docker学习笔记(9):nvidia-docker安装、部署与使用
引言
NVIDIA深度学习GPU训练系统(又名DIGITS)是用于训练深度学习模型的Web应用程序。它将深度学习的力量交到了工程师和数据科学家手中。它可用于快速训练用于图像分类,分割和目标检测任务的高精度深度神经网络(DNN)。当前受支持的框架为:Caffe,Torch和Tensorflow。
借助最新的19.03.0 Beta版本,现在您无需花时间下载NVIDIA-DOCKER插件,而无需依靠nvidia-wrapper来启动GPU容器。现在,您可以在docker runCLI中使用–gpus选项,以允许容器无缝使用GPU设备。
New Docker CLI API Support for NVIDIA GPUs under Docker Engine 19.03.0 Pre-Release
nvidia-docker部署使用
前置环境
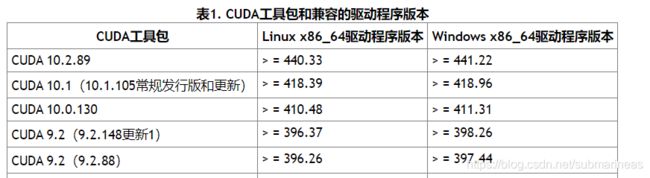
首先是需要cuda以及cuda对应的gcc、g+等依赖,目前19年的gcc为8.3.1,cuda是向上兼容,所以如果显卡驱动只需要最低版本高于上表cuda接受的最低版本限制就行。然后关于cuda以及docker的安装可以看我之前的两篇文章:
Linux下从0开始GPU环境搭建与启动测试
docker使用笔记(1):docker介绍与安装
如果cuda和docker都已经安装,那么检查当前cuda以及nvidia驱动和docker的状态,cuda为:
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Sat_Aug_25_21:08:01_CDT_2018
Cuda compilation tools, release 10.0, V10.0.130
如果在安装时有选择cuda sample并且没有跑过其它程序,可以编译其路径下的deviceQuery:
$ cd /usr/local/cuda/samples/1_Utilities/deviceQuery
$ make
$ ./deviceQuery
如果是安装成功,会显示:
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Tesla T4"
CUDA Driver Version / Runtime Version 11.0 / 10.0
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 15110 MBytes (15843721216 bytes)
(40) Multiprocessors, ( 64) CUDA Cores/MP: 2560 CUDA Cores
GPU Max Clock rate: 1590 MHz (1.59 GHz)
Memory Clock rate: 5001 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 4194304 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 0 / 3
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.0, CUDA Runtime Version = 10.0, NumDevs = 1
Result = PASS
如果没有下载sample,python可以用torch里cuda的is_available(),而如果是C++,可以直接:cudaSetDevice()看有没有。上面环境预装里有cuda的测试,一般cuda失败日志为:
CUDA driver version is insufficient for CUDA runtime version
Result = Fail
这是由于cuda与当前驱动不一致导致,别问我为什么这个错误还记得这么清楚,因为是前几天在容器内刚出现的。。但我没有版本不一致,去Git上依照官方原话为:
I suspect you somehow ended up with CUDA runtime libraries installed into your image from a host machine that are a mismatch with the driver version running on your current host. How did you generate the submarineas/centos:v0.1 image?
You can’t do this. The image must run with the host CUDA libraries injected into it. This is one of the primary functionalities that nvidia-dockerprovides. To fix the situation, you need to go into /usr/lib/x86_64-linux-gnu/ inside your container and remove any files of the form *.so. (e.g. libnvidia-ml.so.410.104) that don’t match the driver version on your host.
docker状态查看为systemctl status docker.service:
Sep 08 21:37:02 iZwz9dnzb8iugujf36fuw9Z dockerd[2493]: time="2020-09-08T21:37:02.895532061+08:00" level=info msg="ccResolverWrapper: sending update ...ule=grpc
Sep 08 21:37:02 iZwz9dnzb8iugujf36fuw9Z dockerd[2493]: time="2020-09-08T21:37:02.895547307+08:00" level=info msg="ClientConn switching balancer to \...ule=grpc
Sep 08 21:37:02 iZwz9dnzb8iugujf36fuw9Z dockerd[2493]: time="2020-09-08T21:37:02.904539499+08:00" level=info msg="[graphdriver] using prior storage ...verlay2"
Sep 08 21:37:03 iZwz9dnzb8iugujf36fuw9Z dockerd[2493]: time="2020-09-08T21:37:03.235120765+08:00" level=info msg="Loading containers: start."
Sep 08 21:37:05 iZwz9dnzb8iugujf36fuw9Z dockerd[2493]: time="2020-09-08T21:37:05.503083212+08:00" level=info msg="Default bridge (docker0) is assign...address"
Sep 08 21:37:06 iZwz9dnzb8iugujf36fuw9Z dockerd[2493]: time="2020-09-08T21:37:06.347242198+08:00" level=info msg="Loading containers: done."
Sep 08 21:37:06 iZwz9dnzb8iugujf36fuw9Z dockerd[2493]: time="2020-09-08T21:37:06.507743081+08:00" level=info msg="Docker daemon" commit=633a0ea grap...=19.03.5
Sep 08 21:37:06 iZwz9dnzb8iugujf36fuw9Z dockerd[2493]: time="2020-09-08T21:37:06.507838124+08:00" level=info msg="Daemon has completed initialization"
Sep 08 21:37:06 iZwz9dnzb8iugujf36fuw9Z dockerd[2493]: time="2020-09-08T21:37:06.574231587+08:00" level=info msg="API listen on /var/run/docker.sock"
这里的错误也可能发生的是:
Sep 08 14:11:41 10-9-111-182 dockerd[1058]: time="2020-09-08T14:11:41.522856125+08:00" level=error msg="Handler for POST /v1.40/containers/a3d065de1ea9/restar>
Sep 08 15:57:46 10-9-111-182 dockerd[1058]: time="2020-09-08T15:57:46.154184854+08:00" level=error msg="stream copy error: reading from a closed fifo"
Sep 08 15:57:46 10-9-111-182 dockerd[1058]: time="2020-09-08T15:57:46.154205023+08:00" level=error msg="stream copy error: reading from a closed fifo"
这里也别问我为什么我会有这种东西,被各种垃圾的博客坑得不要不要的。。。如果docker有这种错误,说明之前有修改过daemon.json文件,并错误的进行了更新或删除,Docker daemon已经失效,所以需要重启docker即可。而如果是启动的容器出现这个日志,那么需要将端口以及数据卷全部换了重做即可。
最后是驱动的状态,这个一般不会出错,出错了自己先关机思考一下人生吧。
nvidia-docker安装
ubuntu:
curl https://get.docker.com | sh
sudo systemctl start docker && sudo systemctl enable docker
# 设置stable存储库和GPG密钥:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
# 要访问experimental诸如WSL上的CUDA或A100上的新MIG功能之类的功能,您可能需要将experimental分支添加到存储库列表中.
# 可加可不加
curl -s -L https://nvidia.github.io/nvidia-container-runtime/experimental/$distribution/nvidia-container-runtime.list | sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list
# nvidia-docker2更新软件包清单后,安装软件包(和依赖项):
sudo apt-get update
sudo apt-get install -y nvidia-docker2
# 设置默认运行时后,重新启动Docker守护程序以完成安装:
sudo systemctl restart docker
到此如果没有什么没问题,ubuntu的nvidia-docker就此安装成功,上述安装来自nvidia官方安装方式,但我开始是经手的centos,ubuntu才是nvidia的亲儿子系列,我百度了很久,也谷歌了半刻钟,可能谷歌的搜索方式不对,但百度绝对是个坑,大部分连抄官网的都没抄全,然后我以为nvidia没有写centos的,在nvidia官网找到了另一个链接,是nvidia-docker的散装系列:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.repo | \
sudo tee /etc/yum.repos.d/nvidia-container-runtime.repo
sudo yum-config-manager --enable libnvidia-container-experimental
sudo yum-config-manager --enable nvidia-container-experimental
sudo yum-config-manager --disable libnvidia-container-experimental
sudo yum-config-manager --disable nvidia-container-runtime-experimental
因为nvidia-docker就三个核心的东西,一个nvidia-container-runtime,一个libnvidia-container-experimental,还有一个cudakit. 但有官方文档最好还是照着官方来,两篇例子分别为:
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker
https://nvidia.github.io/nvidia-container-runtime/
nvidia-docker部署问题
我们可以运行nvidia给的测试镜像,这里需要区分的是nvidia-docker和nvidia-docker2,如果没有使用官方提供的安装方式,而是和我一样走的野路子,那么就要看看自己的docker到底是1还是2,那么启动方式略有不同的地方在于:
# nvidia-docker:nvidia-container-toolkit的安装方式
docker run --gpus=all --rm nvidia/cuda:10.0-base nvidia-smi
# nvidia-docker2
docker run --runtime=nvidia -e NVIDIA_VISIBLE_DEVICES=all --rm nvidia/cuda:10.0-base nvidia-smi
or
nvidia-docker run -e NVIDIA_VISIBLE_DEVICES=all --rm nvidia/cuda:10.0-base nvidia-smi
如果没有区分对,可以换着全跑一遍就知道了。就比如说我,zaicentos上跑完第一个就发现了错误:
could not select device driver “” with capabilities: [[gpu]].
这个问题在docker2上是不会发生的,根据issue 1034的其中一个贡献者原话为:
Hello!
If you didn’t already make sure you’ve installed the nvidia-container-toolkit.
If this doesn’t fix it for you, make sure you’ve restarted docker systemctl restart dockerd
nvidia-container-toolkit,同样在stackoverflow上有相同回答,因为缺少所以device找不到GPU地址。所以必须根据上面我提供的nvidia-container-的安装才能找到相应驱动:
ldcache error: open failed: /sbin/ldconfig.real: no such file or directory\\n\""": unknown.
这个错误我不知道是deepin系统独有的还是非主流服务器才会有,没错,这个错误我是发生在deepin上,别问我为什么前面还是ubuntu和centos,这里又deepin了。。。这真是一个悲伤的故事。还是在run的时候,爆出这个问题,前面会有一堆nvidia-docker-container的日志。
解决这个问题非常简单,只需要更新动态库配置文件和将它报错的路径链接过去:
sudo ldconfig -v # 显示所有链接
or
ldconfig # 不报错
ln -s /sbin/ldconfig /sbin/ldconfig.real
这里的一条是更新ldconfig,和source等同,-v显示所有的记录,如果ldconfig没用,那么需要加-v看看到底是那条的问题。
比如我在这个系统ldconfig后遇到的是libcudnn有问题,那么链接为:
sudo ln -sf /usr/local/cuda-10.0/targets/x86_64-linux/lib/libcudnn.so.7.4.2 /usr/local/cuda-10.0/targets/x86_64-linux/lib/libcudnn.so.7
而后将/sbin/ldconfig链接上再启动就不会报这个错了。
starting container process caused “exec: “nvidia-smi”: executable file not found in $PATH”
这个错误是很难处理的,我们一步步来。
首先根据语义,container没有找到路径,如果后面还跟了比如说cuda >= 的字样,那么就能确定是cuda版本不对,我们首先查看docker的volume:
$ nvidia-docker volume ls
DRIVER VOLUME NAME
local f32bc4d3933b47c923b0e3e86222e2476e7131566950daad756790bc4129626d
nvidia-docker nvidia_driver_450.51.06
如果没有nvidia-docker请手动创建一个volume:
docker volume create --driver=nvidia-docker --name=nvidia_driver_$(modinfo -F version nvidia)
创建完后如果是版本问题,升级版本,不是的话那么接着检查:
systemctl status docker.service # 查看docker日志
sudo systemctl start nvidia-docker.service # 查看nvidia-docker日志
docker日志为:
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/docker.service.d
└─override.conf
Active: active (running) since Tue 2020-09-08 11:09:10 CST; 7min ago
Docs: https://docs.docker.com
Main PID: 30459 (dockerd)
Tasks: 40
Memory: 66.7M
CGroup: /system.slice/docker.service
├─30459 /usr/bin/dockerd --host=fd:// --add-runtime=nvidia=/usr/bin/nvidia-container-runtime
├─30610 /usr/bin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 3306 -container-ip 172.18.0.2 -container-port 3306
├─30672 /usr/bin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 15672 -container-ip 172.18.0.4 -container-port 15672
└─30688 /usr/bin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 5672 -container-ip 172.18.0.4 -container-port 5672
Sep 08 11:09:09 10-9-111-182 dockerd[30459]: time="2020-09-08T11:09:09.703146487+08:00" level=info msg="Loading containers: start."
Sep 08 11:09:09 10-9-111-182 dockerd[30459]: time="2020-09-08T11:09:09.817109186+08:00" level=info msg="Default bridge (docker0) is assigned with an IP address 172.17.0.0/16. Daemon option --
nvidia-docker日志类似,如果看到有问题,那么就根据问题找资料,为什么会出现,因为这个牵涉的地方很多,如果两个状态都没有问题,那么接着查找。
$ yum search libcuda
"""
Repository libnvidia-container is listed more than once in the configuration
Repository libnvidia-container-experimental is listed more than once in the configuration
Repository nvidia-container-runtime is listed more than once in the configuration
Repository nvidia-container-runtime-experimental is listed more than once in the configuration
Last metadata expiration check: 0:14:56 ago on Tue 08 Sep 2020 01:50:04 PM CST.
No matches found.
"""
libcuda没有问题,三个nvidia-docker的环境。
nvidia-container-cli -k -d /dev/tty info
"""
-- WARNING, the following logs are for debugging purposes only --
I0908 06:06:06.277294 106114 nvc.c:282] initializing library context (version=1.3.0, build=af0220ff5c503d9ac6a1b5a491918229edbb37a4)
I0908 06:06:06.277332 106114 nvc.c:256] using root /
I0908 06:06:06.277337 106114 nvc.c:257] using ldcache /etc/ld.so.cache
I0908 06:06:06.277341 106114 nvc.c:258] using unprivileged user 65534:65534
I0908 06:06:06.277362 106114 nvc.c:299] attempting to load dxcore to see if we are running under Windows Subsystem for Linux (WSL)
I0908 06:06:06.277498 106114 nvc.c:301] dxcore initialization failed, continuing assuming a non-WSL environment
I0908 06:06:06.278499 106115 nvc.c:192] loading kernel module nvidia
I0908 06:06:06.278650 106115 nvc.c:204] loading kernel module nvidia_uvm
I0908 06:06:06.278713 106115 nvc.c:212] loading kernel module nvidia_modeset
.......
CUDA version: 11.0
Device Index: 0
Device Minor: 0
Model: Tesla T4
Brand: Tesla
GPU UUID: GPU-8546d1d2-7f12-2014-2498-6738e7ac1d2b
Bus Location: 00000000:00:03.0
Architecture: 7.5
I0908 08:22:40.155167 15854 nvc.c:337] shutting down library context
I0908 08:22:40.223031 15856 driver.c:156] terminating driver service
I0908 08:22:40.223527 15854 driver.c:196] driver service terminated successfully
"""
这里有一个问题是dxcore initialization failed, continuing assuming a non-WSL environment,但我没有用过win的东西,可能跟libnvidia-container-experimental有关,如果看过前面那篇nvidia-container-time的文章,那yum search libcuda搜索下或者apt-get搜索下是有的,就不用管这个问题了。
如果还是有问题,请运行:
nvidia-docker run --rm nvidia/cuda:10.0-devel "echo $PATH"
nvidia-docker通过依赖找到的所有路径都会显示出来,如果没有请加上去,或者手动添加该目录。然后最后我遇到了另一个问题:

这个问题暂时无果,询问nvidia官方人员,那边暂时也没处管我,如果你出现了跟我一样的错误,如果解决了请在评论区或者私信我,感激不尽。如果没解决,那只能恭喜你。。。解决了。