kafka入门--操作kafka基本命令以及JavaAPI
Kafka常用操作命令
- 查看当前服务器中的所有topic
// shell命令最后的参数为zookeeper的集群的主机名和对应的端口号,该命令会列出kafka集群内所有消息的topic
/export/servers/kafka/bin/kafka-topics.sh --list --zookeeper mini1:2181
- 创建topic
//其中 replication-factor 参数用于设置该topic的备份数量,partitions 参数用于设置该topic的分区数
// 最后参数"orderMq" 表示该消息的名称
/export/servers/kafka/bin/kafka-topics.sh --create --zookeeper mini1:2181 --replication-factor 2 --partitions 4 --topic orderMq
- 删除topic
- 需要server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启。
// 删除 test topic
/export/servers/kafka/bin/kafka-topics.sh --delete --zookeeper mini1:2181 --topic test
- 通过shell命令发送消息
/export/servers/kafka/bin/kafka-console-producer.sh --broker-list mini1:9092 --topic orderMq
- 通过shell消费消息
/export/servers/kafka/bin/kafka-console-consumer.sh --zookeeper mini1:2181 --from-beginning --topic orderMq
Kafka生产者API
public class KafkaProducerSimple {
public static void main(String[] args) {
/**
* 1、指定当前的Kafka Producer生产的数据的目的地
*/
String TOPIC = "orderMq";
//读取配置文件
Properties props = new Properties();
//key.serializer.class 默认为serializer.class
props.put("serializer.class","kafka.serializer.StringEncoder");
props.put("metadata.broker.list","mini1:9092,mini2:9092,mini3:9092");
/**
* request.required.acks 设置发送数据是否需要服务端的反馈,有三个值0,1,-1
* 0 意味着producer永远不会等待一个来自broker的ack,这就是0.7版本的行为。
* 该选项提供了最低的延迟,但是持久化的保证是最弱的,当server挂掉的时候会丢失一些数据
* 1 意味着在leader replica已经接收到数据后,producer会得到一个ack.
* 该选项提供了更好的持久性,因为在server确认请求成功处理后,client才会返回
* -1 意味着在所有的ISR都接收到数据后,producer才会得到一个ack.
* 这个选项提供了最好的持久性,只要还有一个replica存活,数据就不会丢失。
*/
props.put("request.required.acks","1");
//可选配置用来把消息分到各个partition中,默认是kafka.producer.DefaultPartioner,即对key进行hash
props.put("partitioner.class","cn.mylove.storm.kafka.MyLogPartitioner");
//通过配置文件创建生产者
Producer producer = new Producer(new ProducerConfig(props));
//通过for循环生产数据
for(int messageNo = 1 ; messageNo < 100000 ; messageNo ++ ){
String messageStr = new String(messageNo +"\n"+"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据"+"\n"+
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据"+"\n"+
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据"+"\n"+
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据"+"\n"+
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据"+"\n"+
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据"+"\n"+
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据"+"\n"+
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据"+"\n"+
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据"+"\n");
//调用API发送数据,需要指定partitionKey,用来配合自定义的Partitioner进行数据分发
producer.send(new KeyedMessage(TOPIC,messageNo + "","appid" + UUID.randomUUID() + messageStr));
}
}
kafka消费者API
public class KafkaConsumerSimple implements Runnable{
public String title;
public KafkaStream stream;
public KafkaConsumerSimple(String title , KafkaStream stream){
this.title = title;
this.stream = stream;
}
public void run(){
System.out.println("开始运行 "+ title );
ConsumerIterator iterator = stream.iterator();
//不停地从stream中读取到新来的消息,在等待新的消息时hasNext()会阻塞
//如果调用ConsumerConnector#shutdown 那么hasNext会返回false
while(iterator.hasNext()){
MessageAndMetadata data = iterator.next();
String topic = (String) data.topic();
int partition = data.partition();
long offset = data.offset();
String msg = new String(data.message());
System.out.println(String.format(
"Consumer:[%s],Topic:[%s], PartitionId: [%d],offset: [%d],msg: [%s]",
title,topic,partition,offset,msg
));
}
System.out.println(String.format("Consumer: [%s] existing ... ",title));
}
public static void main(String[] args) {
Properties props = new Properties();
props.put("group.id","dashujujiagoushi");
props.put("zookeeper.connect","mini1:2181,mini2:2181,mini3:2181");
props.put("auto.offset.reset","largest");
props.put("auto.commit.interval.ms","1000");
props.put("partition.assignment.strategy","roundrobin");
ConsumerConfig config = new ConsumerConfig(props);
String topic1 = "orderMq";
//只要ConsumerConnector还在的话,consumer会一直等待新的消息,不会自己退出
ConsumerConnector consumerConnector = Consumer.createJavaConsumerConnector(config);
//定义一个map
Map topicCountMap = new HashMap<>();
//创建orderMq设置partition为4,该处map的key为topic,value为返回的KafkaStream的个数
topicCountMap.put(topic1,4);
//Map>>中String是topic,ListKafkaStream是对应的流
Map>> topicStreamMap = consumerConnector.createMessageStreams(topicCountMap);
//取出 topic对应的stream
List> streams = topicStreamMap.get(topic1);
//创建一个容量为4的线程池
ExecutorService executor = Executors.newFixedThreadPool(4);
//创建consumer threads
for (int i = 0; i < streams.size() ; i++) {
executor.execute(new KafkaConsumerSimple("消费者" + ( i+1 ),streams.get(i)));
}
}
}
自定义的分区类
public class MyLogPartitioner implements Partitioner{
private static Logger logger = Logger.getLogger(MyLogPartitioner.class);
public MyLogPartitioner(VerifiableProperties properties) {
}
public int partition(Object obj,int numPartitions){
return Integer.parseInt(obj.toString())%numPartitions;
//return 1;
}
}
分别启动生产者和消费者
- Kafka producer开始发送数据,consumer接收到数据

关于Kafka中Partition
-
Partition表示kafka消息的分区,落到磁盘上是一个partition的目录。partition的目录中有多个segment组合(index,log)。如在kafka集群的mini3机器的/export/servers/logs/kafka路径下存放topic为orderMq的0号以及2号分区(创建orderMq时分区设置为4)。

-
一个Topic对应多个partition[0,1,2,3…],一个partition对应多个segment组合。一个segment有默认的大小是1G。mini3机器orderMq的0号分区内容如下,其中.index为索引文件.log存放消息的内容,当l文件大小超过1G后,会生成另外一对index和log文件。

-
每个partition可以设置多个副本(replication-factor 1),会从所有的副本中选取一个leader出来。所有读写操作都是通过leader来进行的。
-
Kafka生产数据时的分组策略
- 分析Kafka源码可知默认的分组策略为 Utils.abs(key.hashCode) % numPartitions ,而其中的key为producer在发送数据时传入的
produer.send(KeyedMessage(topic,myPartitionKey,messageContent))
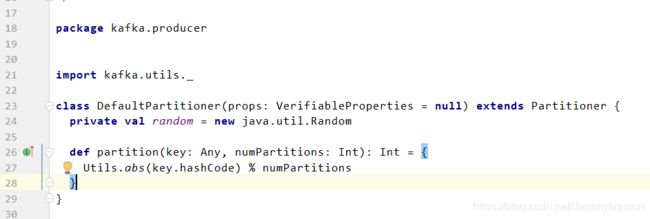
- 分析Kafka源码可知默认的分组策略为 Utils.abs(key.hashCode) % numPartitions ,而其中的key为producer在发送数据时传入的