kafka入门及配置详解
一:安装zookeeper 略
二:安装kafka 略
kafka架构图及术语说明
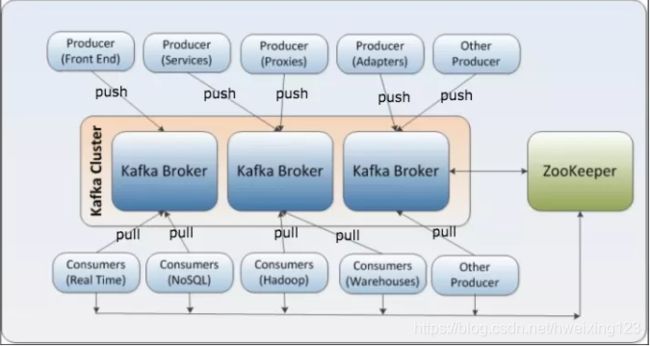
术语
- Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker,可以水平扩展,一般broker数量越多,集群吞吐率越高,而且kafka 每个节点可以有多个 broker - Producer
负责发布消息到Kafka broker,可以是web前端产生的page view,或者是服务器日志,系统CPU、memory等 - Consumer
消费消息。每个consumer属于一个特定的consumer group(可为每个consumer指定group name,若不指定group name则属于默认的group)。使用consumer high level API时,同一topic的一条消息只能被同一个consumer group内的一个consumer消费,但多个consumer group可同时消费这一消息。 - Zookeeper
通过Zookeeper管理集群配置,选举leader,以及在consumer group发生变化时进行rebalance - Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为topic。(物理上不同topic的消息分开存储,逻辑上一个topic的消息虽然保存于一个或多个broker上但用户只需指定消息的topic即可生产或消费数据而不必关心数据存于何处) - Partition
parition是物理上的概念,每个topic包含一个或多个partition,创建topic时可指定parition数量。每个partition对应于一个文件夹,该文件夹下存储该partition的数据和索引文件 - Segment
partition物理上由多个segment组成,每一个segment 数据文件都有一个索引文件对应 - Offset
每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息.
三:简单命令介绍
启动命令:./kafka-server-start.sh -daemon /Users/huangweixing/software/kafka_2.12-2.1.0/config/server.properties
创建topic命令:./kafka-topics.sh --create --topic test0 --replication-factor 1 --partitions 1 --zookeeper localhost:2181
查看kafka中topic情况:./kafka-topics.sh --list --zookeeper 127.0.0.1:2181
查看对应topic详细描述信息:./kafka-topics.sh --describe --zookeeper 127.0.0.1:2181 --topic test0
topic信息修改:kafka-topics.sh --zookeeper 127.0.0.1:2181 --alter --topic test0 --partitions 3 ## Kafka分区数量只允许增加,不允许减少
四:Kafka配置说明
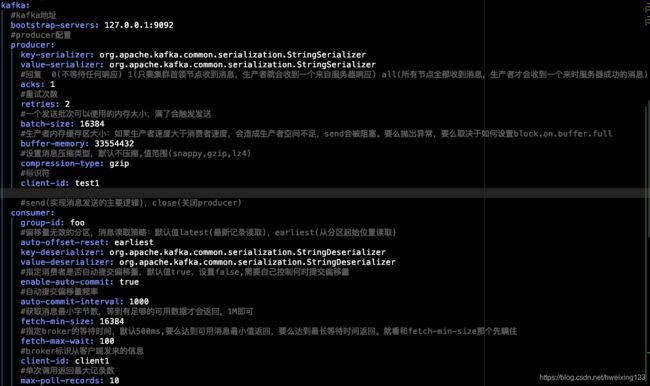
五:基础概念
初识kafka:
1:apache avro提供了一种紧凑型序列化格式,模式和消息体是分开的,当模式发生变化时,不需要重新生成代码,它还支持强类型和模式进化,其版本既向前兼容也向后兼容。
2:kafka消息通过主题进行分类,主题被分为若干个分区,一个分区就是一个提交日志,消息以追加的方式写入分区,然后以先入先出的顺序读取,一般一个主题包含多个分区,因此无法在真格主题内保证消息顺序性。
3:kafka通过分区来实现数据冗余和伸缩性
4:分区可以分布在不同机器上,也就是一个主题可以横跨多个服务器,以此提供比单个服务器更强大的性能
5:保留消息:该特性是kafka的一个重要特性,kafka broker可以针对主题设置策略,默认保留策略是要么保留一段时间,要么保留消息达到一定大小的字节数,当达到策略上线,旧消息就会被删除。
6:MirrorMaker工具:多集群时,集群间消息复制(多集群时需要考虑)
7:支持多生产者,多消费者。多个消费者可以组成一个群组,他们共享一个消息流,并保证整个群组对 每个给定的消息只处理一次。
8:能够保证亚秒级的延迟。
9:log.segment.bytes:设置日志片段达到多大就会被自动关闭,消息保留期限设置是基于日志片段关闭了才生效的。
10:基于时间的日志片段对磁盘性能会产生大的影响,因为broker自启动后就开始计算日志片段过期时间,对于数据量小的分区来说,日志片段的关闭操作总是同时发生。
11:建议使用最新版本的kafka,让消费者把偏移量提交到kafka服务器上,消除对Zookeeper依赖,并且kafka最好使用单独的zookeeper群组,
12:可以自定义分区器。
13:消费者可以独立消费某个分区 consumer.assign(partition)
六:消息系统需要思考的问题
如何保证消息的可靠性传输?
(从生产者)第一个配置要在producer端设置acks=all。这个配置保证了,follwer同步完成后,才认为消息发送成功。
在producer端设置retries=MAX,一旦写入失败,这无限重试
(消息队列丢数据)replication.factor参数,这个值必须大于1,即要求每个partition必须有至少2个副本,一般需要大于3个
min.insync.replicas参数,这个值必须大于1,这个是要求一个leader至少感知到有至少一个follower还跟自己保持联系
如何保证消息不被重复消费?
七:刚学,有很多没写到的,后续补
如何查看broker挂掉,如何重新分配,重启后又如何分配?
如何进行安全的再均衡,以及如何避免不需要的再均衡?
(1)比如,你拿到这个消息做数据库的insert操作。那就容易了,给这个消息做一个唯一主键,那么就算出现重复消费的情况,就会导致主键冲突,避免数据库出现脏数据。
(2)再比如,你拿到这个消息做redis的set的操作,那就容易了,不用解决,因为你无论set几次结果都是一样的,set操作本来就算幂等操作。
(3)如果上面两种情况还不行,上大招。准备一个第三方介质,来做消费记录。以redis为例,给消息分配一个全局id,只要消费过该消息,将