携程酒店数据爬取2020.5
携程酒店数据爬取2020.5
1. 开题
目前网上有好多爬取携程网站的教程,大多数通过xpath,beautifulsoup,正则来解析网页的源代码。然后我这个菜b贪方便,直接copy源码的xpath,paste在xpath helper改改规则。xpath helper识别出结果后,我就已经看到了成功的希望,xpath真香。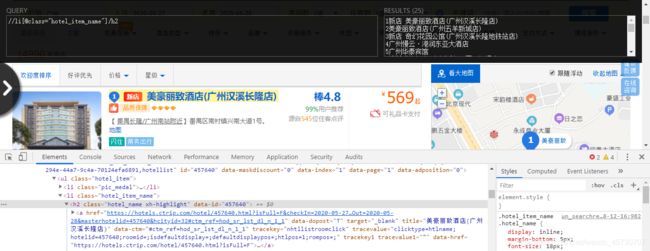
然而,意想不到的是,在进行测试时,却匹配不出任何结果,我手中的鸡腿(xpath)就不香了,曾一度怀疑,是我水平太菜了,没写正确,然后一直回去学xpath知识,一边学啊,一边测试,甚至中途换了beautifulsoup,正则,selenium(建议不要用selenium,打开网站时候会自动跳转到携程账号登录页面,估计是携程反爬的设置)。直到后来才发现解析的源代码根本就没包含我想要的信息(酒店名称,酒店地址这些东西,携程有可能设置了反爬),这也说明了,我水平真的菜,才会一直没发现源代码的错误(我暂且认为源代码中没有显示酒店名称,地址这类信息)
>>> hotel_name = html.xpath('//p[@class="hotel_item_htladdress"]/text()')
>>> print(hotel_name)
[]
>>> hotel_name = html.xpath('//li[@class="hotel_item_name"]/h2')
>>> print(hotel_name)
[]
2.人肉搜索器的变化
因为写不出来代码,而业务上需要信息,故我这个菜b只能一边Ctrl C + Ctrl v,手指都快抽筋了,才把部分数据给复制下来,最后只能祭出GitHub大法了

在看完了几个大佬写的代码,看不懂还是看不懂。
但是抄,我是专业的,这孩子从小就是抄袭砖家,Ctrl A + Crtl c + crl v 三键下去,一气呵成。
感谢让抄的老哥(author: songwei,附上他的网址:https://github.com/songweiwei/pachong/blob/master/main.py#L29)
在抄完之后要干吗?改啊!
要怎么改啊?针对这一点,我是会的。
同学们,小葵花妈妈开课了,孩子会抄,不会改,怎么办呢?多半是上课没好好学,打一顿就好了。咳咳,偏题了。
首先呢,我们先看看携程网站的网址,它的网址是固定了,也就是不管你翻到第几页,它的网址一成不变。稍微学过点爬虫的同学都知道,我们爬取网站都是通过网址的页数进行翻页,那没能通过页数进行解析,怎么办呢?
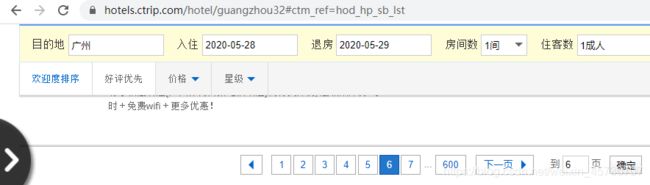
此时,百度就是你的老师,你要熟练地打开网站,敲上你最喜欢的网址,准备好纸巾…呸呸呸,又飙车了。
本菜b饱览群书(抄袭大佬的观点),在网页反馈的信息中后面添加p1,p2便可实现翻页的功能:
第一页:https://hotels.ctrip.com/hotel/guangzhou32/p1
第二页:https://hotels.ctrip.com/hotel/guangzhou32/p2
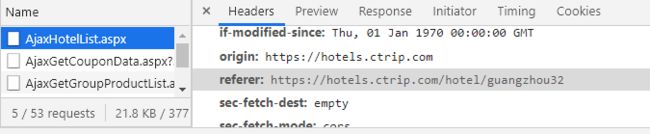
看到这里,细心的同学就会想到,楼主这个菜b不是刚刚才说完,网页的源代码不是没有想要的信息(酒店名称,地址)吗?即便会翻页,那网页的源代码没信息,还翻个屁啊?
对,没错,翻个屁,就是没什么卵用。
于是,我们要从其他地方入手。
楼主这个菜b又饱览群书,通过百度老师,猛然发现@icmp_no_request大神的帖子(https://blog.csdn.net/pandalaiscu/article/details/87644235),于是乎,我在抄的路上又迈开一大步,学会通过接口获取数据。
在AjaxHotelList.aspx文件发现了存储信息的位置,其格式是json,其中hotelPositionJSON里面存储了25条数据(一个网页只显示25条数据)
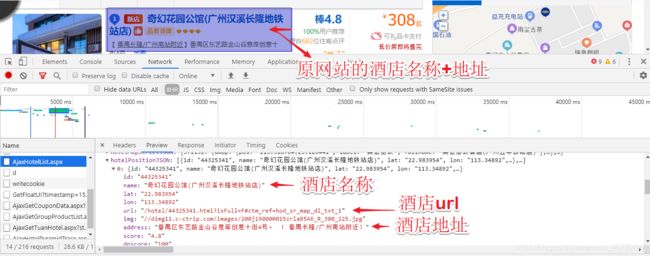
hotelPositionJSON中的url是打开酒店详细信息的“钥匙”,能查看酒店的具体信息(如介绍,设施等情况)
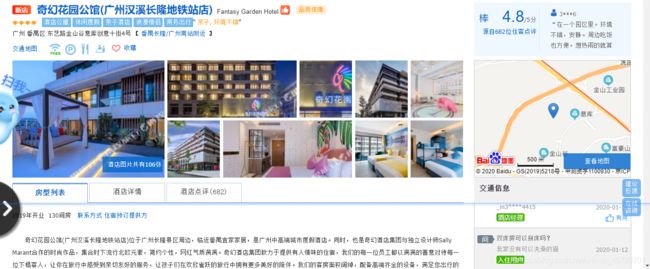
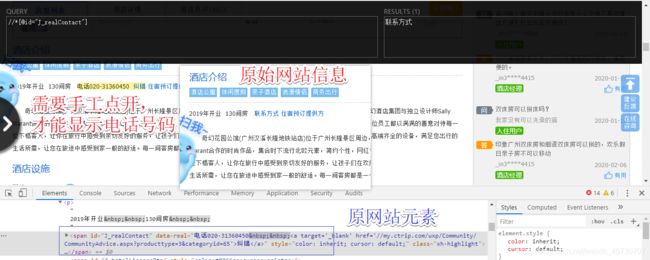
但在打开酒店具体信息的网址后,我们会发现一些问题,如下图中的原始网站只显示“联系方式”,这需要手工点击“联系方式”字段才能显示电话号码,若是通过xpath解析,也只是出现个“联系方式”的字段,因此这一块需要解析原网站的网页元素,针对这一块内容,我这边是用正则来写的,没错,“正则”真香。
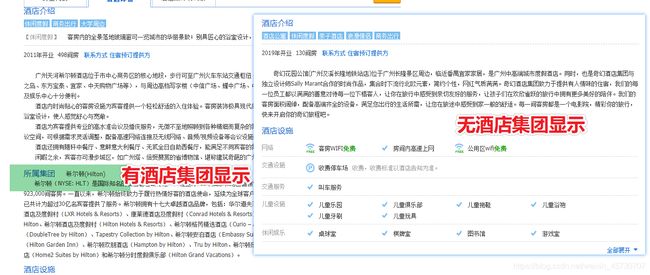
其次对于酒店品牌和集团的获取,我们这里用回了xpath进行解析(因为网页的源代码已经有我们想要的信息)。由于携程的品牌名称显示在网站的首头,而部分网站没有品牌名称(如第一种和第二种所示),只有第三钟包含我们想要的品牌名称字段(酒店品牌:希尔顿)。此外部分酒店网页也是没有显示酒店集团的元素,若是通过xpath定位,有可能导致匹配信息错误。
针对这些问题,我们通过判断返回的xpath值若是为空,则不存在该元素来规避数据错误值

3.开始征程之路
作好了以上的解析后,我们可以开始写(改大神的)代码了
3.1 构建存储器
#构建数组存储数据
#构建数组存储数据
hotel_name = [] #酒店名称
hotel_address = [] #酒店地址
hotel_iphone = [] #酒店电话
hotel_brand = [] #酒店品牌
hotel_business = [] #酒店所属集团
3.2 构建请求头
其中user-agent用了fake_useragent包
url = "https://hotels.ctrip.com/Domestic/Tool/AjaxHotelList.aspx"
headers = {
'Content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Origin': 'https://hotels.ctrip.com',
'Referer': 'https://hotels.ctrip.com/hotel/guangzhou32',
'accept': '*/*',
'user-agent': str(UserAgent().random)
}
3.3 构造请求字段
#page是页码(翻页),广州cityID是32(北京cityID是1)
formData = {
'cityId': 32, #城市id号
'page': 1 #页码
}
3.4 发起网站请求
# 发起网络请求
r = requests.post(url, data=formData, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding #防止出现乱码现象
3.5 解析网站元素
# 解析 json 文件,提取酒店数据
js=json.loads(r.text)
json_data = json.loads(r.text)['hotelPositionJSON']
for item in json_data:
hotelName = item['name']
hotelAdress = item['address']
hotelUrl = item['url']
hotel_name.append(hotelName)
hotel_address.append(hotelAdress)
#在首页打开酒店url,获取电话号码,其中电话隐藏了,因此用正则直接提取
new_hotelUrl = "https://hotels.ctrip.com" + item['url']
req = requests.get(new_hotelUrl,headers=headers)
page = req.text
pattern = re.compile(',re.S)
item_iphone = pattern.findall(page)
hotel_iphone.append(item_iphone) #正则写入数据的形式是列表,这里再次把列表数据写入列表
#xpath解析酒店品牌+集团
html = etree.HTML(page)
hotelBrand = html.xpath('//*[@id="base_bd"]/div[2]/a[3]/text()')
if fnmatch(str(hotelBrand),"*区*"):
hotel_brand.append("无")
elif len(hotelBrand) ==0:
hotel_brand.append("无")
else:
hotel_brand.append(hotelBrand)
hotelBusiness = html.xpath('//*[@id="hotel_info_comment"]/div/span/text()')
if len(hotelBusiness) == 0:
hotel_business.append("无")
else:
hotel_business.append(hotelBusiness)
3.6 存储数据
#储存
wb = workbook.Workbook()
ws = wb.active
ws.append(["酒店名称","地址",'电话号码','酒店品牌','酒店集团'])
for i in range(0,len(hotel_name)):
ws.append([hotel_name[i],hotel_address[i],hotel_iphone[i][0],hotel_brand[i][0],hotel_business[i][0]])
#存储位置:C:\Users\Administrator
wb.save("携程酒店数据.xlsx")
4.结果展示与不足反思
本次代码由于业务和时间关系,只解析了酒店名称,地址,电话号码,酒店品牌和集团这五个字段,因此各位小伙伴若是要解析其他信息,您可以通过我这篇文章的代码思路继续进行解析。
最后我反思一下本次代码的不足:
- 没有设置ip代理池,若是数据量大,必然会封ip。后期用代理ip进行测试,发现一个代理ip短时间内抓100条数据就失效了
- 获取25条数据时,需要打开25个网页,也就说打开一个网页需要一秒时间,若是要爬取大量的数据,其时间耗费长。后期仍需努力学习啊。
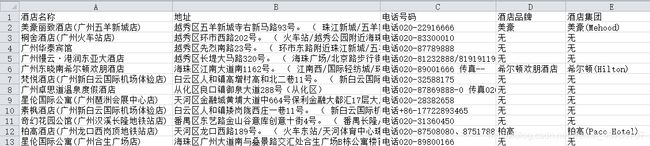
5.完整代码
import requests
from lxml import etree
from fake_useragent import UserAgent
import os, re, json, traceback,random,time
from openpyxl import workbook # 写入Excel表所用
from fnmatch import fnmatch
#启用时间
start = time.time()
#构建数组存储数据
hotel_name = [] #酒店名称
hotel_address = [] #酒店地址
hotel_iphone = [] #酒店电话
hotel_brand = [] #酒店品牌
hotel_business = [] #酒店所属集团
#构建请求头
url = "https://hotels.ctrip.com/Domestic/Tool/AjaxHotelList.aspx"
headers = {
'Content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Origin': 'https://hotels.ctrip.com',
'Referer': 'https://hotels.ctrip.com/hotel/guangzhou32',
'accept': '*/*',
'user-agent': str(UserAgent().random)
}
#主代码
for i in range(1,10):
print("爬取第%d页" %i )
proxy = ["103.233.152.140:8080","222.249.238.138:8080","101.4.136.34:8080","58.253.66.47:8080"]
proxies = {
"http": str(random.choice(proxy))}
#page是页码(翻页),广州cityID是32(北京cityID是1)
formData = {
'cityId': 32,
'page': i
}
# 发起网络请求
r = requests.post(url, data=formData, headers=headers,proxies=proxies)
r.raise_for_status()
r.encoding = r.apparent_encoding #防止出现乱码现象
# 解析 json 文件,提取酒店数据
js=json.loads(r.text)
json_data = json.loads(r.text)['hotelPositionJSON']
for item in json_data:
hotelName = item['name']
hotelAdress = item['address']
hotelUrl = item['url']
hotel_name.append(hotelName)
hotel_address.append(hotelAdress)
#在首页打开酒店url,获取电话号码,其中电话隐藏了,因此用正则直接提取
new_hotelUrl = "https://hotels.ctrip.com" + item['url']
req = requests.get(new_hotelUrl,headers=headers)
page = req.text
pattern = re.compile(',re.S)
item_iphone = pattern.findall(page)
hotel_iphone.append(item_iphone) #正则写入数据的形式是列表,这里再次把列表数据写入列表
#xpath解析酒店品牌+集团
html = etree.HTML(page)
hotelBrand = html.xpath('//*[@id="base_bd"]/div[2]/a[3]/text()')
if fnmatch(str(hotelBrand),"*区*"):
hotel_brand.append("无")
elif len(hotelBrand) ==0:
hotel_brand.append("无")
else:
hotel_brand.append(hotelBrand)
hotelBusiness = html.xpath('//*[@id="hotel_info_comment"]/div/span/text()')
if len(hotelBusiness) == 0:
hotel_business.append("无")
else:
hotel_business.append(hotelBusiness)
#储存
wb = workbook.Workbook()
ws = wb.active
ws.append(["酒店名称","地址",'电话号码','酒店品牌','酒店集团'])
for i in range(0,len(hotel_name)):
ws.append([hotel_name[i],hotel_address[i],hotel_iphone[i][0],hotel_brand[i][0],hotel_business[i][0]])
#存储位置:C:\Users\Administrator
wb.save("携程酒店数据.xlsx")
#结束
end = time.time()
print("耗时(分钟):",(end - start)/60)
print("爬取页数:",len(hotel_name)/25)