Mysql优化4
Mysql优化4
- 14 传统分页带来的问题与优化
- 15 最大值MAX优化
- 16 统计COUNT使用注意点
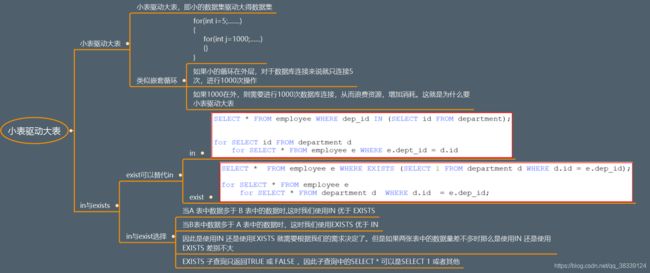
- 17 为什么要小表驱动大表
- 18 MySQL中的锁
-
- 18.1 锁的概念
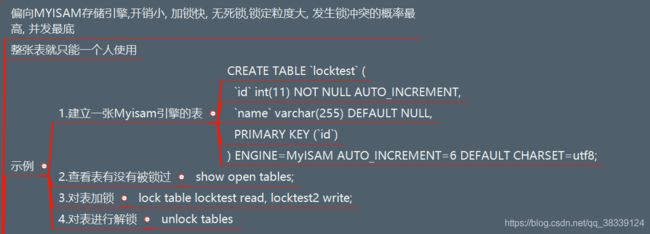
- 18.2 表锁特性与操作
- 18.3 表锁之共享锁(读锁)和排他锁(写锁)
- 18.3 表锁分析
- 18.4 行级锁特性与事务的ACID
- 18.5 并发事务处理带来的问题
- 18.6 设置事务的隔离级别
- 18.7 演示行锁
- 18.7 索引失效,行锁变表锁
- 18.8 间隙锁
- 18.9 查询时锁定一行
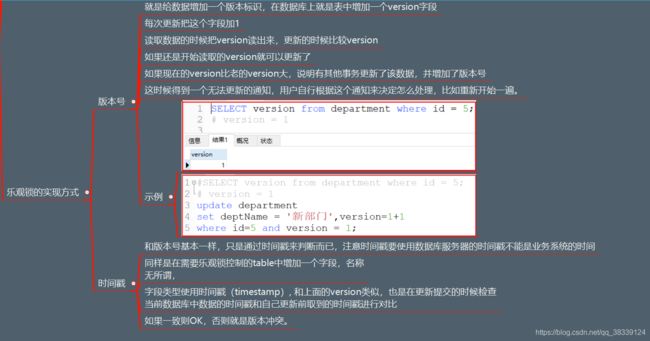
- 18.10 悲观锁与乐观锁
- 18.11 乐观锁的实现方式
14 传统分页带来的问题与优化
DROP TABLE IF EXISTS `testemployee`;
CREATE TABLE `testemployee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`dep_id` int(11) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`salary` decimal(10,2) DEFAULT NULL,
`cus_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=109 DEFAULT CHARSET=utf8;
set global log_bin_trust_function_creators=TRUE
批量拆入sql
delimiter $$
create procedure insert_emp(in max_num int)
BEGIN
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into testemployee (name,dep_id,age,salary,cus_id) values(rand_str(5),floor(1 + rand()*10),floor(20 + rand()*10),floor(2000 + rand()*10),floor(1 + rand()*10));
until i = max_num
end REPEAT;
commit;
end $$
delimiter ;
随机生成字符串
#随机生成一个指定个数的字符串
delimiter $$
create function rand_str(n int) RETURNS VARCHAR(255)
BEGIN
#声明一个str 包含52个字母
DECLARE str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
#记录当前是第几个
DECLARE i int DEFAULT 0;
#生成的结果
DECLARE res_str varchar(255) default '';
while i < n do
set res_str = CONCAT(res_str,substr(str,floor(1+RAND()*52),1));
set i = i + 1;
end while;
RETURN res_str;
end $$
delimiter ;
使用存储过程,构造100万条数据;
使用传统的分页,假设当前表中有100万条数据,不同页的分页结果如下:
原因:
使用limit随着offset增大,查询的速度会越来越慢,
会把前面的数据都取出,找到对应的位置
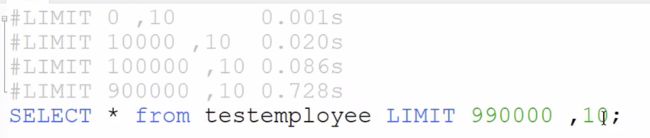
使用子查询优化,让最耗时的操作走索引
直接查:0.873s
第一种优化:0.633s
第二种优化:0.620s

使用id限定优化:传入上一页的最大值
时间:0.01s
![]()

15 最大值MAX优化
EXPLAIN SELECT MAX(AGE) FROM employee
![]()
CREATE INDEX index_age ON employee (age)
添加索引后,没有真正的去查表,而是使用优化器的统计信息
![]()
16 统计COUNT使用注意点

17 为什么要小表驱动大表
18 MySQL中的锁
18.1 锁的概念

18.2 表锁特性与操作
18.3 表锁之共享锁(读锁)和排他锁(写锁)

18.3 表锁分析

18.4 行级锁特性与事务的ACID

18.5 并发事务处理带来的问题
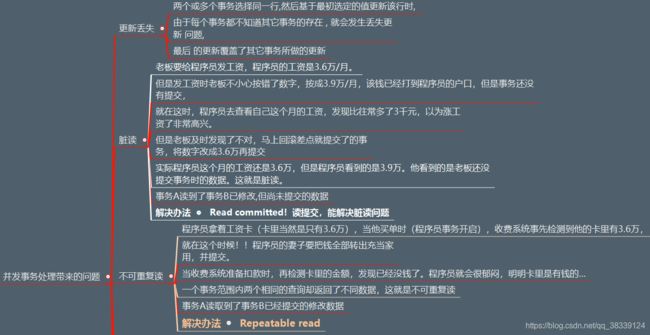

18.6 设置事务的隔离级别

18.7 演示行锁

EXPLAIN UPDATE employee set name = '张三' where id = 1
![]()
18.7 索引失效,行锁变表锁

CREATE INDEX index_name_age on employee (name,age)
EXPLAIN UPDATE employee set name = '张三' where name = '鲁班' and age = 15
EXPLAIN UPDATE employee set name = '张三' where age = 15
![]()
![]()
18.8 间隙锁

update set name = 'aaa' where id > 3 and id < 7
update set name = 'bbb' where id = 5;
18.9 查询时锁定一行

查看行锁的状态,最大的等待时长是多少
show status like 'innodb_row_lock%';
18.10 悲观锁与乐观锁


18.11 乐观锁的实现方式