Spark初识入门Core (一)
Spark初识入门core (一)
标签(空格分隔): Spark的部分
- 一:spark 简介
- 二:spark 的安装与配置
- 三:spark 的wordcount
- 四:spark 处理数据
- 五:spark 的Application
- 六: spark 日志清洗
- 七:回顾
一:spark 简介
1.1 spark 的来源
Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。1.2 spark 的生态环境
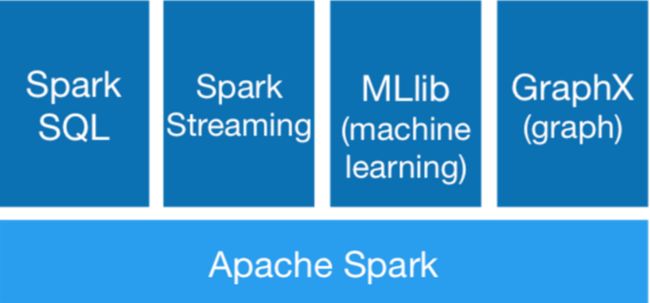
1.3 spark 与hadoop的 mapreduce 对比
MapReduce
Hive Storm Mahout Griph
Spark Core
Spark SQL Spark Streaming Spark ML Spark GraphX Spark R1.4 spark 可以运行在什么地方
Spark Application运行everywhere
local、yarn、memsos、standalon、ec2 .....
二 spark的安装与配置
2.1 配置好hadoop的环境安装scala-2.10.4.tgz
tar -zxvf scala-2.10.4.tgz /opt/modules
vim /etc/profile
export JAVA_HOME=/opt/modules/jdk1.7.0_67
export HADOOP_HOME=/opt/modules/hadoop-2.5.0-cdh5.3.6
export SCALA_HOME=/opt/modules/scala-2.10.4
export SPARK_HOME=/opt/modules/spark-1.6.1-bin-2.5.0-cdh5.3.6
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin2.2 安装 spark-1.6.1-bin-2.5.0-cdh5.3.6.tgz
tar -zxvf spark-1.6.1-bin-2.5.0-cdh5.3.6.tgz
mv spark-1.6.1-bin-2.5.0-cdh5.3.6 /opt/modules
cd /opt/modules/spark-1.6.1-bin-2.5.0-cdh5.3.6/conf
cp -p spark-env.sh.template spark-env.sh
cp -p log4j.properties.template log4j.properties
vim spark-env.sh
增加:
JAVA_HOME=/opt/modules/jdk1.7.0_67
SCALA_HOME=/opt/modules/scala-2.10.4
HADOOP_CONF_DIR=/opt/modules/hadoop-2.5.0-cdh5.3.6/etc/hadoop

2.3 spark 命令执行与调用
执行spark 命令
bin/spark-shell 
2.4 运行测试文件:
hdfs dfs -mkdir /input
hdfs dfs -put READ.md /input
2.4.1 执行统计
scala> val rdd = sc.textFile("/input/README.md")
rdd.count (统计多少行)
rdd.first (统计第一行)
rdd.filter(line => line.contains("Spark")).count (统计存在Spark的字符的有多少行)


scala> rdd.map(line => line.split(" ").size).reduce(_ + _)
三: spark 的wordcount统计
3.1 spark 的wc统计
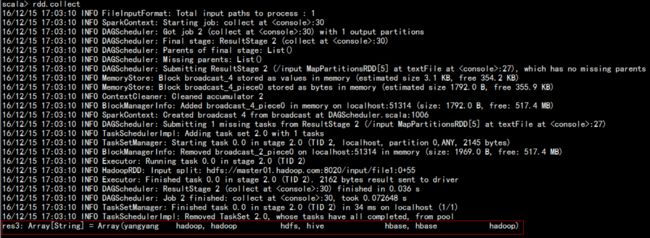
val rdd=sc.textFile("/input") ####rdd 读文件
rdd.collect ###rdd 显示文件的内容
rdd.count ####rdd 显示有多少行数据
3.2 spark 处理数据三步骤
input
scala> val rdd =sc.textFile("/input") ####(输入数据)
process
val WordCountRDD = rdd.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(( a , b ) => ( a + b )) ######(处理数据)
简写:
val WordCountRDD = rdd.flatMap(_.split(" ")).map(_,1)).reduceByKey(_ + _)
output
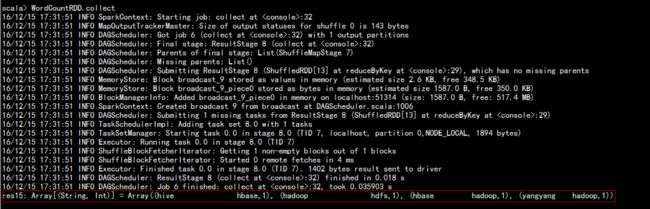
scala> WordCountRDD.saveAsTextFile("/output3")
scala> WordCountRDD.collect

![]()


四、spark 处理数据:
4.1 spark的数据统计
spark 处理pageview 数据:
hdfs dfs -mkdir /page
hdfs dfs -put page_views.data /page
读取数据:
val rdd = sc.textFile("/page")
处理数据:
val PageRdd = rdd.map(line => line.split("\t")).map(arr => (arr(2), 1)).reduceByKey(_ + _)
取数据的前十条数据:
PageRdd.take(10);




将数据放入内存:
rdd.cache
rdd.count
rdd.map(line => line.split("\t")).map(arr => (arr(2), 1)).reduceByKey(_ + _).take(10)


![]()
五:spark 的Application
5.1 spark 的运行模式
spark 的application
-1. Yarn 目前最多
-2. standalone
自身分布式资源管理管理和任务调度
-3 Mesos
hadoop 2.x release 2.2.0 2013/10/15
hadoop 2.0.x - al
cloudera 2.1.x -bete
cdh3.x - 0.20.2
cdh4.x - 2.0.0
hdfs -> HA: QJM : Federation
Cloudera Manager 4.x
cdh5.x
5.2 spark 的 Standalone mode
Spark 本身知道的一个分布式资源管理系列以及任务调度框架
类似于 Yarn 这样的框架
分布式
主节点
Master - ResourceManager
从节点:
work -> nodemanager
打开 spark-env.sh
最后增加:
SPARK_MASTER_IP=192.168.3.1
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=2
SPARK_WORKER_MEMORY=2g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081
SPARK_WORKER_INSTANCES=1 ## 每台机器可以运行几个work
cd /soft/spark/conf
cp -p slaves.template slaves
echo "flyfish01.yangyang.com" > slaves
------
启动spark
cd /soft/spark/sbin
start-slaves.sh
启动所有的从节点,也就是work节点
注意: 使用此命名,运行此命令机器,必须要配置与主节点的无密钥登录,否则启动时时候会出现一些问题,比如说输入密码之类的。
./start-master.sh
./start-slaves.sh


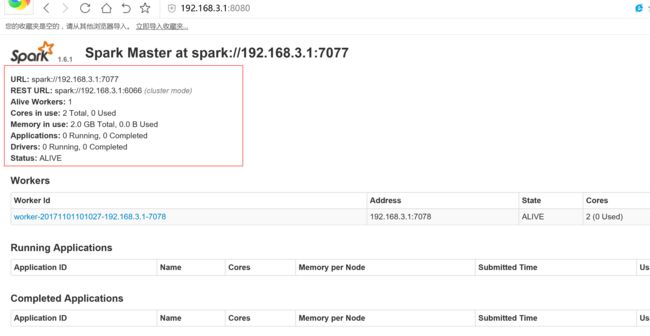
job 运行在standalone 上面
bin/spark-shell --master spark://192.168.3.1:7077
5.3 standalone 上面运行
读取数据:
val rdd = sc.textFile("/page")
处理数据:
val PageRdd = rdd.map(line => line.split("\t")).map(arr => (arr(2), 1)).reduceByKey(_ + _)
取数据的前十条数据:
PageRdd.take(10);

![]()

![]()




5.4 对于一个spark application 两个部分组成
- 1、 Driver program -> 4040 4041 4042
main 方法
SparkContext -- 最最重要
- 2、Executor 资源
一个 jvm (进程)
运行我们的job的task
REPL: shell 交互式命令
spark Application
job -01
count
job -02
stage-01
task-01 (线程) -> map task (进程)
task-02 (线程) -> map task (进程)
每个stage 中的所有的task,业务都是相同的,处理的数据不同
stage -02
job -03
从上述运行的程序来看:
如果RDD 调用的函数,返回值不是RDD的时候,就会触发一个job 进行执行
思考:
reduceByKey 到底做了什么事情:
-1. 分组
将相同的key 的value 进行合并
-2.对value 进行reduce
进行合并
经分析,对比mapreduce 中的worldcount 程序运行,推断出spark job 中 stage 的划分依据RDD 之间否产生shuffle 进行划分

倒序查询:
val rdd = sc.textFile("/input")
val WordContRdd = rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
val sortRdd = WordContRdd.map(tuple => (tuple._2, tuple._1)).sortByKey(false)
sortRdd.collect
sortRdd.take(3)
sortRdd.take(3).map(tuple => (tuple._2, tuple._1))






scala 的隐式转换:
隐式转换:
将某个类型转换为另外一个类型。
隐式函数
implicit def5.5 在企业中开发spark的任务
如何开发spark application
spark-shell + idea
-1, 在idea 中编写代码
-2,在spark-shell 中执行代码
-3. 使用IDEA 将代码打包成jar包,使用bin/spark-submint 提交运行5.6 spark 在Linux下面的idea 编程 10万条数据取前10条
package com.ibeifeng.bigdata.senior.core
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* Created by root on 17-11-2.
*
* Driver Program
*
*/
object SparkApp {
def main(args: Array[String]) {
// step0: sSparkContext
val sparkConf = new SparkConf()
.setAppName("SparkApplication")
.setMaster("local[2]")
// create SparkContext
val sc = new SparkContext(sparkConf)
//**=========================================*/
//step 1: input data
val rdd = sc.textFile("/page/page_views.data")
//step 2: process data
val pageWordRddTop10 = rdd
.map(line => line.split("\t"))
.map(x => (x(2),1))
.reduceByKey(_ + _)
.map(tuple => (tuple. _2, tuple._1))
.sortByKey(false)
.take(10)
//Step 3 : output data
pageWordRddTop10.foreach(println(_))
//**=========================================*/
//close spark
sc.stop()
}
}

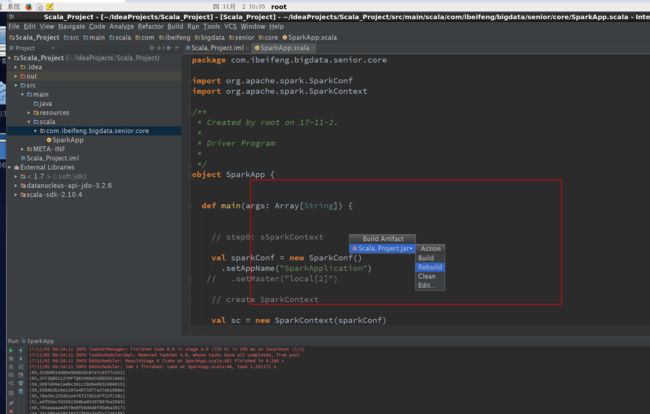
5.7 将代码打包成一个jar包运行




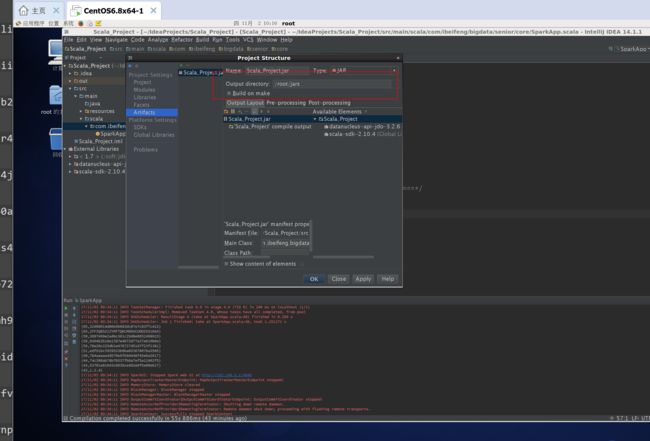
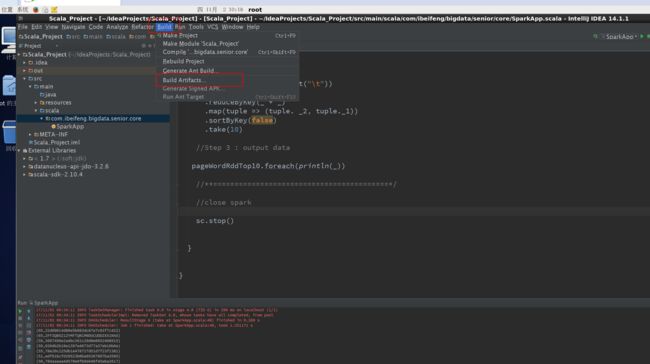


5.8 spark 提交任务
5.8.1 运行在local
bin/spark-submint Scala_Project.jar
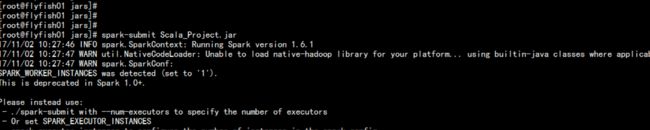
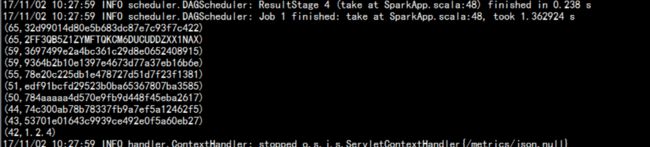
5.8.2 运行在standalone


启动spark 的standalone
bin/start-master.sh
bin/start-slave2.sh
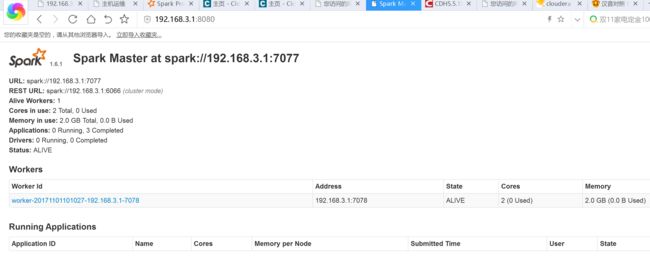
bin/spark-submit --master spark://192.168.3.1:7077 Scala_Project.jar
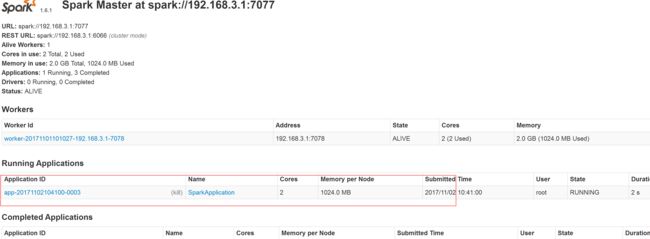

5.7 spark 的historyserver配置
spark 监控运行完成的spark application
分为两个部分:
第一: 设置sparkApplication 在运行时,需要记录日志信息
第二: 启动historyserver 通过界面查看
------
配置historyserver
cd /soft/spark/conf
cp -p spark-defaults.conf.template spark-defaults.conf
vim defaults.conf
spark.master spark://192.168.3.1:7077
spark.eventLog.enabled true
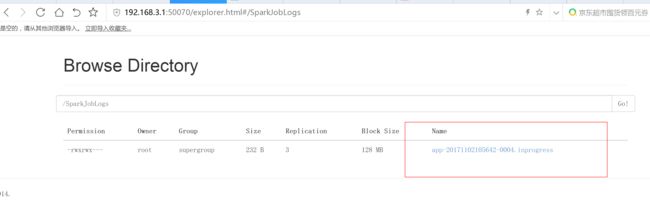
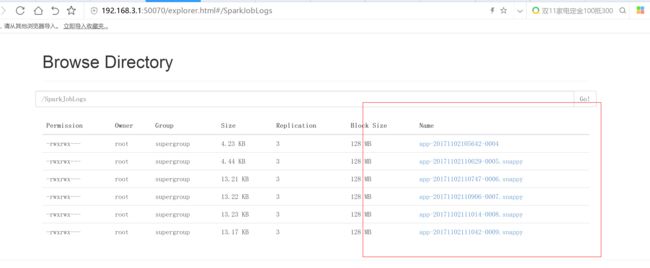
spark.eventLog.dir hdfs://192.168.3.1:8020/SparkJobLogs
spark.eventLog.compress true
启动spark-shell
bin/spark-shell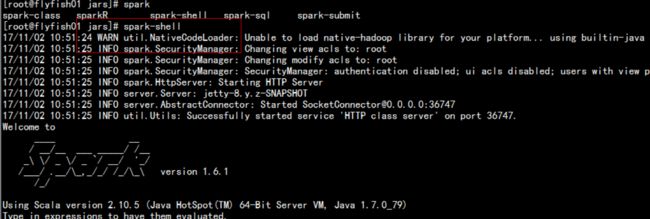

bin/spark-submit --master spark://192.168.3.1:7077 Scala_Project.jar



配置spark的服务端historyserver
vim spark-env.sh
SPARK_MASTER_IP=192.168.3.1
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=2
SPARK_WORKER_MEMORY=2g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081
SPARK_WORKER_INSTANCES=1 ## 每台机器可以运行几个work
----
#增加
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://flyfish01.yangyang.com:8020/SparkJobLogs -Dspark.history.fs.cleaner.enabled=true"
-------------
#启动historyserver
cd /soft/spark
sbin/start-history-server.sh



六: spark 的日志分析
需求一:
The average, min, and max content size of responses returned from the server.
ContentSize
需求二:
A count of response code's returned.
responseCode
需求三:
All IPAddresses that have accessed this server more than N times.
ipAddresses
需求四:
The top endpoints requested by count.
endPoint6.1 maven 创建工程:
6.1.1 使用命令行创建
mvn archetype:generate -DarchetypeGroupId=org.scala-tools.archetypes -DarchetypeArtifactId=scala-archetype-simple -DremoteRepositories=http://scala-tools.org/repo-releases -DgroupId=com.ibeifeng.bigdata.spark.app -DartifactId=log-analyzer -Dversion=1.0
6.1.2 导入工程




6.1.3 pom.xml 文件:
4.0.0
com.ibeifeng.bigdata.spark.app
log-analyzer
1.0
${project.artifactId}
My wonderfull scala app
2010
UTF-8
2.5.0
1.6.1
org.apache.hadoop
hadoop-client
${hadoop.version}
compile
org.apache.spark
spark-core_2.10
${spark.version}
compile
junit
junit
4.8.1
test
src/main/scala
src/test/scala
org.scala-tools
maven-scala-plugin
2.15.0
compile
testCompile
-make:transitive
-dependencyfile
${project.build.directory}/.scala_dependencies
org.apache.maven.plugins
maven-surefire-plugin
2.6
false
true
**/*Test.*
**/*Suite.*
6.1.4 增加scala的jar包

6.1.5 创建LogAnalyzer.scala
package com.ibeifeng.bigdata.spark.app.core
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by zhangyy on 2016/7/16.
*/
object LogAnalyzer {
def main(args: Array[String]) {
// step 0: SparkContext
val sparkConf = new SparkConf()
.setAppName("LogAnalyzer Applicaiton") // name
.setMaster("local[2]") // --master local[2] | spark://xx:7077 | yarn
// Create SparkContext
val sc = new SparkContext(sparkConf)
/** ================================================================== */
val logFile = "/logs/apache.access.log"
// step 1: input data
val accessLogs = sc.textFile(logFile)
/**
* parse log
*/
.map(line => ApacheAccessLog.parseLogLine(line))
/**
* The average, min, and max content size of responses returned from the server.
*/
val contentSizes = accessLogs.map(log => log.contentSize)
// compute
val avgContentSize = contentSizes.reduce(_ + _) / contentSizes.count()
val minContentSize = contentSizes.min()
val maxContentSize = contentSizes.max()
// println
printf("Content Size Avg: %s , Min : %s , Max: %s".format(
avgContentSize, minContentSize, maxContentSize
))
/**
* A count of response code's returned
*/
val responseCodeToCount = accessLogs
.map(log => (log.responseCode, 1))
.reduceByKey(_ + _)
.take(3)
println(
s"""Response Code Count: ${responseCodeToCount.mkString(", ")}"""
)
/**
* All IPAddresses that have accessed this server more than N times
*/
val ipAddresses = accessLogs
.map(log => (log.ipAddress, 1))
.reduceByKey( _ + _)
// .filter( x => (x._2 > 10))
.take(5)
println(
s"""IP Address : ${ipAddresses.mkString("< ", ", " ," >")}"""
)
/**
* The top endpoints requested by count
*/
val topEndpoints = accessLogs
.map(log => (log.endPoint, 1))
.reduceByKey(_ + _)
.map(tuple => (tuple._2, tuple._1))
.sortByKey(false)
.take(3)
.map(tuple => (tuple._2, tuple._1))
println(
s"""Top Endpoints : ${topEndpoints.mkString("[", ", ", " ]")}"""
)
/** ================================================================== */
// Stop SparkContext
sc.stop()
}
}
6.1.5 创建匹配日志匹配文件:
package com.ibeifeng.bigdata.spark.app.core
/**
* Created by zhangyy on 2016/7/16.
*
* 1.1.1.1 - - [21/Jul/2014:10:00:00 -0800]
* "GET /chapter1/java/src/main/java/com/databricks/apps/logs/LogAnalyzer.java HTTP/1.1"
* 200 1234
*/
case class ApacheAccessLog (
ipAddress: String,
clientIndentd: String,
userId: String,
dateTime:String,
method: String,
endPoint: String,
protocol: String,
responseCode: Int,
contentSize: Long)
object ApacheAccessLog{
// regex
// 1.1.1.1 - - [21/Jul/2014:10:00:00 -0800] "GET /chapter1/java/src/main/java/com/databricks/apps/logs/LogAnalyzer.java HTTP/1.1" 200 1234
val PARTTERN ="""^(\S+) (\S+) (\S+) \[([\w:/]+\s[+\-]\d{4})\] "(\S+) (\S+) (\S+)" (\d{3}) (\d+)""".r
/**
*
* @param log
* @return
*/
def parseLogLine(log: String): ApacheAccessLog ={
// parse log
val res = PARTTERN.findFirstMatchIn(log)
// invalidate
if(res.isEmpty){
throw new RuntimeException("Cannot parse log line: " + log)
}
// get value
val m = res.get
// return
ApacheAccessLog( //
m.group(1), //
m.group(2),
m.group(3),
m.group(4),
m.group(5),
m.group(6),
m.group(7),
m.group(8).toInt,
m.group(9).toLong)
}
}6.1.6 报错
Exception in thread "main" java.lang.SecurityException: class "javax.servlet.FilterRegistration"'s signer information does not match signer information of other classes in the same package
at java.lang.ClassLoader.checkCerts(ClassLoader.java:952)
at java.lang.ClassLoader.preDefineClass(ClassLoader.java:666)
at java.lang.ClassLoader.defineClass(ClassLoader.java:794)
-----
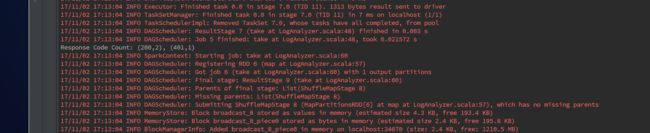
删掉 javax.servlet-xxxx.api 的maven依赖包6.1.7 输出:



七:回顾
回顾:
-1,了解认识Spark
MapReduce比较
“四大优势”
--1,速度快
--2,使用简单
--3,一栈式
--4,无处不在的运行
开发测试
SCALA: REPL/Python
-2,Spark Core
两大抽象概念
--1,RDD
集合,存储不同类型的数据 - List
---1,内存
memory
---2,分区
hdfs: block
---3,对每个分区上数据进行操作
function
--2,共享变量shared variables
---1,广播变量
---2,累加器
计数器
-3,环境与开发
--1,Local Mode
spark-shell
--2,Spark Standalone
配置
启动
监控
使用
--3,HistoryServer
-1,针对每个应用是否记录eventlog
-2,HistoryServer进行展示
--4,如何使用IDE开发Spark Application
-1,SCALA PROJECt
如何添加Spark JAR包
-2,MAVEN PROJECT
=================================================
Spark 开发
step 1:
input data -> rdd/dataframe
step 2:
process data -> rdd##xx() / df#xx | "select xx, * from xx ..."
step 3:
output data -> rdd.saveXxxx / df.write.jdbc/json/xxx转载于:https://blog.51cto.com/flyfish225/2113453