搞定Java多线程:concurrent并发包梳理
在多线程并发编程中,java.util.concurrent 是重中之重,里面提供的方法类非常实用,当然页面面试要点,需要耐心梳理。
主要分这几类,
- tools:CountDownLatch(闭锁)、CyclicBarrier(栅栏)、Semaphore(信号量)等。
- locks:Lock、ReentrantLock(重入锁)、ReadWritLock(读写锁)等。
- executor:Executor(线程池)、Future、Callable等。
- collection:ConcurrentHashMap、CopyOnWriteArrayList、BlockingQueue(阻塞队列)等。
- atomic:AtomicInteger、AtomicLong等。

一、CountDownLatch(闭锁)、CyclicBarrier(栅栏)、Semaphore(信号量)
1、CountDownLatch(闭锁)
CountDownLatch是一个计数器闭锁,用来实现使一个线程等待其他线程各自执行完毕后再执行的功能。CountDownLatch是通过一个计数器来实现的,计数器的初始值是线程的数量。每当一个线程执行完毕后,计数器的值就-1,当计数器的值为0时,表示所有线程都执行完毕,然后在闭锁上等待的线程就可以恢复工作了。
原理:CountDownLatch基于AQS共享锁,await()使当前线程阻塞等待,countDown()计数器递减。AQS全局维护的有一个volatile修饰的state字段,当state为0时就会通知countDownLatch等待线程执行。这也就是所以我们在new CountDownLatch(int n) 时指定的参数,n为多少,也就是要调用多少次countDown()方法。
假设有N个任务,那么可以用N来初始化一个 CountDownLatch,然后将这个 latch 的引用传递到各个线程中,在每个线程完成了任务后,调用 latch.countDown() 代表完成了一个任务。
//调用await()方法的线程会被挂起,它会等待直到count值为0才继续执行
public void await() throws InterruptedException { };
//和await()类似,只不过等待一定的时间后count值还没变为0的话就会继续执行
public boolean await(long timeout, TimeUnit unit) throws InterruptedException { };
//将count值减1
public void countDown() { }; 2、CyclicBarrier(栅栏)
CyclicBarrier是一个回环栅栏,可重复使用(CountDownLatch只能使用一次)。她的作用就是N个线程相互等待,任何一个线程完成之前,所有的线程都必须等待。CyclicBarrier是一种线程间的屏障,一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
CyclicBarrier基于AQS独占锁来执行await方法。
public CyclicBarrier(int parties)
// barrierAction表示最后一个到达线程要做的任务,可以用于多线程计算数据,最后合并计算结果的场景
public CyclicBarrier(int parties, Runnable barrierAction)
public int await() throws InterruptedException, BrokenBarrierException
public int await(long timeout, TimeUnit unit) throws InterruptedException, BrokenBarrierException, TimeoutException3、Semaphore(信号量)
Semaphore,信号量,可以限定同时访问的线程个数,用来协调访问资源的线程数量,使其处在一个恒定的值。线程调用 acquire() 获取一个许可,如果没有许可就等待,线程调用 release() 释放一个许可。网络应用中为了保护服务器不被流量洪峰冲夸,会进行限流,限流会使用令牌桶算法,Semaphore就可以实现令牌桶:访问线程先拿到令牌才能访问,访问完后把令牌归还到桶中以便供其他线程使用,就保证了访问资源的线程数量和令牌数量一至。
Semaphore基于AQS共享锁,内部代码布局和ReentrantLock类似,支持公平锁和非公平锁设置,默认为非公平性锁。Semaphore使用中的关键代码,
//信号量,只允许 3个线程同时访问
Semaphore semaphore = new Semaphore(3);
//获取许可
semaphore.acquire();
// 释放许可
semaphore.release();4、CountDownLatch、CyclicBarrier、Semaphore的区别
CountDownLatch是使一个(或一组)线程等待其他线程各自执行完毕后再执行;CyclicBarrier是N个线程相互等待;Semaphore用来限定同时访问的线程个数。
- CountDownLatch和CyclicBarrier都是以计数器的的形式来协调线程同步的,一个显著的区别是CyclicBarrier可重用,CountDownLatch是一次性的。
- CountDownLatch和CyclicBarrier还有一个语义层面上的区别是,Count DownLatch是一个(或一组)线程等待另外N个线程执行完毕。CyclicBarrier是N个线程相互等待,直到都执行毕。
- CountDownLatch强调依赖,CyclicBarrier强调协作。CyclicBarrier典型的应用场景就是大任务拆解为小任务,然后合并计算结果,比如多线程下载大文件,多个下载线程将自己分配的文件段下载完毕后,合并线程才开始进行文件合并操作。
- CyclicBarrier提供的方法更丰富,比如getNumberWaiting()方法可以获得CyclicBarrier阻塞的线程数量,isBroken()方法用来了解阻塞的线程是否被中断,还可以提供一个barrierAction,合并多线程计算结果。
- Semaphore用来限定访问受限资源的线程数量,典型的应用场景是流量控制,比如并发操作数据库,数据库连接池只有10个,必须保证只能有10个线程去获取连接,否则会报错。
- Semaphore可以进行简单的服务端限流,比如一个RPC服务器只能支撑200QPS,就可以用Semaphore去限制请求RPC的线程数量。当然对于复杂的服务端限流还得使用更高效令牌桶(Token Bucket)或者漏桶(Leaky Bucket)算法。
二、Locks
1、ReentrantLock(重入锁)
ReentrantLock,重入锁,表示持有资源的锁的线程可对资源进行重复加锁,其支持公平和非公平两种模式,其默认使用非公平锁。ReentranLock是基于AQS实现的独占锁,当时它本身并没有继承AQS,而是在内部定义了一个Sync静态内部类来继承AQS,然后调用静态内部类来实现的。Sync和AQS一样是一个抽象类,它本身还有两个子类分别是NonfairSync(非公平锁)、FairSync(公平锁)。
Lock 关键代码,lock.lock() 和 lock.unlock(),
public class ReentrantLockTest {
public static void main(String[] args) throws InterruptedException {
ReentrantLock lock = new ReentrantLock();
for (int i = 1; i <= 3; i++) {
lock.lock(); //手动加锁 synchronized(this)
}
for(int i=1;i<=3;i++){
try {
//todo
} finally {
lock.unlock(); //手动释放锁
}
}
}
}2、ReentrantLock和Syncronized的对比
- 相同:都是同步锁,可重入锁。
- 不同:
- Syncronized时JVM实现的关键字,ReentrantLock是JDK(java类)实现的。
- ReentrantLock需要配合try/finally方法进行使用。
- ReentrantLock减少操作系统内核间的切换,提高了效率,不过Syncronized在jdk1.6之后进行了优化,效率也不低。
- ReentrantLock是可以等待中断的,Syncronized不可以中断。
- ReentrantLock提供公平锁和非公平锁,Syncronized只是非公平锁。
- ReentrantLock的API更丰富,可扩展性更好。
3、ReadWriteLock(读写锁)
ReadWriteLock是一个接口,主要有两个方法:readLock()和writeLock()。ReadWriteLock管理一组锁,一个是只读的锁,一个是写锁。ReadWriteLock的读锁是共享模式,写锁是独占模式。
并发编程中,Synchronized关键字存在明显的一个性能问题就是读与读之间互斥,降低了读写的效率。并发包中的ReadWriteLock读写锁帮我们实现了最好的效果,可以做到读和读互不影响,读和写互斥,写和写互斥,提高读写的效率。
Java并发库中ReetrantReadWriteLock(可重入读写锁)实现了ReadWriteLock接口并添加了可重入的特性。
- Java并发库中ReetrantReadWriteLock(可重入读写锁)实现了ReadWriteLock接口并添加了可重入的特性
- ReetrantReadWriteLock读写锁的效率明显高于synchronized关键字
- ReetrantReadWriteLock读写锁的实现中,读锁使用共享模式;写锁使用独占模式,换句话说,读锁可以在没有写锁的时候被多个线程同时持有,写锁是独占的
- ReetrantReadWriteLock读写锁的实现中,需要注意的,当有读锁时,写锁就不能获得;而当有写锁时,除了获得写锁的这个线程可以获得读锁外,其他线程不能获得读锁
三、Executor框架和线程池
1、Executor框架
线程池就是线程的集合,线程池集中管理线程,以实现线程的重用,降低资源消耗,提高响应速度。从JDK1.5开始,为了把工作单元与执行机制分离开,Executor框架诞生了,他是一个用于统一创建与运行的接口。Executor框架实现的就是线程池的功能。
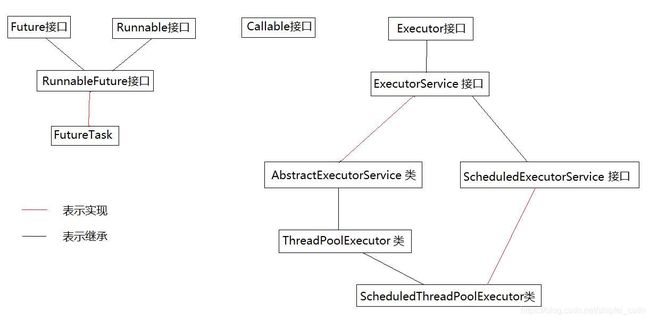
Executor框架主要由3大部分组成:
- 任务: 包括被执行的任务需要实现的接口:Runable 接口、Callable接口;
- 任务的执行: 包括任务执行机制的核心接口Executor,以及继承自Executor的ExecutorService接口。Executor框架有两个关键类实现了ExecutorService接口:ThreadPoolExecutor 和 ScheduledThreadPoolExecutor、ForkJoinPool;
- 任务的异步计算结果: 包括Future接口和实现Future接口的FutureTask类、ForkJoinTask类。
Executor框架的成员:
- Runnable和Callable接口,可以被ThreadPoolExecutor执行。区别是Runnable不返回结果,Callable返回结果。
- Executor 接口
- ExecutorService 接口
- AbstractExecutorService 类
- ThreadPoolExecutor,通常使用工厂类Executors提供的静态方法来创建线程池。
2、Executor框架的执行示意图

- 创建Runnable并重写run()方法或者Callable对象并重写call()方法
- 创建Executor接口的实现类ThreadPoolExecutor类的对象,然后调用其execute()方法或者submit()方法把工作任务添加到线程中,如果有返回值则返回Future对象。
- 调用Future对象的get()方法后的返回值,或者调用Future对象的cancel()方法取消当前线程的执行,最后关闭线程池。
3、ThreadPoolExecutor 线程池参数
ThreadPoolExecutor是线程池的实现类,
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) 1)corePoolSize,线程池的基本大小。当提交一个任务到线程池时,线程会创建一个线程来执行任务,即使其他空闲的基本线程能创建线程也会创建线程,等到到需要执行的任务数大于线程池基本大小corePoolSize时就不再创建。
2)maximumPoolSize,线程池允许最大线程数。如果阻塞队列满了,并且已经创建的线程数小于最大线程数,则线程池会再创建新的线程执行。因为线程池执行任务时是线程池基本大小满了,后续任务进入阻塞队列,阻塞队列满了,再创建线程直到最大线程数。
3)keepAliveTime,空闲线程的存活的时间。
4)TimeUnit,线程存活的时间的单位,天、小时、时、分、秒、毫秒等。
5)workQueue:任务等待队列,用于保存等待执行的任务的阻塞队列。
6)threadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字。
7)handler:饱和策略(丢弃策略),表示当拒绝处理任务时的策略。当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。
4、Executors 提供的四种线程池
按照最佳实践,我们尽量优先使用Executors提供的静态方法来创建线程池,如果Executors提供的方法无法满足要求,再自己通过ThreadPoolExecutor类来创建线程池。
- newSingleThreadExecutor:创建一个线程的线程池,在这个线程池中始终只有一个线程存在。如果线程池中的线程因为异常问题退出,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
- newFixedThreadPool:创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
- newCachedThreadPool:可根据实际情况,调整线程数量的线程池,线程池中的线程数量不确定,如果有空闲线程会优先选择空闲线程,如果没有空闲线程并且此时有任务提交会创建新的线程。在正常开发中并不推荐这个线程池,因为在极端情况下,会因为 newCachedThreadPool 创建过多线程而耗尽 CPU 和内存资源。
- newScheduledThreadPool:此线程池可以指定固定数量的线程来周期性的去执行。比如通过 scheduleAtFixedRate 或者 scheduleWithFixedDelay 来指定周期时间。PS:另外在写定时任务时(如果不用 Quartz 框架),最好采用这种线程池来做,因为它可以保证里面始终是存在活的线程的。
public static void test(){
Executors.newSingleThreadExecutor();
Executors.newFixedThreadPool(10);
Executors.newCachedThreadPool();
Executors.newScheduledThreadPool(10);
}
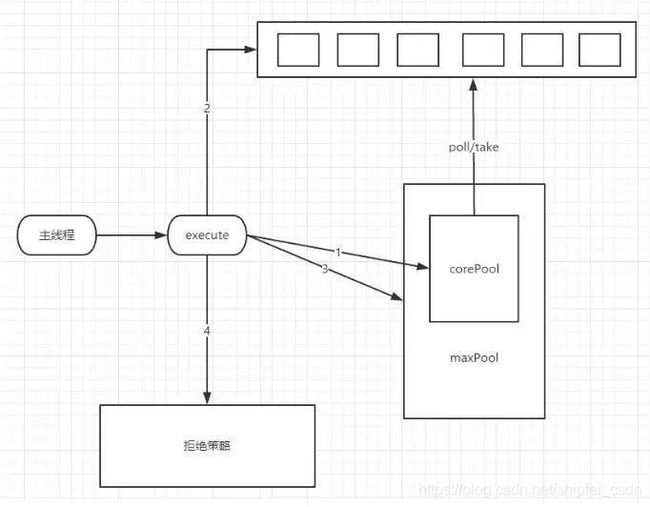
5、线程池执行流程图
注意图中的序号:corePool --> queue -->maxPool -->handler
四、并发集合
1、ConcurrentHashMap
1)CurrentHashMap(JDK1.7版本)
在JDK1.7中ConcurrentHashMap采用了数组+Segment分段锁的方式实现。
- Segment(分段锁):ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表,同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
- 内部结构:ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。
优点:写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,ConcurrentHashMap的并发度就是segment的大小,默认为16,这意味着最多同时可以有16条线程操作ConcurrentHashMap。
缺点:ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作:第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部。这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长。
2)CurrentHashMap(JDK1.8版本)
JDK8中ConcurrentHashMap的采用了数组+链表+红黑树的实现方式来设计,内部大量采用CAS操作。JDK8中ConcurrentHashMap在链表的长度大于某个阈值的时候会将链表转换成红黑树进一步提高其查找性能。
JDK8中彻底放弃了Segment转而采用的是Node,其设计思想也不再是JDK1.7中的分段锁思想。Node:保存key,value及key的hash值的数据结构。其中value和next都用volatile修饰,保证并发的可见性。Java8 ConcurrentHashMap结构基本上和Java8的HashMap一样,不过保证线程安全性。
3)总结
其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树。
- 数据结构:取消了Segment分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
- 保证线程安全机制:JDK1.7采用segment的分段锁机制实现线程安全,其中segment继承自ReentrantLock。JDK1.8采用CAS+Synchronized保证线程安全。
- 锁的粒度:原来是对需要进行数据操作的Segment加锁,现调整为对每个数组元素加锁(Node)。
- 链表转化为红黑树:定位结点的hash算法简化会带来弊端,Hash冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。
- 查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)。
2、CopyOnWriteArrayList
1)写入时复制(CopyOnWrite)思想
Copy-On-Write 简称 COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容 Copy 出去形成一个新的内容然后再改,这是一种延时懒惰策略。
CopyOnWrite 容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行 Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对 CopyOnWrite 容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以 CopyOnWrite 容器也是一种读写分离的思想,读和写不同的容器。
CopyOnWrite 的名字就是这样来的。在写的时候,先 copy 一个,操作新的对象。然后在覆盖旧的对象,保证 volatile 语义。
2)CopyOnWriteArrayList 有什么优点?
读写分离,适合写少读多的场景。使用了独占锁,支持多线程下的并发写。
3)CopyOnWriteArrayList 是如何保证写时线程安全的?
因为用了 ReentrantLock 独占锁,保证同时只有一个线程对集合进行修改操作。
4)CopyOnWrite 怎么理解?
写时复制。就是在写的时候,先 copy 一个,操作新的对象。然后在覆盖旧的对象,保证 volatile 语义。新数组的长度等于旧数组的长度 + 1。
5)从 add 方法的源码中你可以看出 CopyOnWriteArrayList 的缺点是什么?
占用内存,写时 copy 效率低。因为 CopyOnWrite 的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比如说 200M 左右,那么再写入 100M 数据进去,内存就会占用 300M,那么这个时候很有可能造成频繁的 Yong GC 和 Full GC。
6)CopyOnWrite容器优缺点总结
使用场景:适合读多写少的场景。
优点:
- 读写分离,读和写分开
- 最终一致性
- 使用另外开辟空间的思路,来解决并发冲突
缺点:
- 由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致 young gc 或者 full gc。
- 不能用于实时读的场景,像拷贝数组、新增元素都需要时间,所以调用一个 set 操作后,读取到数据可能还是旧的,虽然CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求。
- 由于实际使用中可能没法保证 CopyOnWriteArrayList 到底要放置多少数据,万一数据稍微有点多,每次 add/set 都要重新复制数组,这个代价实在太高昂了。在高性能的互联网应用中,这种操作分分钟引起故障。
3、BlockingQueue(阻塞队列)
1)阻塞队列 (BlockingQueue)是Java util.concurrent包下重要的数据结构,BlockingQueue提供了线程安全的队列访问方式:当阻塞队列进行插入数据时,如果队列已满,线程将会阻塞等待直到队列非满;从阻塞队列取数据时,如果队列已空,线程将会阻塞等待直到队列非空。并发包下很多高级同步类的实现都是基于BlockingQueue实现的。
2)BlockingQueue 具有 4 组不同的方法用于插入、移除以及对队列中的元素进行检查。如果请求的操作不能得到立即执行的话,每个方法的表现也不同。这些方法如下:
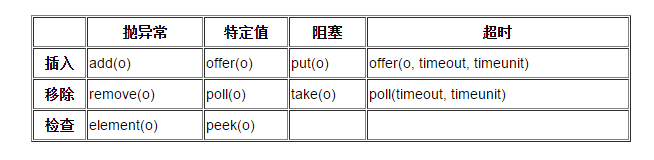
- 抛异常:如果试图的操作无法立即执行,抛一个异常。
- 特定值:如果试图的操作无法立即执行,返回一个特定的值(常常是 true / false)。
- 阻塞:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。
- 超时:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是true / false)。
3)BlockingQueue 的实现类:
- ArrayBlockingQueue:ArrayBlockingQueue 是一个有界的阻塞队列,其内部实现是将对象放到一个数组里。有界也就意味着,它不能够存储无限多数量的元素。它有一个同一时间能够存储元素数量的上限。你可以在对其初始化的时候设定这个上限,但之后就无法对这个上限进行修改了(译者注:因为它是基于数组实现的,也就具有数组的特性:一旦初始化,大小就无法修改)。
- DelayQueue:DelayQueue 对元素进行持有直到一个特定的延迟到期。注入其中的元素必须实现 java.util.concurrent.Delayed 接口。
- LinkedBlockingQueue:LinkedBlockingQueue 内部以一个链式结构(链接节点)对其元素进行存储。如果需要的话,这一链式结构可以选择一个上限。如果没有定义上限,将使用 Integer.MAX_VALUE 作为上限。
- PriorityBlockingQueue:PriorityBlockingQueue 是一个无界的并发队列。它使用了和类 java.util.PriorityQueue 一样的排序规则。你无法向这个队列中插入 null 值。所有插入到 PriorityBlockingQueue 的元素必须实现 java.lang.Comparable 接口。因此该队列中元素的排序就取决于你自己的 Comparable 实现。
- SynchronousQueue:SynchronousQueue 是一个特殊的队列,它的内部同时只能够容纳单个元素。如果该队列已有一元素的话,试图向队列中插入一个新元素的线程将会阻塞,直到另一个线程将该元素从队列中抽走。同样,如果该队列为空,试图向队列中抽取一个元素的线程将会阻塞,直到另一个线程向队列中插入了一条新的元素。据此,把这个类称作一个队列显然是夸大其词了。它更多像是一个汇合点。
五、Atomic(原子操作类)
atomic,原子操作类,是通过自旋CAS操作volatile变量实现的。在多线程环境下,i++操作是不安全的,J.U.C包下的atomic类提供了比synchronized关键字更好的选择。
- CAS是compare and swap的缩写,即比较后(比较内存中的旧值与预期值)交换(将旧值替换成预期值)。它是sun.misc包下Unsafe类提供的功能,需要底层硬件指令集的支撑。
- 使用volatile变量是为了多个线程间变量的值能及时同步。
1)Atomic类的优点
Atomic类是cas乐观锁的实现,比synchroized更轻量,性能更好。
在JDK1.6之前,synchroized是重量级锁,即操作被锁的变量前就对对象加锁,不管此对象会不会产生资源竞争。这属于悲观锁的一种实现方式。而CAS会比较内存中对象和当前对象的值是否相同,相同的话才会更新内存中的值,不同的话便会返回失败。这是乐观锁的一中实现方式。这种方式就避免了直接使用内核状态的重量级锁。
但是在JDK1.6以后,synchronized进行了优化,引入了偏向锁,轻量级锁,其中也采用了CAS这种思想,效率有了很大的提升。
2)Atomic类的缺点
- ABA问题
- 因为CAS会检查旧值有没有变化,这里存在这样一个有意思的问题。比如一个旧值A变为了成B,然后再变成A,刚好在做CAS时检查发现旧值并没有变化依然为A,但是实际上的确发生了变化。解决方案可以沿袭数据库中常用的乐观锁方式,添加一个版本号可以解决。原来的变化路径A->B->A就变成了1A->2B->3C。
- 自旋时间过长
- 使用CAS时非阻塞同步,也就是说不会将线程挂起,会自旋(无非就是一个死循环)进行下一次尝试,如果这里自旋时间过长对性能是很大的消耗。如果JVM能支持处理器提供的pause指令,那么在效率上会有一定的提升。