爬虫入门之分布式爬虫
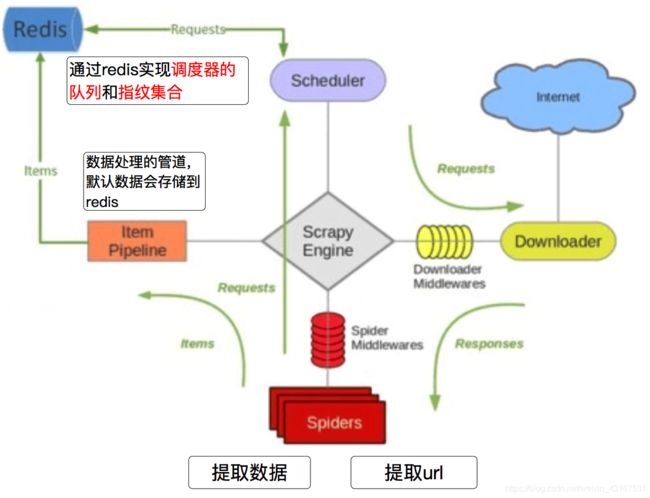
scrapy_redis
- Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:reqeust去重,爬虫持久化,和轻松实现分布式
- 安装
pip3 install scrapy-redis
3.要使用分布式 Scrapy_Redis Settings.py设置文件中需要做一下配置
这里表示启用scrapy-redis里的去重组件,不实用scrapy默认的去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
使用了scrapy-redis里面的调度器组件,不使用scrapy默认的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
允许暂停,redis请求的记录不会丢失,不清除Redis队列,可以恢复和暂停
SCHEDULER_PERSIST = True
下面这些是request的队列模式
scrapy-redis默认的请求队列形式(有自己的优先级顺序)
是按照redis的有序集合排序出队列的
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
队列形式,请求先进先出
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
使用了栈的形式,请求先进后出
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300, 'scrapy_redis.pipelines.RedisPipeline': 400,
}
指定要存储的redis的主机的ip,默认存储在127.0.0.1
REDIS_HOST = 'redis的主机的ip'
定要存储的redis的主机的port,默认6379
REDIS_PORT = '6379'
导入 from scrapy_redis.spiders import RedisCrawlSpider
这个RedisCrawlSpider类爬虫继承了RedisCrawlSpider,能够支持分布式的抓取。
因为采用的是crawlSpider,所以需要遵守Rule规则,
以及callback不能写parse()方法。
同样也不再有start_urls了,取而代之的是redis_key,
scrapy-redis将key从Redis里pop出来,成为请求的url地址。
注意:
同样的,RedisCrawlSpider类不需要写start_urls:
- scrapy-redis 一般直接写allowd_domains来指定需要爬取的域,也可以从在构造方法__init__()里动态定义爬虫爬取域范围(一般不用)。
- 必须指定redis_key,即启动爬虫的命令,参考格式:redis_key = ‘myspider:start_urls’
- 根据指定的格式,start_urls将在 Master端的 redis-cli 里 lpush 到 Redis数据库里,RedisSpider 将在数据库里获取start_urls。
执行方式
1.通过runspider方法执行爬虫的py文件(也可以分次执行多条),爬虫(们)将处于等待准备状态:
scrapy runspider myspider_redis.py
或者
scrapy crawl myspider_redis
2 .在Master端的redis-cli输入push指令,参考格式(指定起始url):
lpush myspider:start_urls http://www.dmoz.org/
3.Slaver端爬虫获取到请求,开始爬取。
scrapy和scrapy-redis有什么区别?为什么选择redis数据库?
1) scrapy是一个Python爬虫框架,爬取效率极高,具有高度定制性,但是不支持分布式。而scrapy-redis一套基于redis数据库、运行在scrapy框架之上的组件,可以让scrapy支持分布式策略,Slaver端共享Master端redis数据库里的item队列、请求队列和请求指 纹集合。
2) 为什么选择redis数据库,因为redis支持主从同步,而且数据都是缓存在内存中的,所以基于redis的分布式爬虫,对请求和数据的高频读取效率非常高。