OpenResty缓存
一、使用 Lua shared dict
官方文档:https://github.com/openresty/lua-nginx-module#ngxshareddict
使用的话首先需要在 nginx.conf 加上一句:
lua_shared_dict my_cache 128m;这个缓存是 Nginx 所有 worker 之间共享的,内部使用的 LRU 算法(最近最少使用)来判断缓存是否在内存占满时被清除。
function get_from_cache(key)
local cache_ngx = ngx.shared.my_cache
local value = cache_ngx:get(key)
return value
end
function set_to_cache(key, value, exptime)
if not exptime then
exptime = 0
end
local cache_ngx = ngx.shared.my_cache
local succ, err, forcible = cache_ngx:set(key, value, exptime)
return succ
end二、使用 Lua LRU cache
官方文档:https://github.com/openresty/lua-resty-lrucache
这个 cache 是 worker 级别的,不会在 Nginx wokers 之间共享。并且,它是预先分配好 key 的数量,而 shared dict 需要自己用 key 和 value 的大小和数量,来估算需要把内存设置为多少。
官方示例:
三、如何选择
1.shared_dict在nginx.conf预置shared_dict内存大小,shared_dict占用多大内存预设置。lrucache预设缓存key个数,
2.lrucache是每个worker单独占用的,不是多核间共享,减少锁竞争,同时带来内存多翻倍。更具业务不同选择
3.lrucache只有get,set和delete三个。shared_dict还可以add,replace,incr,get_keys,get_stale
shared.dict使用的是共享内存,每次操作都是全局锁,如果高并发环境,不同 worker 之间容易引起竞争。所以单个shared.dict的体积不能过大。lrucache是 worker 内使用的,由于 Nginx 是单进程方式存在,所以永远不会触发锁,效率上有优势,并且没有shared.dict的体积限制,内存上也更弹性,但不同 worker 之间数据不同享,同一缓存数据可能被冗余存储。
你需要考虑的,一个是
Lua lru cache提供的 API 比较少,现在只有 get、set 和 delete,而ngx shared dict还可以add、replace、incr、get_stale(在 key 过期时也可以返回之前的值)、get_keys(获取所有 key,虽然不推荐,但说不定你的业务需要呢);第二个是内存的占用,由于ngx shared dict是 workers 之间共享的,所以在多 worker 的情况下,内存占用比较少。
本节内容参考来自:https://moonbingbing.gitbooks.io/openresty-best-practices/content/ngx_lua/cache.html
四、对比nginx进程内外存缓存
nginx.conf
lua_shared_dict cache_ngx 128m;
lua_code_cache on;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
lua_shared_dict cache_ngx 128m;
server {
listen 8080;
#lua_code_cache off;
lua_code_cache on;
location /get_value {
content_by_lua_file conf/lua/get_value.lua;
}
}
}conf/lua/get_value.lua
这里使用的redis是二次封装过的https://moonbingbing.gitbooks.io/openresty-best-practices/content/redis/out_package.html
local redis = require "resty.redis_iresty"
local red = redis:new()
function set_to_cache(keu, value, exptime)
if not exptime then
exptime = 0
end
local cache_ngx = ngx.shared.cache_ngx
local succ, err, forcible = cache_ngx:set(key, value, exptime)
return succ
end
function get_from_cache(key)
local cache_ngx = ngx.shared.cache_ngx
local value = cache_ngx:get(key)
if not value then
value = get_from_redis(key)
set_to_cache(key, value)
end
return value
end
function get_from_redis(key)
local res, err = red:get(key)
if res then
return 'yes'
else
return 'no'
end
end
-- local res = get_from_redis('dog')
local res = get_from_cache('dog')分别打开get_from_redis和get_from_cache测试性能
ab -n 100000 -c 100 -k http://localhost:8080/get_value关注qps
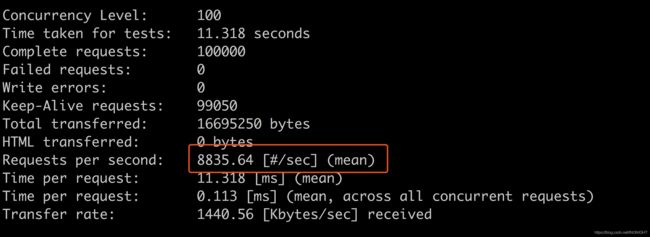
五、缓存失效风暴
local value = get_from_cache(key)
if not value then
value = query_db(sql)
set_to_cache(value, timeout = 100)
end
return value看上去没有问题,在单元测试情况下,也不会有异常。
但是,进行压力测试的时候,你会发现,每隔 100 秒,数据库的查询就会出现一次峰值。如果你的 cache 失效时间设置的比较长,那么这个问题被发现的机率就会降低。
为什么会出现峰值呢?想象一下,在 cache 失效的瞬间,如果并发请求有 1000 条同时到了 query_db(sql) 这个函数会怎样?没错,会有 1000 个请求打向数据库。这就是缓存失效瞬间引起的风暴。它有一个英文名,叫 "dog-pile effect"
问题的根源是并发的请求都是查询同一个数据的sql语句,在前面加一把锁,让同时查询sql去获取缓存真实值的动作,只进行一次,加一把锁
怎么解决?自然的想法是发现缓存失效后,加一把锁来控制数据库的请求。具体的细节,春哥在 lua-resty-lock 的文档里面做了详细的说明,我就不重复了,请看这里。多说一句,lua-resty-lock 库本身已经替你完成了 wait for lock 的过程,看代码的时候需要注意下这个细节。
openresty解决方案:https://github.com/openresty/lua-resty-lock#for-cache-locks