flume+kafka+storm+mysql架构设计
感谢大家的关注,从写这篇博客到现在经过不少时间了。
最近重新回顾storm发现改动还是挺多的。
我重新整理的篇最新版的安装笔记:点击打开链接
版本:
序言
前段时间学习了storm,最近刚开blog,就把这些资料放上来供大家参考。
这个框架用的组件基本都是最新稳定版本,flume-ng1.4+kafka0.8+storm0.9+mysql
如果有需要测试项目代码的朋友,留下邮箱。
(项目是maven项目,需要改动mysql配置,提供两种topology:读取本地文件(用来本地测试);读取服务器日志文件。)
架构图
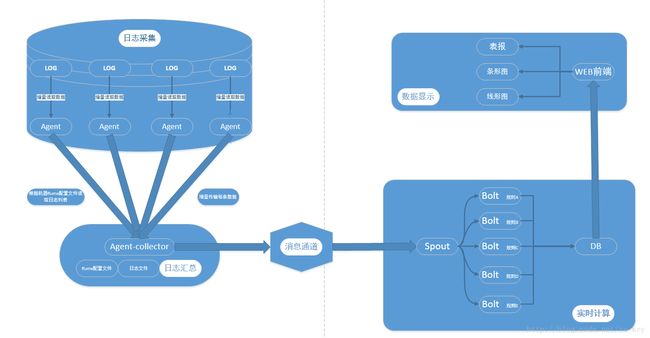
数据流向图
(是visio画的,图太大,放上来字看起来比较小,如果有需要的朋友留邮箱)
实时日志分析系统架构简介
系统主要分为四部分:
![]()
1).数据采集
负责从各节点上实时采集数据,选用cloudera的flume来实现
2).数据接入
由于采集数据的速度和数据处理的速度不一定同步,因此添加一个消息中间件来作为缓冲,选用apache的kafka
3).流式计算
对采集到的数据进行实时分析,选用apache的storm
4).数据输出
对分析后的结果持久化,暂定用mysql
详细介绍各个组件及安装配置:
操作系统:centos6.4
Flume
Flume是Cloudera提供的一个分布式、可靠、和高可用的海量日志采集、聚合和传输的日志收集系统,支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
下图为flume典型的体系结构:

Flume数据源以及输出方式:
Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力,在我们的系统中目前使用exec方式进行日志采集。
Flume的数据接受方,可以是console(控制台)、text(文件)、dfs(HDFS文件)、RPC(Thrift-RPC)和syslogTCP(TCP syslog日志系统)等。在我们系统中由kafka来接收。
Flume版本:1.4.0
Flume下载及文档:
http://flume.apache.org/
Flume安装:
$tar zxvf apache-flume-1.4.0-bin.tar.gz /usr/local
Flume启动命令:
$bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name producer -Dflume.root.logger=INFO,console
注意事项:需要更改conf目录下的配置文件,并且添加jar包到lib目录下。
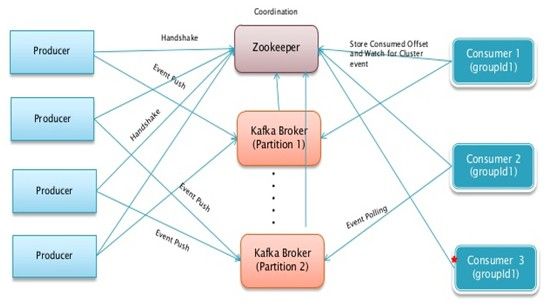
Kafka
Kafka是一个消息中间件,它的特点是:
1、关注大吞吐量,而不是别的特性
2、针对实时性场景
3、关于消息被处理的状态是在consumer端维护,而不是由kafka server端维护。
4、分布式,producer、broker和consumer都分布于多台机器上。
下图为kafka的架构图:
Kafka版本:0.8.0
Kafka下载及文档:http://kafka.apache.org/
Kafka安装:
> tar xzf kafka-
> cd kafka-
> ./sbt update
> ./sbt package
> ./sbt assembly-package-dependency Kafka
启动及测试命令:
(1) start server
> bin/zookeeper-server-start.sh config/zookeeper.properties
> bin/kafka-server-start.sh config/server.properties
(2)Create a topic
> bin/kafka-create-topic.sh --zookeeper localhost:2181 --replica 1 --partition 1 --topic test
> bin/kafka-list-topic.sh --zookeeper localhost:2181
(3)Send some messages
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
(4)Start a consumer
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
storm
Storm是一个分布式的、高容错的实时计算系统。
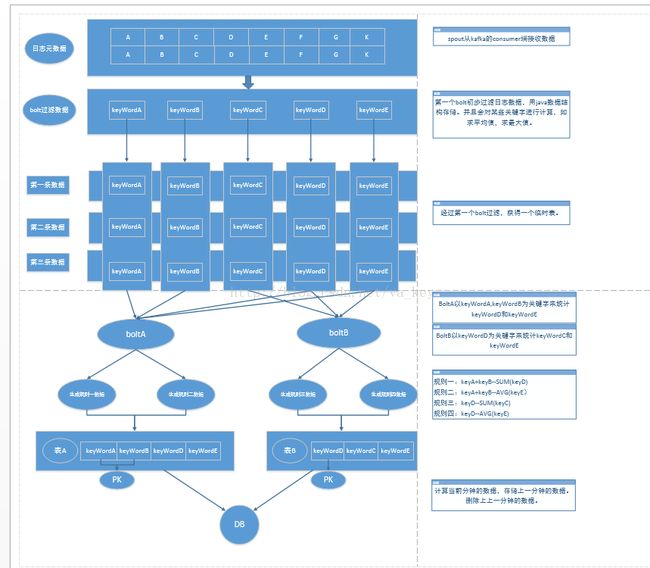
Storm架构图:

storm工作任务topology:

Storm 版本:0.9.0
Storm 下载:http://storm-project.net/
Storm安装:
第一步,安装Python2.7.2
# wget http://www.python.org/ftp/python/2.7.2/Python-2.7.2.tgz
# tar zxvf Python-2.7.2.tgz
# cd Python-2.7.2
# ./configure
# make
# make install
# vi /etc/ld.so.conf
第二步,安装zookeeper(kafka自带zookeeper,如果选用kafka的,该步可省略)
#wget http://ftp.meisei-u.ac.jp/mirror/apache/dist//zookeeper/zookeeper-3.3.3/zoo keeper-3.3.3.tar.gz
# tar zxf zookeeper-3.3.3.tar.gz
# ln -s /usr/local/zookeeper-3.3.3/ /usr/local/zookeeper
# vi ~./bashrc (设置ZOOKEEPER_HOME和ZOOKEEPER_HOME/bin)
第三步,安装JAVA
$tar zxvf jdk-7u45-linux-x64.tar.gz /usr/local
如果使用storm0.9以下版本需要安装zeromq及jzmq。
第四步,安装zeromq以及jzmq
jzmq的安装貌似是依赖zeromq的,所以应该先装zeromq,再装jzmq。
1)安装zeromq(非必须):
- # wget http://download.zeromq.org/historic/zeromq-2.1.7.tar.gz
- # tar zxf zeromq-2.1.7.tar.gz
- # cd zeromq-2.1.7
- # ./configure
- # make
- # make install
- # sudo ldconfig (更新LD_LIBRARY_PATH)
之后遇到的问题是:Error:cannot link with -luuid, install uuid-dev
这是因为没有安装uuid相关的package。
解决方法是:# yum install uuid*
# yum install e2fsprogs*
# yum install libuuid*
2)安装jzmq(非必须)
- # yum install git
- # git clone git://github.com/nathanmarz/jzmq.git
- # cd jzmq
- # ./autogen.sh
- # ./configure
- # make
- # make install
然后,jzmq就装好了,这里有个网站上参考到的问题没有遇见,遇见的童鞋可以参考下。在./autogen.sh这步如果报错:autogen.sh:error:could not find libtool is required to run autogen.sh,这是因为缺少了libtool,可以用#yum install libtool*来解决。
如果安装的是storm0.9及以上版本不需要安装zeromq和jzmq,但是需要修改storm.yaml来指定消息传输为netty:
storm.local.dir: "/tmp/storm/data"
storm.messaging.transport: "backtype.storm.messaging.netty.Context"storm.messaging.netty.server_worker_threads: 1storm.messaging.netty.client_worker_threads: 1storm.messaging.netty.buffer_size: 5242880storm.messaging.netty.max_retries: 100storm.messaging.netty.max_wait_ms: 1000storm.messaging.netty.min_wait_ms: 100
第五步,安装storm
$unzip storm-0.9.0-wip16.zip
备注:单机版不需要修改配置文件,分布式在修改配置文件时要注意:冒号后必须加空格。
测试storm是否安装成功:
1. 下载strom starter的代码 git clone https://github.com/nathanmarz/storm-starter.git
2. 使用mvn -f m2-pom.xml package 进行编译
如果没有安装过maven,参见如下步骤安装:
1.从maven的官网下载http://maven.apache.org/
tar zxvf apache-maven-3.1.1-bin.tar.gz /usr/local
配置maven环境变量
export MAVEN_HOME=/usr/local/maven
export PATH=$PATH:$MAVEN_HOME/bin
验证maven是否安装成功:mvn -v
修改Storm-Starter的pom文件m2-pom.xml ,修改dependency中twitter4j-core 和 twitter4j-stream两个包的依赖版本,如下:
org.twitter4j
twitter4j-core
[2.2,)
org.twitter4j
twitter4j-stream
[2.2,)
编译完后生成target文件夹
启动zookeeper
zkServer.sh start
启动nimbus supervisor ui
storm nimbus
storm supervisor
storm ui
jps查看启动状态
进入target目录执行:
storm jar storm-starter-0.0.1-SNAPSHOT-jar-with-dependencies.jar storm.starter.WordCountTopology wordcountTop
然后查看http://localhost:8080
注释:单机版 不用修改storm.yaml
kafka和storm整合
1.下载kafka-storm0.8插件:https://github.com/wurstmeister/storm-kafka-0.8-plus
2.该项目下载下来需要调试下,找到依赖jar包。然后重新打包,作为我们的storm项目的jar包。
3.将该jar包及kafka_2.9.2-0.8.0-beta1.jar metrics-core-2.2.0.jar scala-library-2.9.2.jar (这三个jar包在kafka-storm-0.8-plus项目依赖中能找到)
备注:如果开发的项目需要其他jar,记得也要放进storm的Lib中比如用到了mysql就要添加mysql-connector-java-5.1.22-bin.jar到storm的lib下
flume和kafka整合
1.下载flume-kafka-plus: https://github.com/beyondj2ee/flumeng-kafka-plugin
2.提取插件中的flume-conf.properties文件
修改该文件:#source section
producer.sources.s.type = exec
producer.sources.s.command = tail -f -n+1 /mnt/hgfs/vmshare/test.log
producer.sources.s.channels = c
修改所有topic的值改为test
将改后的配置文件放进flume/conf目录下
在该项目中提取以下jar包放入环境中flume的lib下:

以上为单机版的flume+kafka+storm的配置安装
flume+storm插件
https://github.com/xiaochawan/edw-Storm-Flume-Connectors
启动步骤
将编写好的storm项目打成jar包放入服务器上,假如放在/usr/local/project/storm.xx.jar
bin/zookeeper-server-start.sh config/zookeeper.properties
第三步
启动kafka
cd /usr/local/kafka
> bin/kafka-server-start.sh config/server.properties
创建主题
> bin/kafka-create-topic.sh --zookeeper localhost:2181 --replica 1 --partition 1 --topic test
注:因为kafka消息的offset是由zookeeper记录管理的,所以在此需指定zookeeper的ip,replica 表示该主题的消息被复制几份,partition 表示每份主题被分割成几部分。test表示主题名称。
第四步
启动storm
> storm nimbus
> storm supervisor
> storm ui
cd /usr/local/project/
> storm jar storm.xx.jar storm.testTopology test
注:storm.xx.jar 为我们编写好的storm项目jar包,第一步完成的工作。 storm.testTopology 为storm项目中main方法所在的类路径。test为此次topology的名字。
第五步
启动flume
cd /usr/local/flume
bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name producer
注:flume.conf.properties为我们自定义的flume配置文件,flume安装好后是没有此文件的,需要我们自己编写,编写方式见flume安装的文章。
至此需要启动的程序已经全部启动,storm项目已经开始运行,可以打开storm ui 观察运行是否正常。
http://localhost:8080
注:此处ip为storm nimbus所在机器Ip 端口可在storm配置文件 storm/conf/storm.yaml中修改