q1 v)、kv4(r4 cf:q1 v)
如果设置了CF属性中的bloomfilter为ROW,那么get(r1)时就会过滤sf1,get(r3)就会过滤sf2
ROWCOL:根据KeyValue中的row+qualifier来过滤storefile。
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r1 cf:q2 v)、kv4(r2 cf:q2 v)
如果设置了CF属性中的bloomfilter为ROW,
无论get(r1,q1)还是get(r1,q2),都会读取sf1+sf2;
而如果设置了CF属性中的bloomfilter为ROWCOL,那么get(r1,q1)就会过滤sf2,get(r1,q2)就会过滤sf1