Java IO_转换流_字符集 尚学堂183
https://www.bilibili.com/video/BV1ct411n7oG?p=184
转换流也是一种装饰流:

转换流的作用是将字节流转换成字符流。
字节流可以处理一切东西,包括图片、视频、音频、纯文本等,所以很多系统或则框架的底层返回给你的都是字节流。
System.in 和 System.out 都是字节流。
使用的前提是给的字节流全是纯文本的内容,非纯文本的内容使用字符流是处理不了的。
在处理的过程中可以指定字符集。
InputStreamReader
An InputStreamReader is a bridge from byte streams to character streams: It reads bytes and decodes them into characters using a specified charset.
InputStreamReader是从字节流到字将流的桥梁。它读取的是字节。它指定charset 字符集将其解码(decode)为字符。
InputStreamReader的构造器:

可以指定字符集。
OutputStreamWriter
An OutputStreamWriter is a bridge from character streams to byte streams: Characters written to it are encoded into bytes using a specified charset.
OutputStreamWriter是从字符流到字节流的桥梁:使用指定的charset将写入的字符编码(encoded)为字节。
OutputStreamWriter的构造器:

可以指定字符集。
InputStreamReader 和 OutputStreamWriter 称为处理流。
作用:
1、字节流和字符流之间的饿桥梁。可以以字符流的形式操作字节流。
2、指定编码的字符集和解码的字符集。
转换流的第一个作用:将字节流转成字符流:
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class Test {
public static void main(String[] args) {
/**
* 操作 System.in 和 System.out
* System.in:字节输入流
* System.out:字节输出流
*/
try(BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(System.out));){
//循环获取键盘的输入(exit退出),输出此内容
String msg = "";
while(!msg.equals("exit")) {
msg = reader.readLine();//循环读取
//循环写出
writer.write(msg);
writer.newLine();
writer.flush();//强制刷新
}
} catch (IOException e) {
System.out.println("操作异常");
}
}
}
输出结果:

System.in,键盘输入,输入的都是纯文本(字符),所以可以对其转换。
System.in是字节输入流,InputStreamReader把它转成了字符流,所以可以加缓冲BufferedReader。
System.out是字节输出流,OutputStreamWriter把它转成了字符流,所以可以加缓冲BufferedWriter。
flush方法要放在while里面,它的内部缓冲比较大,否则内容会驻留在管道中,就不会写出去,不会进入到下一次的循环里。
new URL("https://www.baidu.com/").openStream()就是一个节点流,这个节点流是一个网络流,并且这个流是一个字节流。
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
public class Test {
public static void main(String[] args) {
//操作网络流 下载百度的源代码
try(InputStream is = new URL("https://www.baidu.com/").openStream();){
//操作(读取)
int temp;
while((temp = is.read()) != -1) {
System.out.println((char)temp);
}
} catch (IOException e) {
System.out.println("操作异常");
}
}
}
输出结果:
???????????????????°±???é??
下面省略,都是百度的源码。
其中的英文字符没有任何问题,但是中文会乱码。
让工程的字符集是UTF-8:

让这个字节流外面套一个InputStreamReader,就能解决中文乱码的问题:
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
public class Test {
public static void main(String[] args) {
//操作网络流 下载百度的源代码
try(InputStreamReader is = new InputStreamReader(new URL("https://www.baidu.com/").openStream());){
//操作(读取)
int temp;
while((temp = is.read()) != -1) {
System.out.print((char)temp);
}
} catch (IOException e) {
System.out.println("操作异常");
}
}
}
输出结果:
百度一下,你就知道
下面省略,都是百度的源码。
为了准确,建议指定 InputStreamReader 的字符集:
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
public class Test {
public static void main(String[] args) {
//操作网络流 下载百度的源代码
try(InputStreamReader is = new InputStreamReader(new URL("https://www.baidu.com/").openStream(), "UTF-8");){
//操作(读取)
int temp;
while((temp = is.read()) != -1) {
System.out.print((char)temp);
}
} catch (IOException e) {
System.out.println("操作异常");
}
}
}
因为不是所有网页的源码都是UTF-8的,有的是GBK的,有的是GB2312的。
套上转换流:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
public class Test {
public static void main(String[] args) {
//操作网络流 下载百度的源代码
try(BufferedReader reader = new BufferedReader(new InputStreamReader(new URL("https://www.baidu.com/").openStream(), "UTF-8"));){
//操作(读取)
String msg;
while((msg = reader.readLine()) != null) {
System.out.println(msg);
}
} catch (IOException e) {
System.out.println("操作异常");
}
}
}
输出结果是一样的,效率更高了。
new URL("https://www.baidu.com/").openStream()下载网络的资源(字节流),下载下来的全是字符,使用InputStreamReader转换一下,可以避免乱码的问题,前提是指定正确的字符集,要和工程的字符集统一,为了处理方便,再加一个BufferedReader。
转换的输出流OutputStreamWriter可以指定输出内容的字符集。如果没有指定字符集,默认字符集是和当前工程相关的。
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.URL;
public class Test {
public static void main(String[] args) {
try(BufferedReader reader =
new BufferedReader(
new InputStreamReader(
new URL("https://www.baidu.com/").openStream(), "UTF-8"));
BufferedWriter writer =
new BufferedWriter(
new OutputStreamWriter(
new FileOutputStream("baidu.html"), "UTF-8"));
){
//操作(读取)
String msg;
while((msg = reader.readLine()) != null) {
writer.write(msg);
writer.newLine();
}
writer.flush();
} catch (IOException e) {
System.out.println("操作异常");
}
}
}
输出结果:

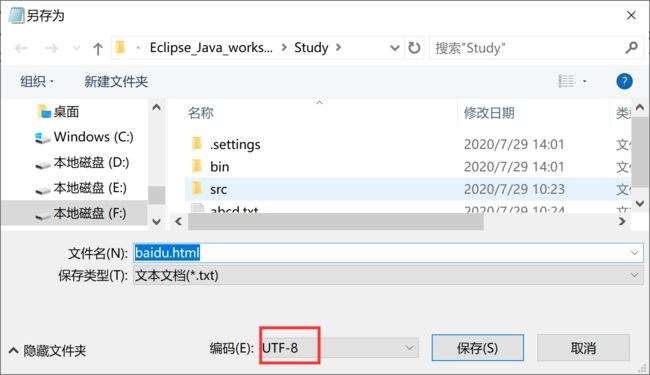
查看文件的字符集:

可以发现是UTF-8:
如果改成GBK:
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.URL;
public class Test {
public static void main(String[] args) {
try(BufferedReader reader =
new BufferedReader(
new InputStreamReader(
new URL("https://www.baidu.com/").openStream(), "UTF-8"));
BufferedWriter writer =
new BufferedWriter(
new OutputStreamWriter(
new FileOutputStream("baidu.html"), "GBK"));
){
//操作(读取)
String msg;
while((msg = reader.readLine()) != null) {
writer.write(msg);
writer.newLine();
}
writer.flush();
} catch (IOException e) {
System.out.println("操作异常");
}
}
}
会出现中文乱码:

ANSI就是GBK:
