Java容器之各种Set
原文转自我自己的个人公众号:https://mp.weixin.qq.com/s/M6Qwe24Lv3Bl02dNAObgQA
由于我是从公众号上直接复制粘贴过来的,排版上可能有问题。推荐使用上方连接查看原文。
目录:
-
Set简介
-
HashSet简介
-
打破Set中元素不可重复的约束
-
构造方法
-
新增、删除和遍历方法
-
LinkedHashSet
-
TreeSet
-
总结
1. Set简介
首先我们来对比下Set接口的方法:

通过上图我们可以看出,Set接口中的方法全部都是Collection接口中的。我们下面再看看Collection接口中的方法:
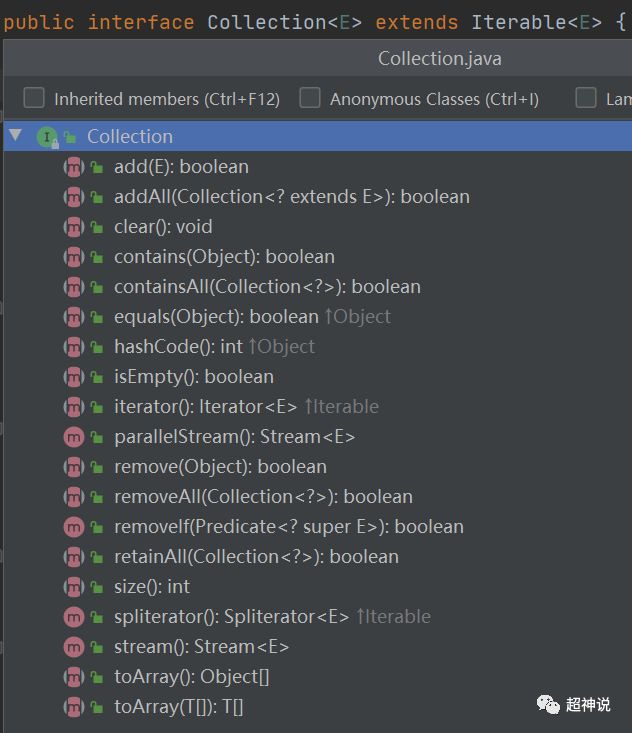
对比之后可以发现,Set接口除了没有拷贝Collection接口中的parallelStream、removeIf和stream这三个方法外,其余都是拷贝了一边,而且方法的返回值和参数一摸一样,因此不能说是重载。
那么Set为什么要将父接口的这些方法都原模原样拷贝一边呢?
这个原因是因为Set对这些方法加入了额外的限制条件,而这些条件都在Set接口内的方法注释中进行了说明。说白了,就是为了找个地方写注释。
Set接口的javadoc中说明了,该接口内的元素是不能重复的,也就是说不包含两个元素e1和e2,并且e1.equals(e2)返回true。元素中至多只能有一个null元素(有的实现类可能不允许有null)。
这里说一个重点:上面不是说Set中不会有重复元素吗,这个是不严谨的,有种方法可以让Set中出现重复元素,但强烈不建议这样使用,并且应该有意识地避免这种情况。具体后面用代码说明。
2. HashSet简介
HashSet是Set的实现类之一,也是我们使用最多的一种Set。名字是HashSet,就意味着它内部的元素是无顺序的,并且随着元素数量的增减,元素的顺序也是会发生改变的。HashSet允许元素中有一个null元素。
实际上,HashSet内部是通过一个HashMap实例来实现自身功能的。因此,从效率上来讲,add、remove、contains和size这些操作的时间复杂度都是O(1),而遍历元素的时间复杂度取决于HashSet内部的元素数量和内部HashMap实例的容量,这和我们之前讲HashMap时是一样的。因此如果要考虑遍历性能,则不应使用过大的初始容量和过小的加载因子。
3. 打破Set中元素不可重复的约束
第1点中说到,Set中的元素不可重复,而判定两个元素是否重复使用的是equals方法。下面我们来看一段代码:
private static class User {private int id;public User(int id) {this.id = id;}@Overridepublic boolean equals(Object obj) {return ((User) obj).id == id;}@Overridepublic int hashCode() {return id;}}public static void main(String[] args) {User user1 = new User(1);User user2 = new User(2);User user3 = new User(1);Set users = new HashSet(); users.add(user1);users.add(user2);users.add(user3);System.out.println(users);user2.id = 1;System.out.println(users);Object[] userArray = users.toArray();System.out.println(userArray[0].equals(userArray[1]));}
我们首先定义了一个内部类User,重写了equals方法,当两个User的id属性相等时,我们就认为这两个对象是一样的。在main方法中,定义了三个User对象,id分别是1、2和1,然后创建一个HashSet类型的对象users,向其中放入user1、user2和user3,打印出users中的元素信息。然后将user2的id修改成1,再打印users中的元素信息,然后使用equals比较users中的两个元素。下面是输出的结果:

这里需要解释一下相同的概念,在Java中,两个元素相同使用equals来判定,而不是判断两个对象的地址是否一致。当然,默认的equals方法中是判断地址是否一致的。我们的User对象重写了equals方法,只要id一样,我们就说它们相同或相等。下面是Object中的equals默认实现:
public boolean equals(Object obj) {return (this == obj);}
从上面的结果中我们可以看出,第一次打印前,向users中放了user1、user2和user3,由于Set不允许重复元素,而user1和user3的id相同,因此最终放入的只有一个user1和一个user2。第二次输出前,将user2的id修改为1,然后打印出的结果,这时会发现结果中的两个元素时相同的,第三次打印是对比users中的两个元素,我们发现equals方法也返回了true,也就是说users这个HashMap中放入了两个相同的元素。
这里还需要注意一点,只重写equals方法往往是不够的,还需要重写hashCode方法,因为如果底层使用的是Hash存储,hashCode才是用来表示对象是否一致的。因此通常情况下,equals方法和hashCode的语义必须保持一致。
从代码演示的结果中我们可以看出,最终,我们的HashMap对象中放入了两个相同的元素。
在Set的javadoc中对这种现象进行了特别说明:当Set内的元素是可变元素,在该元素属性发生变化并影响equals方法的比较结果时,Set的行为不做规定。HashSet也因此对这种情况不做任何特殊处理。再次强调一下,这种做法极易造成混乱,不管是有意还是无意,都需要尽力避免这种情况的发生!
4. 构造方法

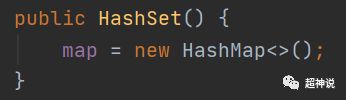
HashSet总共有5个构造方法。在无参构造方法中,只是创建了一个HashMap,如下:
传入集合参数的拷贝构造方法中,根据拷贝的集合中元素的个数对HashMap的初始容量进行了定义,最小设置为16,否则设置为拷贝的集合中元素个数除以0.75,这其实含义是根据HashMap的默认容量和加载因子计算出当前元素个数时的应有容量,代码如下:

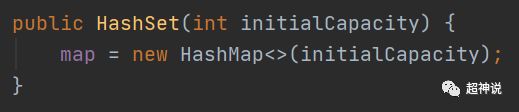
传入一个int参数的构造方法中在创建HashMap对象时用于设置初始容量:
传入两个参数的,不难猜出,传入了初始容量和加载因子。这里就不贴代码了。
传入三个参数的构造方法,这个方法简直绝了。前两个参数含义分别是初始容量和加载因子,第三个参数完全没用,仅仅是为了区分两个参数的构造方法。那么为什么要区分呢,因为三个参数的构造方法内部使用的不是HashMap,而是LinkedHashMap,这个方法是专门给LinkedHashSet中的所有构造方法调用的,因此并没有声明成public,而是包访问级别。我有点纳闷,为什么不把这个方法放到LinkedHashSet中呢?

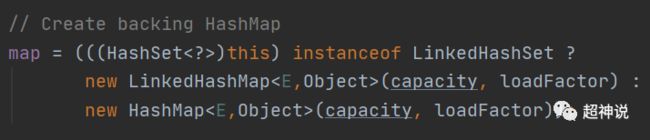
针对上面提出的问题,我进行了一些思考和搜索。这样做的好处有,HashSet可以控制其子类内部的HashMap实现类,目前HashSet的子类只有LinkedHashSet;另一个好处是三个参数的构造器是包访问权限,使得在从ObjectInputStream中反序列化一个HashMap类型时,只需要创建对应类型的HashMap即可。下面是HashSet的readObject方法中的相关代码:
但实际上,上面说的两个好处其实也可以算是缺点。在stackoverflow上也有相关的讨论,大家的观点基本上都认为这是一个不好的设计,Java中的很多代码都被认为是不好的实现,但是由于历史原因以及并没有太大的影响,因此没有进行修改。
5. 新增、删除和遍历方法
HashSet中的方法比较少,我们这里重点看一下add和remove方法
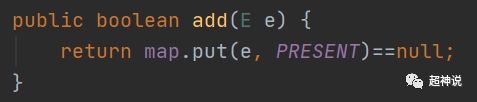
可以看到add方法实际上就是将传入的对象作为key存入底层map中,然后会调用这个对象的hashCode方法再经过一次移位的hash操作得到底层数组的下标值,在该下标位置放入value,这里的value为PRESENT,是一个静态的Object对象,所有HashSet共用一个。

remove方法就更简单了,直接就是调用map的remove方法。
同样的,遍历方法也直接使用的是map中key的迭代器来完成,如下:
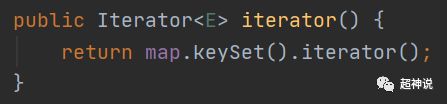
从上面的方法实现可以看出,HashSet的能力都是依靠HashMap来完成的。
6. LinkedHashSet
HashSet的内部时间确实是太简单了,几乎没有提供自己的能力。我们就顺带着看看LinkedHashSet吧。
好吧,基本也不用看了,想看的话,直接移步到我之前写的LinkedHashMap就可以了。

上图可以看到,LinkedHashSet中只有5个方法,其中4个是构造方法,内部直接调用父类那个神奇的三参数的构造方法。最后一个spliterator方法用于返回Spliterator迭代器,相比普通的迭代器,Spliterator迭代器可以用于并行处理,就是可以把一个集合查分成多个子集合然后并行的遍历,这个迭代器是Java8开始提供的,这里不做具体介绍。
这里需要注意的一点是,在LinkedHashSet的拷贝构造函数中,对初始容量进行了特殊的设置:
public LinkedHashSet(Collection c) {super(Math.max(2*c.size(), 11), .75f, true);addAll(c);}
我看到这里的时候有两个疑问,首先为什么初始容量和HashSet不一致,比如HashSet中设置的是:
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));也就是说,HashMap中的初始容量在size小于16时取值为16,大于16时取值为拷贝的集合中的元素个数除以0.75,约为1.33倍的size。通过对HashMap的学习我们知道,设置的容量会影响HashMap内部数组的大小,而这个大小的变化都是2的n次方,因此当1.33倍的size结果不是2的n次方时,会取比该值大的最近一个2的n次方值。在看LinkedHashSet,是当size小于11时取值为11,当大于11时取值为2倍的size,同样也有2的n次方这样的处理。
查阅了一些资料后发现明白有太多相关的信息,只有在stackoverflow上有一篇讨论不是很多的文章,里面的观点也是一种猜测,觉得这时因为LinkedHashSet扩容会比HashSet效率更低,因此这样做可以让LinkedHashMap在执行拷贝构造函数时能够尽早扩容、尽多扩容。
我的第二个问题是为什么是11。当size小于11时,初始会将底层的数组大小初始化为11,这样就会更早的执行扩容,到达11时会扩容到16,相比比默认容量就是16,多了一次扩容操作。但是反过来想,只要size大于11,初始容量就会是2倍的size,否则使用默认的话,要到16才会扩容。效果依然是尽早扩容、尽多扩容。但是为什么是11而不是别的数字呢,相比默认的16而已,11貌似好像也占不了太多的便宜。但是仔细想想,11和16经过几轮扩容之后,差别可能就会非常大了,而且差别会越来越大。就像两条不相交的线,随着线的延长,差距会越来越大。这里的11可能是官方经过测试之后的经验值吧。目前在网上没有找到更详细的描述。
7. TreeSet
TreeSet是不同于HashSet的另一种Set,不过上面分析过HashSet后,大家可能都能猜到,TreeSet内部持有一个TreeMap,所有功能都依赖于这个TreeMap对象来完成。这里就细说了。
8. 总结
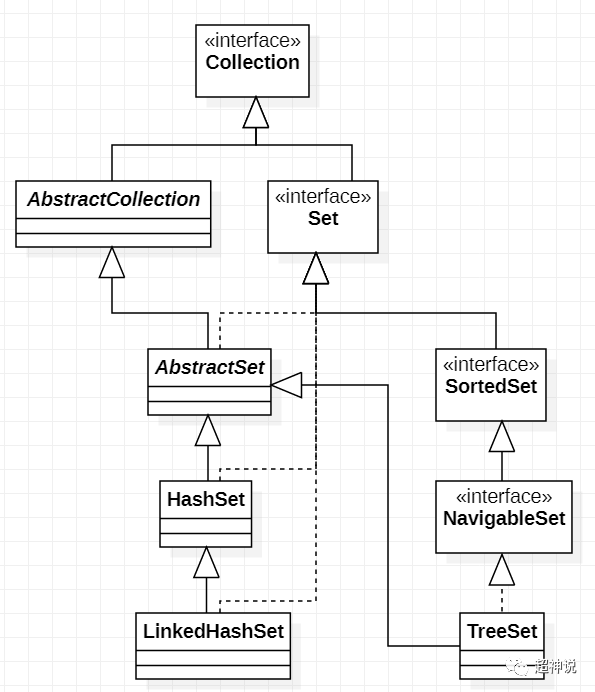
相比Map和List,Set由于能力全部依托于Map,因此只要理解了Map,Set是非常好理解的。最后我们用一张类图,来总结一下上面介绍的这几个Set。
更多内容请关注我的公众号:
