集合视图源码解析
骨架实现
在介绍视图之前,首先应该知道,集合框架内每个重要的接口都有一个对应的骨架(抽象类)实现。List -> AbstractList -> AbstractSequentialList, Map -> AbstractMap,Set ->AbstractSet,Collection ->AbstractCollection,Queue -> AbstractQueue, 骨架都是继承各自对应的接口,并且实现了一些通用的方法.
下面是它们之间的继承关系: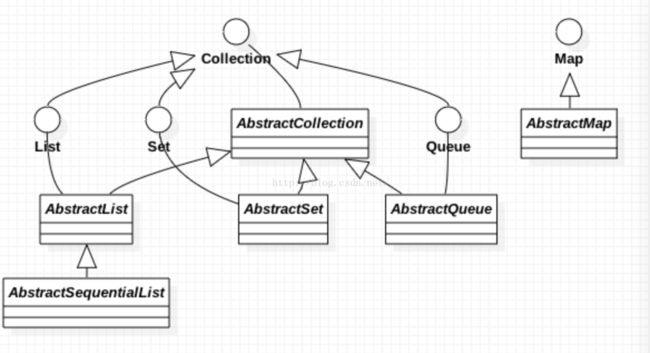
对于List,我做下解释,它有两个骨架实现,
AbstractList
- 最大限度地减少了实现由“随机访问”数据存储(如数组)支持的接口所需的工作。
- 要实现不可修改的列表,程序员只需扩展此类,并提供 get(int index) 和 size() 方法的实现。(后面会有实现)
- 要实现可修改的列表,程序员还必须另外重写 set(int index,Object element) 方法,否则将抛出 UnsupportedOperationException。如果列表为可变大小,则程序员必须另外重写 add(int index,Object element) 和 remove(int index) 方法。
AbstractSequentialList
- 最大限度地减少了实现受“连续访问”数据存储(如链接列表)支持的此接口所需的工作
- 要实现一个列表,程序员只需要扩展此类,并提供 listIterator 和 size 方法的实现。对于不可修改的列表,程序员只需要实现列表迭代器的 hasNext、next、hasPrevious、previous 和 index 方法即可。
- 对于可修改的列表,程序员应该再另外实现列表迭代器的 set 方法。对于可变大小的列表,程序员应该再另外实现列表迭代器的 remove 和 add 方法。
提供骨架实现有以下好处,所以在我们自己提供重要接口时,也应该提供相似的骨架实现:
- 程序员可以很容易的提供自己的接口实现,为了性能,或者便利性
- 便于扩展接口定义。(因为接口一旦发布,就几乎不能更改)
例如,下面的代码实现了一个不可修改,不能改变大小的list。一旦调用set,add,remove方法,会抛出UnsupportedOperationException。
class ArrayList extends java.util.AbstractList {
private final String[] s;
ArrayList(String[] array) {
s = Objects.requireNonNull(array);
}
@Override
public String get(int index) {
if (index >= s.length)
throw new IndexOutOfBoundsException("");
return s[index];
}
@Override
public int size() {
return s.length;
}
} 集合视图
现在我们了解了骨架实现,再来看看集合视图。 视图是实现了Collection 或者 Map 接口的轻量级对象。视图内部不存储数据,它只是有一个引用,指向集合,数组或者其它对象。首先我们来看一段代码: public static void main(String[] args) {
String[] a = new String[] { "a", "b", "c" };
List list = Arrays.asList(a);
System.out.println("first = "+list.get(0));
list.add("d");// throw UnsupportedOperationException
} 有经验的程序员一看就知道list.add("d")会抛出异常。因为Arrays.asList方法返回了一个视图对象,这个视图只能使用get,set访问数据,任何尝试改变数组大小的方法都会抛UnsupportedOperationException
。但是为什么呢 ?
Arrays.asList是一个静态方法,按理说它会返回一个继承自List接口的对象。而这个对象应该能够执行所有List接口的方法。我们看下源码:
(此处只显示重要的方法实现,省略了部分方法和部分方法的实现,这些方法和实现对于完整的程序来说是重要的)
public static List asList(T... a) {
return new ArrayList<>(a);
}
private static class ArrayList extends AbstractList
implements RandomAccess, java.io.Serializable
{
private final E[] a;
ArrayList(E[] array) {
a = Objects.requireNonNull(array);
}
@Override
public int size() {
return a.length;
}
@Override
public E get(int index) {
return a[index];
}
@Override
public E set(int index, E element) {
E oldValue = a[index];
a[index] = element;
return oldValue;
}
......
} 从上面源码,我们可以看出,当我们调用Array.asList方法时,它会返回一个内部私有类ArrayList的对象。这个类恰好继承自List接口的骨架实现AbstractList,并且它是可随机访问的。
这个类实现了get,set,size方法,但是没有实现add,romove方法,所以它返回的对象只能访问和更改数据,不能改变数组的大小。
这就是集合框架生成视图的通用方法。
再来看一个复杂一点的例子(此处省略了print方法):
public static void main(String[] args) {
Map fruits = new HashMap<>();
fruits.put(1, "apple");
fruits.put(2, "banana");
fruits.put(3, "orange");
Set ids = fruits.keySet();// 生成key视图
fruits.remove(1);// 在集合中移除一个元素
printSet(ids);// output 2,3
ids.remove(2);//在视图中移除一个元素
printMap(fruits);//output 3,orange
} 从以上代码,可以看出,当我们操作集合时,视图会发生相应变化,当我们操作视图时,集合也会发生相应变化 为什么呢?
按理说,keySet()方法返回一个set类型的对象,而set类型我们知道它内部是使用map来存储数据的,不应该对集合产生影响。我们看下源码(我只截取相关的一部分):
transient volatile Set keySet;
public Set keySet() {
Set ks;
return (ks = keySet) == null ? (keySet = new KeySet()) : ks;
}
final class KeySet extends AbstractSet {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator iterator() { return new KeyIterator(); }
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator spliterator() {
return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer action) {
Node[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
} 从源码可以看出,当调用keySet方法时,它会返回一个内部类KeySet的对象。这个类恰好继承自Set接口的骨架实现AbstractSet,它没有实现add方法,所以我们只能对这个set视图做查询或者移除操作
一旦调用add操作,会抛出UnsupportedOperationException。(上面还实现了forEach方法,这是jdk1.8新加入的功能,还有功能函数Consumer,这些以后会讲到)视图和集合联动
首先声明了一个Set
既然保存起来了,为什么它里面的数据还能随着集合的增减操作而动态变化呢?
因为这个对象它操纵的就是它的外部类HashMap的对象数据,相当于它保存着外部对象的引用,每次调用都会将操作传递给外部的HashMap来执行。调用size方法,它返回的是外部类HashMap的size,调用iterator,它迭代的也是HashMap的数据,还有remove,同样调用的是HashMap的removeNode。所以说它们之间能保持联动。
为了说明实现的普遍性,我们可以再看一个例子。我们知道Collections这个类,有大量的视图操作。来看一看大家熟悉的SynchronizedMap。我们都知道它在同步实现上比较低效,为什么呢?
(为了更简洁的说明问题,我只截取少量代码)
public static Map synchronizedMap(Map m) {
return new SynchronizedMap<>(m);
}
private static class SynchronizedMap
implements Map, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map m; // Backing Map
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map m) {
this.m = Objects.requireNonNull(m);
mutex = this;
}
SynchronizedMap(Map m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
public int size() {
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
......
} 这个结构是不是和上面很相似。还是生成内部类的对象,然后实现自己的操作。有不同的是,这里内部类继承的是Map
视图,而是在Map
内部类SynchronizedMap,维持了一个传入Map的引用,这和我们刚才分析的HashMap的KeySet视图如出一辙,只是引用的方式变了而已。它还维持了一个同步对象mutex,在调用每个Map方法的时
候,加上synchronized (mutex) 的同步控制,然后再将方法传递给真正有数据的Map进行操作,这样就是在执行有数据的Map之前,必须先获取到同步对象mutex的锁,由于每个对象只有一把锁,所以同时只
能执行Map的其中一个操作,这样就实现了同步,但是这样是低效的,当然有更高效的实现ConcurrentMap(这个以后会讲到)。
结论:
- 集合视图的实现基本都是通过内部类实现相应的骨架来实现的,并且如果是工具类,传入的数据和生成的视图之间联动,如果是集合类,集合的数据和生成的视图之间联动。
- 我们自己写的重要的公用接口都应该提供相应的骨架实现。
-
如果在集合上我们需要实现特殊的功能,例如:统计加入集合的所有数据的总量,或者统计某个域的最大值,或者其它情况需要对集合操作进行限制等,抑或是发现了性能更好的实现,这些都可以通过继承相应的抽象类来实现。
声明一下:我现在以及以后分析的源码,没有特殊说明,都是基于Oracle_JDK_1.8.0_45。我打算介绍一下Collection框架,java内存,垃圾回收机制,线程池,以及一些新特性。