如何使用redis进行排序操作
1,有序集合(天然的排序数据结构)
数据初始化插入
#!/usr/bin/python
# -*- coding: utf-8 -*-
import redis
import random
if __name__ == '__main__':
conn = redis.StrictRedis(host="localhost", port=6379)
pipe_line = conn.pipeline()
for i in range(100000):
pipe_line.zadd("user", i, "".join(random.sample('zyxwvutsrqponmlkjihgfedcba', 10)))
pipe_line.execute()
常用查询:
1,插入 ZADD key score name, 例如 ZADD user 1000 zhangsan
2,统计 ZCARD key 或者 ZCOUNT key min max,例如ZCOUNT user 0 1000
3,做增量 ZINCRBY key incr name,例如ZINCRBY user 111 zhangsan
4,查询成员 ZRANGE key start stop [WITHSCORES],例如ZRANGE user 0 1000 ,当然还有其他规则的range查询
5,其他查询ZSCORE ZRANK,ZREM,ZSCAN等其他操作。
redis的有序集合内部实现是通过hash和skiplist两种设计实现。跳表大概长这样
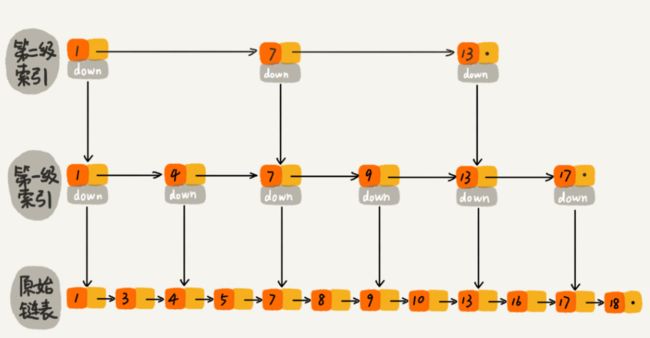
这也会为了排序和查找性能做的优化。所以如上可知:
添加和删除都需要修改skiplist,所以复杂度为O(log(n))。
但是如果仅仅是查找元素的话可以直接使用hash,其复杂度为O(1)
其他的range操作复杂度一般为O(log(n))
2,redis的sort方法实现多字段排序
sort排序的用法:
SORT key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC | DESC] [ALPHA] [STORE destination]
1),普通列表排序
插入数据 LPUSH day 2 1 3 52 4 9 7 5 8
排序输出 SORT day LIMIT 25 DESC
插入数据 LPUSH test_str aaaa cccc dddd bbbb
排序输出 SORT test_str ALPHA ALPHA用于非数字型的value排序
2),基于列表的依赖外部键排序
插入数据 LPUSH uid 1 2 3 4; SET user_name_1 dddd;SET user_name_2 cccc;SET user_name_3 bbbb;SET user_name_4 aaaa;
SET user_day_1 10; SET user_day_2 8; SET user_day_3 6; SET user_day_4 4;
查询 sort uid by user_name_* ALPHA GET user_day_*
sort uid by user_day_* ALPHA GET user_name_*
3),基于hash数据结构的排序
插入数据
HMSET user_info_1 name eeee day 12
HMSET user_info_2 name ffff day 15
HMSET user_info_3 name gggg day 1
HMSET user_info_4 name hhhh day 13
查询
sort uid BY user_info_*->day get user_info_*->day get user_info_*->name
sort uid BY user_info_*->name alpha get user_info_*->day get user_info_*->name
3,存在问题
1)大数据量的sort比较耗时(解决方案,读写分离)
2)redis cluster可能存在排序的key不在同一台机器的问题