锦囊篇|一文摸懂RxJava
前言
于3月14号,RxJava开源了他的第三个版本。

这个版本中,更新了一下的内容:
(1)包结构变化
RxJava 3 components are located under the io.reactivex.rxjava3 package (RxJava 1 has rx and RxJava 2 is just io.reactivex. This allows version 3 to live side by side with the earlier versions. In addition, the core types of RxJava (Flowable, Observer, etc.) have been moved to io.reactivex.rxjava3.core.
为了阅读障碍的朋友们给出我的一份四级水准翻译,有以下的几点变化:
- 文件迁移。RxJava3的组件迁移至包
io.reactivex.rxjava3中 - 向前兼容。

(2)行为变化。 针对一些现有错误的纠正等。
(3)API变化。 @FunctionalInterface注解的使用等
详细见于文档:What’s different in 3.0
就整体来说我们的基本开发功能没有很大的改变。
What is RxJava?
RxJava – Reactive Extensions for the JVM – a library for composing asynchronous and event-based programs using observable sequences for the Java VM.
RxJava 是一个在 Java VM 上使用可观测的序列来组成异步、且基于事件的程序的库。
使用方法
基于事件流的链式调用完成订阅
Observable.create<String> {
it.onNext("items:1")
it.onNext("items:2")
it.onError(Exception())
it.onComplete()
}.subscribe(object : Observer<String> {
override fun onSubscribe(d: Disposable) {
Log.d(TAG, "subscribe事件");
}
override fun onNext(s: String) {
Log.d(TAG, "Next事件:$s");
}
override fun onError(e: Throwable) {
Log.d(TAG, "Error事件");
}
override fun onComplete() {
Log.d(TAG, "Complete事件");
}
})
我们能够看到几个特别显眼的类和方法。
- Observable: 被观察者
- Observer: 观察者
- Subscribe: 订阅
- Disposable: 断连。在类出现的函数中加入
d.dispose()这一段代码,就能够让连接断开。
是否有这样的一个问题,为什么会是被观察者订阅观察者?
为了更好的理解我们将这Observable、Observer、Subscribe这三者对应到我们生活中,分别是顾客、厨师、服务员。顾客告诉服务员想吃什么,服务员告诉厨师要做什么。
接下来又出现了另外一个问题,如果我们的厨师忙不过来了呢? 想来这也是日常生活中非常容易遇到的问题了,顾客太多,厨师又只有那么几个,导致厨师忙的晕头转向了。那RxJava同样的是存在这样的问题的,处理速度一定,但是被观察者的数据量过大,我们该如何去进行处理呢?这就引出了背压的概念。
RxJava背压
上文中我们知道了RxJava要有背压的原因,这里我们再图解一下。
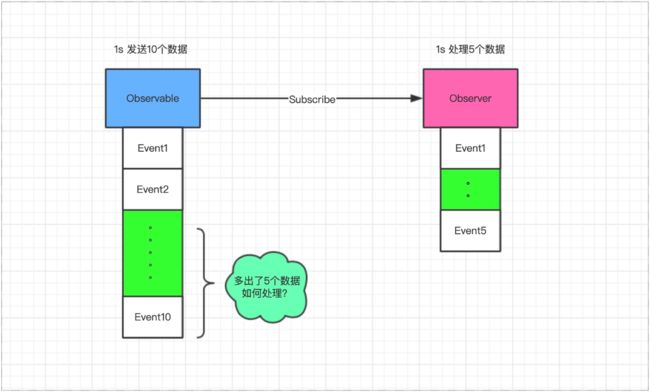
长时间出现这样的情况使得消息的堆叠,就可能会导致应用因OOM而崩溃。
在看源码的解决方案之前,我们先进行一个思考,请看下图:
注: 并不直接对应实际代码

对应源码中的基本使用
Flowable.create<Int>({
emitter ->
// 一共发送129个事件,即超出了缓存区的大小
// 将数值128改成0来观察一下变化
for (i in 0..128) {
Log.d(TAG, "发送了事件$i")
emitter.onNext(i)
}
emitter.onComplete()
}, BackpressureStrategy.ERROR) // 背压策略加入
.subscribe(object : Subscriber<Int> {
override fun onSubscribe(s: Subscription) {
Log.d(TAG, "onSubscribe")
}
override fun onNext(integer: Int) {
Log.d(TAG, "接收到了事件$integer")
}
override fun onError(t: Throwable) {
Log.w(TAG, "onError: ", t)
}
override fun onComplete() {
Log.d(TAG, "onComplete")
}
})
从源码中可以看到这样的一些使用:
- Flowable: 也就是背压的实现类
- Subscriber: 订阅,和
Observer差不多,但是多了一些适配Flowable的功能 - BackpressureStrategy: 着重讲解。
BackpressureStrategy/背压策略
这也就是我们上文中所思考的问题了,现在先看看RxJava给我们提供了什么样的方案。
public enum BackpressureStrategy {
/**
* 提示缓存区已满
*/
MISSING,
/**
* 默认模式,数据超出缓存的128时,抛出异常
*/
ERROR,
/**
* 无限缓存,可能会OOM
*/
BUFFER,
/**
* 超出128时进行丢弃后面进来的数据
*/
DROP,
/**
* 超出128时进行丢弃最开始进来的数据
*/
LATEST
}
四大策略对应结果
- MISSING

2. ERROR

3. BUFFER: 成功发送了128的事件
4. DROP: 只能获取到127数据
5. LATEST: 获取到最后发送的数据,也就是149

线程控制
讲过了上面的内容,是否有主意要过另一个非常重要的知识点,也就是线程该怎么做?
在Android的开发过程中我们一直已经都有一个强烈的概念叫做耗时任务不要放在UI线程来运作,那我们的RxJava呢?回到我们上述的代码中,做一个实验进行一下观察。
Observable.create<String> {
Log.e(TAG, "Observable的工作线程:" + Thread.currentThread().name)
}.subscribe(object : Observer<String> {
override fun onSubscribe(d: Disposable) {
Log.d(TAG, "subscribe事件");
Log.e(TAG, "Observer的工作线程:" + Thread.currentThread().name)
}
override fun onNext(s: String) {
Log.d(TAG, "Next事件:$s");
}
override fun onError(e: Throwable) {
Log.d(TAG, "Error事件");
}
override fun onComplete() {
Log.d(TAG, "Complete事件");
}
})

从图中明显能够看出,当前的工作线程为main,也就是主线程。
????那不是糟了,我们的耗时任务在主线程中进行完成的时候,不就会ANR的问题了?自然就需要找一个解决方案了。
那我们先来看看第一种,自我掩盖式。在上述的代码外加一层Thread。
![]()
图中显示到工作线程切换了,但是如何进行UI的数据更新就又成了一个问题了,当然我们还是可以自己加入Handler来解决问题的。
为了解决这样的问题,RxJava给了我们一个很好的解决方案,也就是subscribeOn() & observeOn(),以及一些已经定义好的场景内容。
| 类型 | 含义 | 应用场景 |
|---|---|---|
| Schedulers.immediate() | 当前线程 = 不指定线程 | 默认 |
| AndroidSchedulers.mainThread() | Android主线程 | 操作UI |
| Schedulers.newThread() | 常规新线程 | 耗时等操作 |
| Schedulers.io() | io操作线程 | 网络请求、读写文件等io密集型操作 |
| Schedulers.computation() | CPU计算操作线程 | 大量计算操作 |
使用方法
Observable.create<String> {
Log.e(TAG, "Observable的工作线程:" + Thread.currentThread().name)
}
.subscribeOn(Schedulers.newThread())
.observeOn(Schedulers.io())
.subscribe(object : Observer<String> {
override fun onSubscribe(d: Disposable) {
Log.d(TAG, "subscribe事件");
Log.e(TAG, "Observer的工作线程:" + Thread.currentThread().name)
}
override fun onNext(s: String) {
Log.d(TAG, "Next事件:$s");
}
override fun onError(e: Throwable) {
Log.d(TAG, "Error事件");
}
override fun onComplete() {
Log.d(TAG, "Complete事件");
}
})
![]()
操作符的使用

当然这里我就不做这么多的Demo了,建议直接看看Carson_Ho大佬的文章,下面是各个对应的链接:
- 创建操作符:https://www.jianshu.com/p/e19f8ed863b1
- 变换操作符:https://www.jianshu.com/p/904c14d253ba
- 组合/合并操作符:https://www.jianshu.com/p/c2a7c03da16d
- 功能操作符:https://www.jianshu.com/p/b0c3669affdb
- 过滤操作符:https://www.jianshu.com/p/c3a930a03855
- 条件/布尔操作符:https://www.jianshu.com/p/954426f90325
源码导读
接下来我们就拿上面一份简单源码的使用过程进行分析。
Observable.create<String> {
it.onNext("items:1")
it.onNext("items:2")
it.onError(Exception())
it.onComplete()
}.subscribe(object : Observer<String> {
override fun onSubscribe(d: Disposable) {
Log.d(TAG, "subscribe事件");
}
override fun onNext(s: String) {
Log.d(TAG, "Next事件:$s");
}
override fun onError(e: Throwable) {
Log.d(TAG, "Error事件");
}
override fun onComplete() {
Log.d(TAG, "Complete事件");
}
})
那么现在我们就要对整个结构进行一个分析:
- Observable.create:对象是如何创建的?
- Observer:观察者的函数调用过程是怎么样的
- subsrcibe:是如何将
Observer和Observable进行关联,如果是不同线程之间呢?
Observable.create
create函数作为一个泛指的存在,他还可以是just、fromArray。。他们最后都会出现一个相同的函数。
RxJavaPlugins.onAssembly(...);
// 出现了这样的几个类
// 1. ObservableFromArray
// 2. ObservableJust
// 3. ObservableFromIterable
// 4. ....
// 他们全部继承了Observable,他们有这样一个相同的重写方法subscribeActual(Observer)
我们主要拿create这个函数和这一整套流程来做一个详细的讲解。
subscribe
为了让代码纹理更清晰,删掉了健壮代码。
public final void subscribe(@NonNull Observer<? super T> observer) {
try {
// 进行链接
observer = RxJavaPlugins.onSubscribe(this, observer);
// 使得observable和observer进行了链接
subscribeActual(observer); // 1 -->
} catch (NullPointerException e) {
// NOPMD
throw e;
} catch (Throwable e) {
Exceptions.throwIfFatal(e);
RxJavaPlugins.onError(e);
npe.initCause(e);
throw npe;
}
}
那么我们就要看看这个subscribeActual()这个函数干了什么事情了。
@Override
protected void subscribeActual(Observer<? super T> observer) {
CreateEmitter<T> parent = new CreateEmitter<>(observer);
observer.onSubscribe(parent); // 2 -->
try {
source.subscribe(parent); // 3 -->
} catch (Throwable ex) {
Exceptions.throwIfFatal(ex);
parent.onError(ex);
}
}
希望读者能够注意到这样的代码CreateEmitter消息发射器的创建,以及onSubsrcibe()的链接,以及source.subscribe(parent);数据的订阅。
onSubscribe()说明我们的函数已经完成了订阅。
CreateEmitter
static final class CreateEmitter<T> extends AtomicReference<Disposable> implements ObservableEmitter<T>, Disposable {
final Observer<? super T> observer;
CreateEmitter(Observer<? super T> observer) {
this.observer = observer;
}
// 下一消息发送
@Override
public void onNext(T t) {
// 。。。
}
// 错误发送
@Override
public void onError(Throwable t) {
if (!tryOnError(t)) {
RxJavaPlugins.onError(t);
}
}
@Override
public boolean tryOnError(Throwable t) {
// 。。。
}
// 完成连接
@Override
public void onComplete() {
// 。。。
}
// 断开连接
@Override
public void dispose() {
DisposableHelper.dispose(this);
}
@Override
public boolean isDisposed() {
return DisposableHelper.isDisposed(get());
}
}
在这里我们清楚的看到了整个数据处理的逻辑,那么我们的Observer可以理解为我们一个用于自定义处理的类。
抛出一个问题,为什么我们的数据在经过一个报错之后往后的数据就不会再进行收发了?
请注意看看onError的源码。
@Override
public void onError(Throwable t) {
if (!tryOnError(t)) {
RxJavaPlugins.onError(t);
}
}
@Override
public boolean tryOnError(Throwable t) {
if (t == null) {
t = ExceptionHelper.createNullPointerException("onError called with a null Throwable.");
}
if (!isDisposed()) {
try {
observer.onError(t);
} finally {
// 消息中出现错误后,断开连接
dispose();
}
return true;
}
return false;
}
在完成一次报错的操作之后,我们的连接就被关闭了,所以我们之后的数据也就无法进行了接收。
source.subscribe(parent);
上文中因为直接使用了Kotlin的lambda表达式,所以不够直观,这里我转成Java写一次。
Observable.create(new ObservableOnSubscribe<Object>() {
@Override
public void subscribe(@NonNull ObservableEmitter<Object> emitter) throws Throwable {
}
});
这是一个Observable的创建流程,显然我们现在看到的函数就是我们要找的被进行重写的函数了。内部使用到的onNext()、onCompelete()等函数的定义就是由我们的ObservableEmitter来直接完成提供的。
异步通信
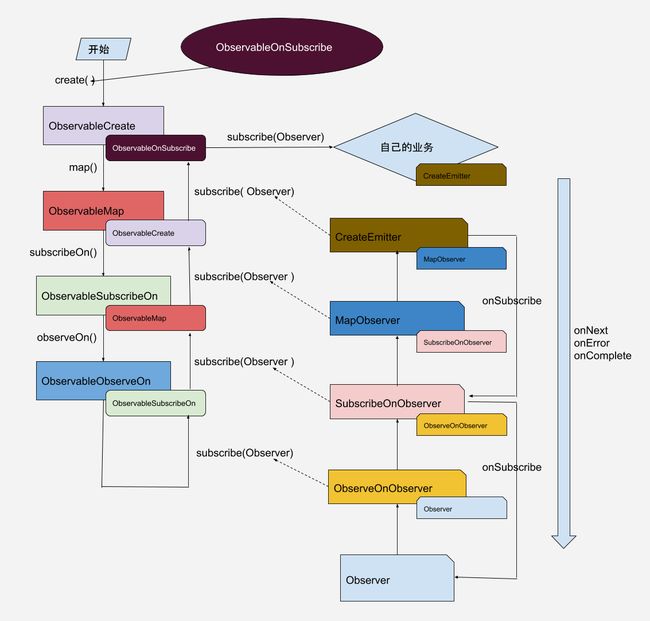
RxJava的异步通信原理
observeOn() 的线程切换原理
对于observeOn()而言,进入源码中我们能知道,它使用了这样的一个类ObservableObserveOn,而我们传入的值就是我上文所提到过的Schedulers。
public ObservableObserveOn(ObservableSource<T> source, Scheduler scheduler, boolean delayError, int bufferSize) {
super(source);
this.scheduler = scheduler; // 我们传入的Scheduler
this.delayError = delayError; // 延迟onError输出
this.bufferSize = bufferSize; // 缓冲区大小
}
让我们再这个类的他的subscribeActual()函数。
@Override
protected void subscribeActual(Observer<? super T> observer) {
if (scheduler instanceof TrampolineScheduler) {
source.subscribe(observer);
} else {
Scheduler.Worker w = scheduler.createWorker();
source.subscribe(new ObserveOnObserver<>(observer, w, delayError, bufferSize));
}
}
显然对Scheduler进行了使用,那么我们从前面的文章能够作出一个推测,这个数据的响应者就应该是ObserveOnObserver这个类了。
那我们再进入一层,看看他的构成,能看到如下的代码(onComplete()、onSubscribe()..)皆可。
@Override
public void onNext(T t) {
if (done) {
return;
}
if (sourceMode != QueueDisposable.ASYNC) {
queue.offer(t); // 1-->
}
schedule(); // 2-->
}
他的onNext()的函数中存在一个异步判断,而数据就是从一个队列中取出来的。这个队列先暂时放一边,我们猜测他和我们之前的缓存区相关。
先看看注释2的schedule()函数。
void schedule() {
if (getAndIncrement() == 0) {
worker.schedule(this);
}
}
他会调用到这个函数一个worker,而这个worker就是我们传入的Scheduler所拥有的函数了,我们选择用newThread()来进行一个查看,而this就是ObserveOnObserver本身了。
// Worker.createWorker()
public Worker createWorker() {
return new NewThreadWorker(threadFactory); // 1 -->
}
// 1-->
public NewThreadWorker(ThreadFactory threadFactory) {
// 创建了一个线程池
executor = SchedulerPoolFactory.create(threadFactory);
}
// worker.schedule(this);
public Disposable schedule(@NonNull final Runnable action, long delayTime, @NonNull TimeUnit unit) {
if (disposed) {
return EmptyDisposable.INSTANCE;
}
return scheduleActual(action, delayTime, unit, null); // 2 -->
}
// 2 -->
public ScheduledRunnable scheduleActual(final Runnable run, long delayTime, @NonNull TimeUnit unit, @Nullable DisposableContainer parent) {
Runnable decoratedRun = RxJavaPlugins.onSchedule(run);
ScheduledRunnable sr = new ScheduledRunnable(decoratedRun, parent);
// ....
Future<?> f;
try {
// 使用一个线程池来维持数据的数据的有效运行
if (delayTime <= 0) {
f = executor.submit((Callable<Object>)sr);
} else {
f = executor.schedule((Callable<Object>)sr, delayTime, unit);
}
sr.setFuture(f); // 通过返回新的线程并设置完成线程切换
} catch (RejectedExecutionException ex) {
if (parent != null) {
parent.remove(sr);
}
RxJavaPlugins.onError(ex);
}
return sr;
}
将我们的ObserveOnObserver扔进了线程池以后就已经完成了线程切换了。
subscribeOn() 的线程切换原理
抛出一个问题,为什么网上都说subscribeOn()只会生效一次?
我们再次慢慢地用源码说明问题,下方是ObservableSubscribeOn类的subscribeActual()函数。
@Override
public void subscribeActual(final Observer<? super T> observer) {
// 创建了与之绑定用的SubscribeOnObserver
final SubscribeOnObserver<T> parent = new SubscribeOnObserver<>(observer);
observer.onSubscribe(parent);
// SubscribeTask就是一个Runnable
// 然后scheduler不知干了什么事情
parent.setDisposable(scheduler.scheduleDirect(new SubscribeTask(parent))); // 1-->
}
public Disposable scheduleDirect(@NonNull Runnable run, long delay, @NonNull TimeUnit unit) {
final Worker w = createWorker();
final Runnable decoratedRun = RxJavaPlugins.onSchedule(run);
// 只是将Runnable 和 Worker进行绑定
DisposeTask task = new DisposeTask(decoratedRun, w);
// schedule的函数是否有所眼熟
// 在上文的observeOn中我们也有所提及
// 使用了线程池来进行维护的线程切换的位置
w.schedule(task, delay, unit); // 2-->
return task;
}
经过上述步骤后我们就获取了对应的Disposable,那就进入了parent.setDisposable()的函数了。
void setDisposable(Disposable d) {
DisposableHelper.setOnce(this, d);
}
其实从名字我们就看出来一个问题了setOnce(),已经说明只能值设置一次,所以已经这里已经证明了为什么我的subscribeOn()只有第一次设置的时候才会生效的原因了。
收! 回到我们的线程内容,既然是线程池,自然要看看他对应的线程了,看看我们的DisposeTask的run()函数把。
@Override
public void run() {
runner = Thread.currentThread();
try {
decoratedRun.run(); // 1 --> SubscribeTask
} finally {
dispose();
runner = null; // 当前线程运行完就释放
}
}
// 对应我们SubscribeTask中的run()函数
public void run() {
// 这个source就是我们的observable
source.subscribe(parent);
}
上流事件也就是让上层的Observable又对我们的数据SubscribeOnObserver进行了一次订阅,这个时候线程又一次进行了切换操作。
RxAndroid是如何完成异步的通信的?
对我们的一个RxAndroid而言,一般谁是在IO线程,谁在UI线程呢?
好吧,直接问,可能会没有思路,那我们换个问题,谁是数据产生者,谁是数据消费者? 对应到我们的网络请求过程,显然网络请求是一个在子线程工作的任务,而数据更新就是在主线程。那么对应到我们的RxJava,显然是Observable是产生者,而Observer是消费者,那么我们也就知道了谁应该在IO线程了,显然是Observable,而Observer应该处于UI线程了。但是这就是问题所在了,我们该如何进行数据的通信呢?我的被观察者有数据了,但是我们的观察者该如何知道?
先来看一下如何进行使用,我们应该在IO线程中进行订阅,在UI线程中进行观察。
.subscribeOn(Schedulers.io()) // 对应 被观察者
.observeOn(AndroidSchedulers.mainThread()) // 对应 观察者
在上文中我们提到了一个叫做缓存区的概念,在我们的FlowableCreate的源码中能找到关于这一部分的源码。
// 在源码的64行上下
emitter = new BufferAsyncEmitter<>(t, bufferSize());
// bufferSize()函数对应的数据就是我们的128
// 所以会有我们缓存超出128时报错的情况存在
但是这里我们并没有看到和数据发送相关的内容,只看到一个缓冲区的存在。那我们就继续往下进行分析了。我们之前分析过Observer的源码,里面使一些接收的过程,而Subscribe也差不多,所以方案也同样的不在这个类中。
那就进行定位了,是我们最开始的代码起了什么样的作用。
AndroidSchedulers.mainThread()
对于Emitter而言,其实他已经持有了订阅的对象,可以直接发送数据,有点类似于观察者模式,但是Flowable中我们能够发现的数据拉取,其实是通过FlowableSubscriber来进行主动拉取,和观察者模式的主动推送有一定的区别。
但是数据的通信还是需要看看我们的AndroidSchedulers.mainThread()。因为我们要进行UI线程的数据更新,自然是不会使用上述的方法进行的,那RxJava是如何完成这样的操作的呢。
进入到observeOn的源码中能看到
public void subscribeActual(Subscriber<? super T> s) {
Worker worker = scheduler.createWorker();
if (s instanceof ConditionalSubscriber) {
source.subscribe(new ObserveOnConditionalSubscriber<>(
(ConditionalSubscriber<? super T>) s, worker, delayError, prefetch));
} else {
source.subscribe(new ObserveOnSubscriber<>(s, worker, delayError, prefetch));
}
}
我们能够看到这样的一段代码scheduler.createWorker(),我们拿AndroidSchedulers.mainThread()来看上一看。
public final class AndroidSchedulers {
private static final class MainHolder {
static final Scheduler DEFAULT
= new HandlerScheduler(new Handler(Looper.getMainLooper()), true);
}
}
HandlerScheduler(Handler handler, boolean async) {
this.handler = handler;
this.async = async;
}
在类AndroidSchedulers中的构造能够发现其实最后使用的就是一个Handler的机制,也就是说最后要切到主线程时使用的就是Handler的机制来发送消息了,而且他直接获取了主线程的Looper,将消息直接传输到了主线程。
那么讲述到这儿我们的RxJava的整体流程就已经讲完了。
总结

参考资料
- Carson_Ho大佬的RxJava的系列文章:https://www.jianshu.com/p/e1c48a00951a
- 详解 RxJava2 的线程切换原理:https://www.jianshu.com/p/a9ebf730cd08