引言
目前在 Java 中,解析 HTML 工具主要包含以下几种:
jsoup:强大的 HTML 解析工具,支持以 jQuery 中 CSS Selector 的方式提取 HTML 中的元素,学习成本较低。
HtmlCleaner:另外一款开源的 Java 语言的 HTML 文档解析器,支持以 XPath 的方式提取 HTML 中的元素。另外,在此说明,学习 XPath 语法对于使用另外一款基于 Selenium 的爬虫工具特别有帮助。
Htmlparser:对 HTML 进行有效信息搜索和提取的一款 Java 工具,但该工具已长时间不维护了(上次更新时间为2011年)。
我在前面的篇章中,已介绍了 jsoup 工具解析 HTML 的内容,因此,在本文将主要介绍 HtmlCleaner 和 HtmlParser 工具对 HTML 的解析。
针对 XML 数据,Java 也有很多工具进行解析,本文主要介绍 jsoup 解析 XML。
HtmlCleaner 解析 HTML
HtmlCleaner 下载
在 MVNRepository 中搜索 HtmlCleaner。并使用 Eclipse 或其他工具构建 Maven 工程,使用 Maven 工程中的 pom.xml 下载 HtmlCleaner 相关依赖 Jar 包。本篇以最新版 HtmlCleaner 配置为例:
net.sourceforge.htmlcleaner
htmlcleaner
2.22
Xpath 语法
XPath 是一门在 XML 文档中查找信息的语言,其可用来在 XML 文档中对元素和属性进行遍历。在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)。其在 HTML 解析中,主要是对节点进行选取,而在选取的过程中,需要路径进行定位。
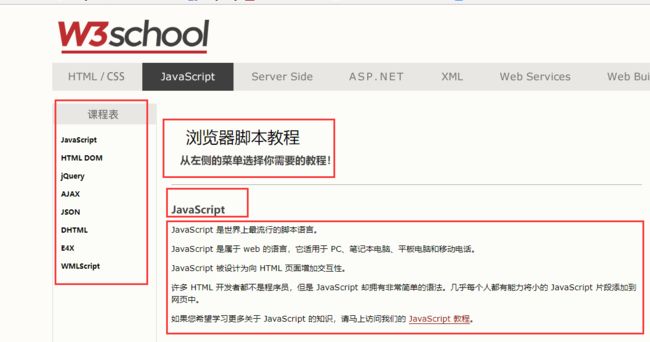
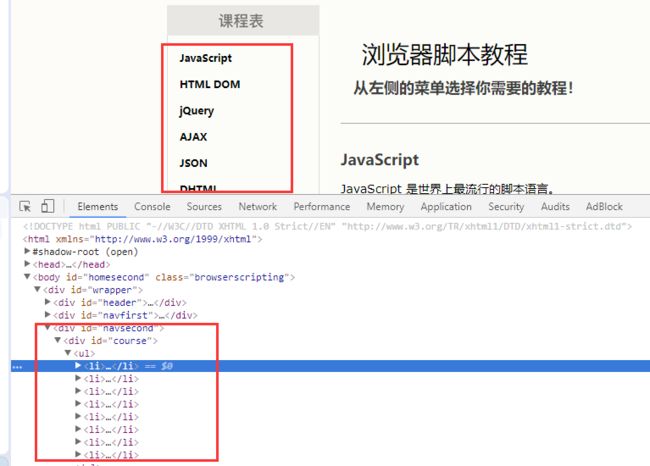
在此仍以前面章节讲到的 w3school 网页的 HTML 为例(http://www.w3school.com.cn/b.asp),限于本文的篇幅,以下是经过我整理后的部分网页内容:
浏览器脚本教程
JavaScript
JavaScript 是世界上最流行的脚本语言。
JavaScript 是属于 web 的语言,它适用于 PC、笔记本电脑、平板电脑和移动电话。
JavaScript 被设计为向 HTML 页面增加交互性。
许多 HTML 开发者都不是程序员,但是 JavaScript 却拥有非常简单的语法。几乎每个人都有能力将小的 JavaScript 片段添加到网页中。
如果您希望学习更多关于 JavaScript 的知识,请马上访问我们的
JavaScript 教程 。
HTML DOM
HTML DOM 定义了访问和操作 HTML 文档的标准方法。
DOM 以树结构表达 HTML 文档。
开始学习 HTML DOM !
下表是 Xpath 的常用语法,案例对应上面的 HTML 文档。
表达式
描述
实例
结果
nodename
选取此节点的所有子节点
body
选取 body 元素的所有子节点。
/
从根元素选取
/html
选取根元素 HTML。
//
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
//div
选取所有 div 元素,而不管它们在文档的位置。
.
选取当前节点
./p
选取当前节点下的 p 节点。
..
选取当前节点的父节点
../p
选取当前节点的父节点下的 title。
@
选取属性
//a[@href]
选取所有拥有名为 href 的属性的 a 元素。
@
选取属性
//div [@id='course']
选取所有 id 属性为 course 的 div 节点。
//div[@id='w3school']/h1
选取所有 id 属性为 w3school 的 div 节点下的 h1 节点。
//body/a[1]
选取属于 body 子元素的第一个 a 元素。
//body//a[last()]
选取属于 body 子元素的最后一个 a 元素。
定位一个节点可以使用多种写法,例如上面的 HTML,选取所有 id 属性为 w3school 的 div 节点下的 h1 节点,可以使用以下几种 Xpath 定位。
//div[@id='w3school']//h1
//div[@id='w3school']/h1
//*[@id='w3school']/h1
另外在浏览器中,可以在审查(元素)中,定位我们需要采集的数据,右键之后点击 copy -> copy xpath,获取相应的 Xpath 写法。
解析 HTML
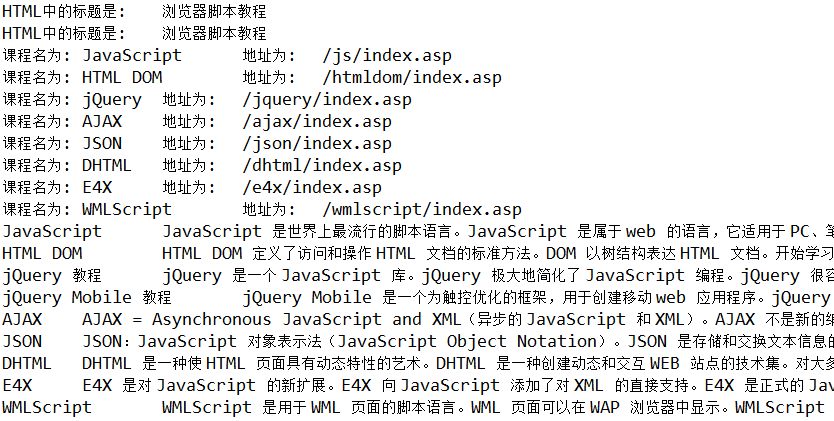
使用 HtmlCleaner 首先要对其进行初始化,初始化之后,我们便可以使用 Xpath 语法操作节点。以下为 w3school 页面的解析案例。解析的内容如下:
对应的程序为:
//这里笔者使用jsoup获取html文件
Document doc = Jsoup.connect("http://www.w3school.com.cn/b.asp").timeout(5000).get(); /
String html =doc.html(); //转化成String格式
//使用Htmlcleaner解析数据
HtmlCleaner cleaner = new HtmlCleaner(); //初始化对象
//System.out.println(html);
TagNode node = cleaner.clean(html); //解析HTML文件
//通过Xpath定位标题的位置,这里使用//h1和/h1的结果是一样的
Object[] ns = node.evaluateXPath("//div[@id='w3school']//h1");
System.out.println("HTML中的标题是:\t" + ((TagNode)ns[0]).getText());
Object[] ns1 = node.evaluateXPath("//*[@id='w3school']/h1");
System.out.println("HTML中的标题是:\t" + ((TagNode)ns1[0]).getText());
//遍历获取课程名以及课程地址
Object[] ns2 = node.evaluateXPath("//*[@id='course']/ul//a"); //这里使用//a表示不考虑位置,如果使用/a获取不到内容
for(Object on : ns2) {
TagNode n = (TagNode) on;
System.out.println("课程名为:\t" + n.getText() + "\t地址为:\t" + n.getAttributeByName("href"));
}
//获取每个课程名称以及其对应的简介
Object[] ns3 = node.evaluateXPath("//*[@id='maincontent']//div");
for (int i = 1; i < ns3.length; i++) {
TagNode n = (TagNode) ns3[i];
//获取课程名称
String courseName = n.findElementByName("h2", true).getText().toString();
//循环遍历所有的p节点获取课程简介
Object[] objarrtr = n.evaluateXPath("//p");
String summary = "";
for(Object on : objarrtr) {
summary += ((TagNode) on).getText().toString();
}
System.out.println(courseName + "\t" + summary);
}
在使用 evaluateXPath(String xPathExpression) 操作 TagNode 时得到的是 Object[] 数组,通过对该数组的操作便能够获取数据。另外,HtmlCleaner 还提供了很多种用法,例如上述程序中的 findElementByName()、getAttributeByName() 等操作方法,感兴趣的读者可以学习官方文档。利用上述程序解析得到的结果,如下图所示:
HtmlParser 解析 HTML
HtmlParser 下载
依旧采用 Maven 工程中的 pom.xml 下载 HtmlParser 相关依赖 Jar 包,配置如下:
org.htmlparser
htmlparser
2.1
工具使用介绍
HTMLParser 的核心模块是 Parser 类,在实际的应用中也是通过该类分析 HTML 文件。该类中常用的构造方法总结如下:
方法
说明
Parser()
无参数构造。
Parser(Lexer lexer)
通过 Lexer 构造 Parser,在案例程序中我会使用到。
Parser(String resource)
给定一个 URL 或文件资源,构造 Parser。
Parser(URLConnection connection)
使用 URLConnection 构造 Parser。
对大多数使用这来说,可以通过 URLConnection 或者通过其他工具获取的 HTML 字符串来初始化 Parser。HTMLParser 将解析过的信息保存为树结构,其中重要的是 Node 数据类型。Node 中包含的方法有对树结构操作的函数以及获取 Node 节点中包含内容的函数。
方法
说明
NodeList getChildren()
取得子节点的列表
Node getParent ()
取得父节点
Node getFirstChild ()
取得第一个子节点
Node getLastChild ()
取得最后一个子节点
Node getPreviousSibling ()
取得上一个兄弟节点
Node getNextSibling ()
取得下一个兄弟节点
String getText ()
获取节点中的文本
String toPlainTextString()
获取纯文本信息
String toHtml ()
返回该节点对应的 HTML
Page getPage ()
取得这个 Node 对应的 Page 对象
int getStartPosition ()
取得这个 Node 在 HTML 页面中的起始位置
int getEndPosition ()
取得这个 Node 在 HTML 页面中的结束位置
同时在 HTMLParser 提供了 Filter 操作,即对结果进行过滤。常用的过滤器有:
过滤器
说明
TagNameFilter
根据 Tag 的名字进行过滤。
HasChildFilter
返回有符合条件的子节点的节点,需要另外一个 Filter 作为过滤子节点的参数。
HasAttributeFilter
匹配出包含指定名称的属性,或者指定属性的节点。
StringFilter
过滤显示字符串中包含指定内容的标签节点。
RegexFilter
正则表达式匹配节点。
NodeClassFilter
根据已定义的标签类获取节点。
LinkStringFilter
判断链接中是否包含某个特定的字符串,可以用来过滤出指向某个特定网站的链接。
OrFilter
是结合几种过滤条件的“或”过滤器。
AndFilter
结合几种过滤条件的“与”过滤器。
使用案例
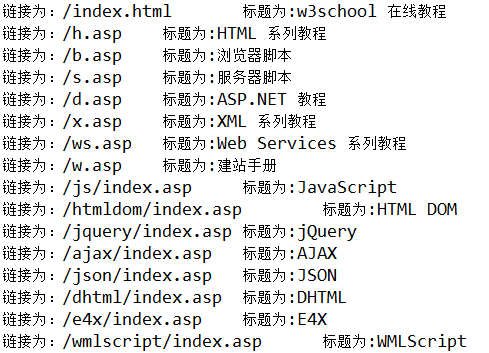
首先我给出第一个使用案例。给定 HTML 字符串,使用 Parser(Lexer lexer) 构造,结合过滤器的使用提取网页中的所有链接(即 href 对应的内容以及链接对应的标题),仍以上面的 w3school 的页面为案例(http://www.w3school.com.cn/b.asp)。如下程序:
//这里笔者使用Jsoup获取html文件
Document doc = Jsoup.connect("http://www.w3school.com.cn/b.asp").timeout(5000).get();
String html =doc.html(); //转化成String格式
//使用Lexer构造
Lexer lexer = new Lexer(html);
Parser parser = new Parser(lexer);
//过滤页面中的链接标签
NodeFilter filter = new NodeClassFilter(LinkTag.class);
//获取匹配到的节点
NodeList list = parser.extractAllNodesThatMatch(filter);
//遍历每一个节点
for(int i=0; i上述程序对应的输出结果如下图所示:
我要讲解的第二个案例是基于 Filter 层层过滤的方式解析想要的数据。例如,w3school 页面中的:
该案例程序使用 Parser(String resource) 构造,程序如下:
//生成一个解析器对象,用网页的 url 作为参数
Parser parser = new Parser("http://www.w3school.com.cn/b.asp");
//设置网页的编码(GBK)
parser.setEncoding("gbk");
//过滤页面中的标签
NodeFilter filtertag= new TagNameFilter("ul");
NodeFilter filterParent = new HasParentFilter(filtertag); //父节点包含ul
NodeFilter filtername = new TagNameFilter("li"); //选择的节点为每个li
NodeFilter filterId= new HasAttributeFilter("id"); //并且li节点中包含id属性
NodeFilter filter = new AndFilter(filterParent,filtername); //并操作
NodeFilter filterfinal = new AndFilter(filter,filterId); //并操作
NodeList list = parser.extractAllNodesThatMatch(filterfinal); //选择匹配到的内容
//循环遍历
for(int i=0; i程序的输出结果如下:
我要讲解的第三个案例是基于 CSS 选择器来解析想要的数据。例如,w3school 页面中的:
这个案例程序我将使用 Parser(URLConnection connection) 构造,具体程序如下:
//使用URLConnection请求数据
URL url = new URL("http://www.w3school.com.cn/b.asp");
URLConnection conn = url.openConnection();
Parser parser = new Parser(conn);
//通过css选择器解析内容
CssSelectorNodeFilter Filter=new CssSelectorNodeFilter ("#course > ul > li");
NodeList list = parser.extractAllNodesThatMatch(Filter); //选择匹配到的内容
//循环遍历
for(int i=0; i使用 CSS 选择器筛选是一种简单又快捷的方式,也是我个人最喜欢用的一种解析 HTML 的方式,这和 jsoup 有异曲同工之处。如要系统的学习 CSS 选择器的使用,读者可以参考:这里。
jsoup 解析 XML
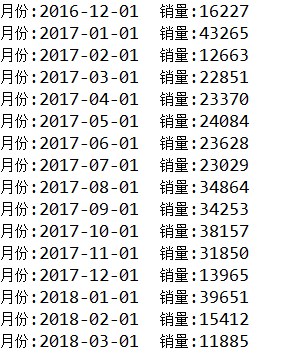
为讲解 XML 数据的解析,我选取的案例是爬取网易汽车的销量数据,例如捷达汽车的销量,页面为:
http://db.auto.sohu.com/cxdata/xml/sales/model/model1001sales.xml
其部分 XML 文件如下:
利用 jsoup 选择器,可以快速的解析 XML 文件中的数据。解析捷达汽车的销售月份以及该月份的汽车销量,可采用如下程序:
//获取URL对应的HTML内容
Document doc = Jsoup.connect("http://db.auto.sohu.com/cxdata/xml/sales/model/model1001sales.xml").timeout(5000).get();
//Jsoup选择器解析
Elements sales_ele = doc.select("sales");
for (Element elem:sales_ele) {
int salesnum=Integer.valueOf(elem.attr("salesnum"));
String date = elem.attr("date");
System.out.println("月份:" + date + "\t销量:" + salesnum);
}
程序解析数据的结果如下:
总结
本文主要讲解了 Java 中解析 HTML 的两种工具以及 jsoup 解析 XML 文件,读者可自行学习这几种工具的官方文档。在日常使用中,读者可根据工具的熟练程度进行选择。
参考内容
XPath 教程
HtmlCleaner 2.9 API
Java Examples for org.htmlcleaner.TagNode
HTML Parser 2.0
HTML Parser 简易教程——强大的解析 HTML 库
Selectors