Pytorch实战总结篇之数据准备
1. 写在前面
这段时间一直在持续学习Pytorch, 也大约整理了20篇左右的笔记, 主要包括系统学习Pytorch的10篇, 这里面主要是从原理的层次看Pytorch的运行机制, 一方面是可以大致上对学习Pytorch有一个整体的框架, 另一方面是能理解很多知识的背后原理, 然后是Pytorch的入门与实战8篇, 这里面是使用Pytorch进行一些实战任务, 从图像到语音, 大致上可以知道Pytorch在各个领域是怎么发挥作用的, 但是经过前面的这些文章, 可能依然无法把Pytorch运用起来, 第一个系列是偏底层原理和知识框架, 而第二个系列作为一个桥梁纽带, 更多的是介绍图像和语音方面的知识, 然后用Pytorch进行了一些任务的完成,如果换了任务, 可能依然不知道如何使用Pytorch, 所以这个终结系列的几篇文章从纯使用的角度来总结Pytorch,毕竟Pytorch还是作为一种工具, 下面我们就来看看真正的使用方法。
通过前面的学习, 使用Pytorch实现神经网络建模一般包括数据准备、模型建立、模型训练、模型评估使用和保存, 所以接下来会整理四篇文章对这几方面进行使用总结。 今天是第一篇数据准备部分, 对于我自己来讲, 数据准备其实是这里面非常重要且比较困难的一个部分, 在实际任务中我们一般会面临结构化数据、图片数据、文本数据和时间序列数据, 不同的数据又会有不同的数据准备方法, 所以这篇文章主要是整理如何对这四种数据进行准备, 每种数据又有哪些不同的建模方法。
大纲如下:
- 再聊Dataset和DataLoader
- 结构化数据建模
- 时序数据建模
- 图片数据建模
- 文本数据建模
- 总结
Ok, let’s go !
2. 再聊Dataset和DataLoader
Pytorch通常是使用Dataset和DataLoader这两个工具类构建数据管道, 所以我们要建模各种数据, 避不开这两个工具类, 它们的内部原理曾在这篇文章解释过,现在再来简单的回顾一下。
Dataset定义了数据集的内容,它相当于一个类似列表的数据结构,具有确定的长度,能够用索引获取数据集中的元素。而DataLoader定义了按batch加载数据集的方法, 它是一个实现了__iter__方法的可迭代对象, 每次迭代输出一个batch的数据。DataLoader能够控制batch的大小,batch中元素的采样方法,以及将batch结果整理成模型所需输入形式的方法,并且能够使用多进程读取数据。在绝大部分情况下,我们只需实现Dataset的__len__方法和__getitem__方法,就可以轻松构建自己的数据集,并用默认数据管道进行加载。
2.1 Dataset和DataLoader概述
要想通过这两个工具类完成数据管道的构建, 那么会有两个问题, 如何获取到一个batch? 在这个过程中Dataset和DataLoader是如何分工合作的, 下面围绕这两个问题进行展开。
2.1.1 获取一个batch数据的步骤
假定数据集的特征和标签分别表示张量X和Y, 数据集可以表示层(X, Y), batch大小为m, 那么获取一个batch的步骤如下:
- 首先要确定数据集的长度n
我们得先知道一共有多少个样本, 这时候当我们指定每个batch大小的时候, 计算机好知道能划分为几个batch啊, 比如n=1000, 也就是1000个样本数据。 - 然后我们从0到n-1的范围中抽样出m个数(batch大小)
假设m=4, 我们拿到的结果就是一个列表, 类似:indics = [1, 4, 8, 9] - 有了下标, 我们就可以从数据集中去取这m个数对应的下标的元素
这时候我们会拿到一个元组列表, 类似:samples = [(X[1],Y[1]),(X[4],Y[4]),(X[8],Y[8]),(X[9],Y[9])] - 最后我们将结果整理成两个张量作为输出
最后拿到的结果是两个张量, 类似batch=(features, labels), 其中features=torch.stack([X[1],X[4],X[8],X[9]]),labels = torch.stack([Y[1],Y[4],Y[8],Y[9]])
这样就完成了一个batch数据的获取操作。
2.1.2 Dataset和DataLoader的功能分工
那么第二个问题, 这个过程中每个步骤Dataset和DataLoader是如何分工的呢? 还记得这个图吗?

通过这个流程图,把DataLoader读取数据的流程梳理了一遍,具体细节不懂没有关系,但是这个逻辑关系应该要把握住,这样才能把握宏观过程,也能够清晰的看出DataLoader和Dataset的关系。DataLoader的作用就是构建一个数据装载器, 根据我们提供的batch_size的大小, 将数据样本分成一个个的batch去训练模型,而这个分的过程中需要把数据取到,这个就是借助Dataset的getitem方法。 两者的分工如下:
- 上面的第一个步骤, 也就是数据的总长度, 这个需要我们在Dataset的
__len__方法中告诉计算机。 - 上面的第二个步骤, 0到n-1的范围中抽样出m个数的方法是由 DataLoader的
sampler和batch_sampler参数指定的。sampler参数指定单个元素抽样方法,一般无需我们设置,程序默认在DataLoader的参数shuffle=True时采用随机抽样,shuffle=False时采用顺序抽样。batch_sampler参数将多个抽样的元素整理成一个列表,一般无需我们设置,默认方法在DataLoader的参数drop_last=True时会丢弃数据集最后一个长度不能被batch大小整除的批次,在drop_last=False时保留最后一个批次。
- 第三个步骤是根据下标取数据集中的元素, 这个得我们自己写如何读取元素, 由Dataset的
__getitem__方法实现, 这个函数接收的参数是一个索引。 - 第四个步骤逻辑由DataLoader的参数
collate_fn指定。一般情况下也无需我们设置。
2.2 Dataset和DataLoader的使用
上面已经简单回顾了一下两个工具类读取数据的流程, 下面就是介绍具体使用了。
2.2.1 使用Dataset创建数据集
下面先看一下Dataset的核心接口逻辑伪代码:
class Dataset(object):
def __init__(self):
pass
def __len__(self):
raise NotImplementedError
def __getitem__(self,index):
raise NotImplementedError
Dataset创建数据集常用的方法:
- 使用
torch.utils.data.TensorDataset根据Tensor创建数据集(numpy的array,Pandas的DataFrame需要先转换成Tensor)。 - 使用
torchvision.datasets.ImageFolder根据图片目录创建图片数据集。 - 继承
torch.utils.data.Dataset创建自定义数据集(这时候要实现里面的len和getitem方法)
此外,还可以通过
torch.utils.data.random_split将一个数据集分割成多份,常用于分割训练集,验证集和测试集。- 调用Dataset的加法运算符(
+)将多个数据集合并成一个数据集。
这些方法会在下面不同的数据构建中演示。
2.2.2 使用DataLoader加载数据集
下面先看一下DataLoader的逻辑接口代码, 具体详细的内部工作流程可以参考上面的那篇文章, 里面通过调试的方式看它们的工作原理:
class DataLoader(object):
def __init__(self,dataset,batch_size,collate_fn,shuffle = True,drop_last = False):
self.dataset = dataset
self.sampler =torch.utils.data.RandomSampler if shuffle else \
torch.utils.data.SequentialSampler
self.batch_sampler = torch.utils.data.BatchSampler
self.sample_iter = self.batch_sampler(
self.sampler(range(len(dataset))),
batch_size = batch_size,drop_last = drop_last)
def __next__(self):
indices = next(self.sample_iter)
batch = self.collate_fn([self.dataset[i] for i in indices])
return batch
DataLoader能够控制batch的大小,batch中元素的采样方法,以及将batch结果整理成模型所需输入形式的方法,并且能够使用多进程读取数据。
DataLoader的函数签名如下:
DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=None,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None,
multiprocessing_context=None,
)
一般情况下,我们仅仅会配置 dataset, batch_size, shuffle, num_workers, drop_last这五个参数,其他参数使用默认值即可。
DataLoader除了可以加载我们前面讲的 torch.utils.data.Dataset 外,还能够加载另外一种数据集 torch.utils.data.IterableDataset。
Dataset数据集相当于一种列表结构不同,IterableDataset相当于一种迭代器结构。 它更加复杂,一般较少使用。参数说明如下:
dataset: 数据集batch_size: 批次大小shuffle: 是否乱序sampler: 样本采样函数,一般无需设置。batch_sampler: 批次采样函数,一般无需设置。num_workers: 使用多进程读取数据,设置的进程数。collate_fn: 整理一个批次数据的函数。pin_memory: 是否设置为锁业内存。默认为False,锁业内存不会使用虚拟内存(硬盘),从锁业内存拷贝到GPU上速度会更快。drop_last: 是否丢弃最后一个样本数量不足batch_size批次数据。timeout: 加载一个数据批次的最长等待时间,一般无需设置。worker_init_fn: 每个worker中dataset的初始化函数,常用于 IterableDataset。一般不使用。
下面看一个小例子:
#构建输入数据管道
ds = TensorDataset(torch.arange(1,50))
dl = DataLoader(ds,
batch_size = 10,
shuffle= True,
num_workers=2,
drop_last = True)
#迭代数据
for batch, in dl:
print(batch)
结果:
tensor([43, 44, 21, 36, 9, 5, 28, 16, 20, 14])
tensor([23, 49, 35, 38, 2, 34, 45, 18, 15, 40])
tensor([26, 6, 27, 39, 8, 4, 24, 19, 32, 17])
tensor([ 1, 29, 11, 47, 12, 22, 48, 42, 10, 7])
3. 结构化数据建模
结构化数据非常常见, 所谓结构化的数据建模, 就是把结构化的数据封装成上面DataLoader的这种形式, 这就成了可迭代的数据管道, 这时候, 模型训练的时候, 就可以遍历DataLoader对象去取数据了。
对于结构化数据建模方式, 我见到的有下面三种建模方式, 先整理下来:
-
直接用
TensorDataset和DataLoader封装成可迭代的数据管道
感觉这是比较简单的一种方式, 流程就是我们只要把结构化的数据预处理完毕, 做成训练集和测试集之后, 就可以直接拿这两个函数进行封装, 下面是Titanic生存预测的例子:
PS: 由于这里只看结构化数据是如何进行数据建模的, 故数据处理部分的细节这里不做解释了哈哈。# 首先, 读入数据 dftrain_raw = pd.read_csv('./data/titanic/train.csv') dftest_raw = pd.read_csv('./data/titanic/test.csv')我们看一下数据是长下面这样的, 典型的结构化数据
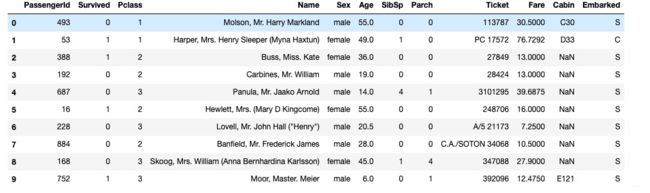
下面, 进行简单的数据预处理, 划分出训练集和测试集:def preprocessing(dfdata): dfresult= pd.DataFrame() #Pclass dfPclass = pd.get_dummies(dfdata['Pclass']) dfPclass.columns = ['Pclass_' +str(x) for x in dfPclass.columns ] dfresult = pd.concat([dfresult,dfPclass],axis = 1) #Embarked dfEmbarked = pd.get_dummies(dfdata['Embarked'],dummy_na=True) dfEmbarked.columns = ['Embarked_' + str(x) for x in dfEmbarked.columns] dfresult = pd.concat([dfresult,dfEmbarked],axis = 1) return(dfresult) x_train = preprocessing(dftrain_raw).values # x_train.shape = (712, 15) y_train = dftrain_raw[['Survived']].values # y_train.shape = (712, 1) x_test = preprocessing(dftest_raw).values # x_test.shape = (179, 15) y_test = dftest_raw[['Survived']].values # y_test.shape = (179, 1)数据处理完毕之后, 我们发现训练集样本个数是712, 特征个数是15, 下面我们只需要一步就可以构建数据管道了:
dl_train = DataLoader(TensorDataset(torch.tensor(x_train).float(),torch.tensor(y_train).float()), shuffle = True, batch_size = 8) dl_valid = DataLoader(TensorDataset(torch.tensor(x_test).float(),torch.tensor(y_test).float()), shuffle = False, batch_size = 8) # 我们可以测试一下数据管道 for features,labels in dl_train: print(features,labels) break -
第二种是可以自己构造数据管道迭代器, 而不通过Pytorch提供的接口
这种方式有点麻烦了, 需要自己写如何划分的数据, 思路也挺简单, 首先, 获得全部数据的个数, 然后生成索引, 然后就是根据提供的batch大小把索引划分开, 然后返回对应的数据即可。下面基于随机生成的数据例子看演示:## 首先随机生成X, Y #样本数量 n = 400 # 生成测试用数据集 X = 10*torch.rand([n,2])-5.0 #torch.rand是均匀分布 w0 = torch.tensor([[2.0],[-3.0]]) b0 = torch.tensor([[10.0]]) Y = X@w0 + b0 + torch.normal( 0.0,2.0,size = [n,1]) # @表示矩阵乘法,增加正态扰动这个依然是结构化数据, 数据集有400个样本, 2个特征。下面我们自己构建数据管道:
# 构建数据管道迭代器 def data_iter(features, labels, batch_size=8): num_examples = len(features) indices = list(range(num_examples)) np.random.shuffle(indices) #样本的读取顺序是随机的 for i in range(0, num_examples, batch_size): indexs = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) yield features.index_select(0, indexs), labels.index_select(0, indexs)这就是自己构建数据管道的代码, 模型训练的时候, 直接遍历一下这个即可, 没有用到DataSet和DataLoader。下面我们测试一下效果:
for feature, label in data_iter(X, Y, batch_size=8): print(feature) print(label) break看一下效果:
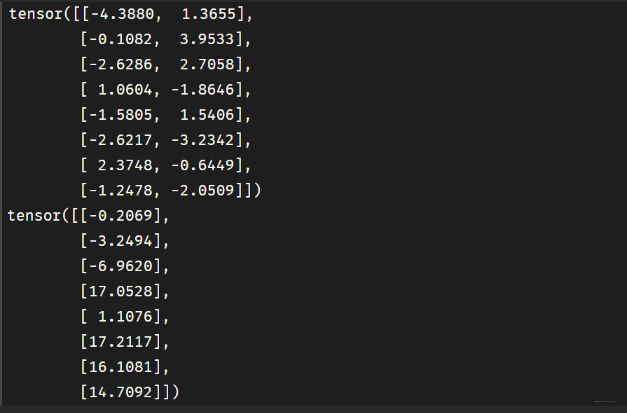
这样就会拿到一批(X, Y), 就可以进行神经网络的训练了。 -
第三种是通过继承Pytorch的
Dataset自己写Dataset自定义数据集, 然后通过DataLoader进行封装
这种方式也比较常见, 就比如人民币二分类的那个例子, 当然, 那是个图像的, 这种方式一般常用在时序数据建模上, 因为时序数据属于自回归建模,一般会用到历史数据, 所以不能单纯的像上面那样通过索引进行划分。 就需要在生成数据集的时候自定义一些处理方式。 这个方法会在时序数据建模的部分进行演示。
所以结构化数据的建模方式里面, 一般最常用的是第一种方式, 直接进行封装, 而如果碰到了时序数据, 常用的是第三种方式, 自定义数据集然后封装, 这个具体看后面的例子。并且第三种方法是通用方法, 不仅适用于时序数据, 像图片, 文本数据都可以使用这种方式。
4. 时序数据建模
时序数据建模一般要自己定义数据集, 因为这个涉及到了自回归问题, 也就是用到了历史的数据作为特征。 这种数据一般会采用一个叫做滑动窗口的东西把原数据集进行一个切割获得X和Y, 下面我们拿一个比较简单的例子看一下怎么使用:
这个数据集是中国2020年3月之前的疫情数据,典型的时间序列数据, 数据长下面这样:
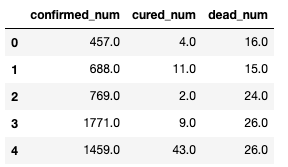
特征是确诊人数, 治愈人数和死亡人数, 而我们预测的也是接下来的确诊人数, 治愈人数和死亡人数,自回归了。 下面通过继承torch.utils.data.Dataset实现自定义时间序列数据集。
__len__: 实现len(dataset)返回整个数据集的大小__getitem__: 用来获取一些索引的数据, 使dataset[i]返回数据集中的第i个样本。
必须要覆盖这两个方法。
#用某日前8天窗口数据作为输入预测该日数据
WINDOW_SIZE = 8
class Covid19Dataset(Dataset):
def __len__(self):
return len(dfdiff) - WINDOW_SIZE
def __getitem__(self,i):
x = dfdiff.loc[i:i+WINDOW_SIZE-1,:]
feature = torch.tensor(x.values)
y = dfdiff.loc[i+WINDOW_SIZE,:]
label = torch.tensor(y.values)
return (feature,label)
ds_train = Covid19Dataset()
#数据较小,可以将全部训练数据放入到一个batch中,提升性能
dl_train = DataLoader(ds_train,batch_size = 38)
这就是比较常规的时序建模的方式。下面这一个是非线性自回归的一个自定义数据集的方式, 可能更加复杂一点, 所谓非线性自回归建模, 既涉及到普通的结构化数据, 也涉及到了时序数据, 比如这样的数据集:
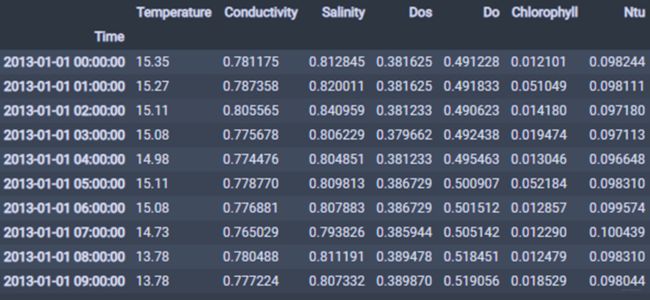
我要预测未来七天的温度, 既涉及到了温度本身的特征, 也涉及到了其他特征来影响温度, 这个问题的建模思路和上面类似, 也是基于过去一段时间的所有特征, 但是写法和上面不同, 不是直接一个滑动窗口去切, 而是先把这些滞后特征做成一行, 然后再进行shape转换:
class TemperatureDataSet(Dataset):
def __init__(self, n_in, n_out):
"""
函数用途: 加载数据并且初始化
参数说明:
n_in: 用多长时间进行预测
n_out: 预测多长时间
"""
# 读取数据,去除缺失严重属性,插值
df = pd.read_csv("dsw.csv", index_col=0)
df.drop(['pH'], axis=1, inplace=True)
df.index = pd.to_datetime(df.index)
df.interpolate(method='time', inplace=True) # 时间插值
# 标准化
self.ss = StandardScaler()
self.std_data = self.ss.fit_transform(df['Temperature'].values.reshape(-1, 1))
# 转化为监督测试集
data = self.series_to_supervised(self.std_data, n_in, n_out)
re_data = self.series_to_supervised(df['Temperature'].values.reshape(-1, 1), n_in, n_out)
self.x = torch.from_numpy(data.iloc[:, :n_in].values).view(-1, n_in, 1)
self.y = torch.from_numpy(re_data.iloc[:, n_in:].values).view(-1, n_out, 1)
self.len = self.x.shape[0]
def __len__(self):
return self.len
def __getitem__(self, item):
return self.x[item, :].type(torch.FloatTensor), self.y[item, :].type(torch.FloatTensor)
def series_to_supervised(self, data, n_in=1, n_out=1, dropnan=True):
"""
函数用途:将时间序列转化为监督学习数据集。
参数说明:
data: 观察值序列,数据类型可以是 list 或者 NumPy array。
n_in: 作为输入值(X)的滞后组的数量。
n_out: 作为输出值(y)的观察组的数量。
dropnan: Boolean 值,确定是否将包含 NaN 的行移除。
返回值:
经过转换的用于监督学习的 Pandas DataFrame 序列。
"""
n_vars = 1 if type(data) is list else data.shape[1]
df = pd.DataFrame(data)
cols, names = list(), list()
# 输入序列 (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j + 1, i)) for j in range(n_vars)]
# 预测序列 (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j + 1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j + 1, i)) for j in range(n_vars)]
# 将所有列拼合
agg = pd.concat(cols, axis=1)
agg.columns = names
# drop 掉包含 NaN 的行
if dropnan:
agg.dropna(inplace=True)
return agg
data_set = TemperatureDataSet(n_in=10, n_out=5)
这个比较复杂的就是滞后特征的提取, 这个灵活性更高, 可以series_to_supervised函数里面做各种处理工作。
5. 图片数据建模
在Pytorch中构建图片数据管道通常有两种方法。
- 第一种是使用
torchvision中的datasets.ImageFolder来读取图片然后用DataLoader来并行加载。 - 第二种是通过继承
torch.utils.data.Dataset实现用户自定义读取逻辑然后用DataLoader来并行加载。
下面我们分别来看一下:
-
torchvision中的datasets.ImageFloder
torchvision是一个计算机视觉工具包,我们需要在安装Pytorch后单独安装一下这个包。 在torchvision中,有三个主要的模块:torchvision.transforms: 常用的图像预处理方法, 比如标准化,中心化,旋转,翻转等操作trochvision.datasets: 常用的数据集的dataset实现, MNIST, CIFAR-10, ImageNet等torchvision.models: 常用的模型预训练, AlexNet, VGG, ResNet, GoogLeNet等。
我们这里拿cifar2数据集来看一下如何使用, 这是个分类数据集, 训练集有airplane和automobile图片各5000张,测试集有airplane和automobile图片各1000张, 任务的目标是训练一个模型来对飞机airplane和机动车automobile两种图片进行分类。数据集的文件结构是下面这个样子:
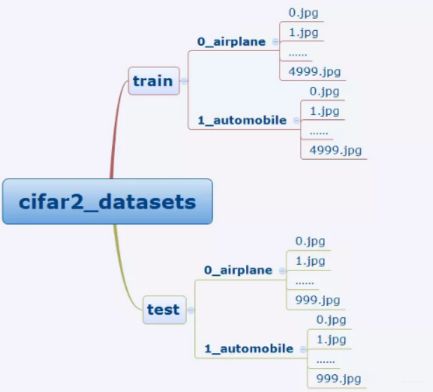
我们有ImageFloder来读取数据集, 逻辑是这样, 首先, 我们要先定义一下数据的转换格式, 因为我们知道, 图片数据的话, 可能会涉及到各种数据预处理, 比如转成张量, 裁剪, 旋转, 变换等操作, 所以我们先定义这些操作, 然后在读取数据集的时候, 通过transfrom参数把这些处理传入, 就可以直接处理。# 定义预处理方式 当然Compose里面还可以放更多的处理方式, 具体有哪些, 我Pytorch笔记三里面整理的很详细 transform_train = transforms.Compose( [transforms.ToTensor()]) transform_valid = transforms.Compose( [transforms.ToTensor()]) # 然后就可以直接读取数据 ds_train = datasets.ImageFolder("./data/cifar2/train/", transform = transform_train,target_transform= lambda t:torch.tensor([t]).float()) ds_valid = datasets.ImageFolder("./data/cifar2/test/", transform = transform_train,target_transform= lambda t:torch.tensor([t]).float()) # 封装成数据管道 dl_train = DataLoader(ds_train,batch_size = 50,shuffle = True,num_workers=3) dl_valid = DataLoader(ds_valid,batch_size = 50,shuffle = True,num_workers=3)这种方式, 必须按照文件的那种方式组织图片。
-
用户自定义读取逻辑然后用
DataLoader来进行加载
这个拿之前人民币二分类的例子来看一下, 这里的数据组织形式和上面一样:

类别分开, 每一类里面是图片数据。这时候, 我们首先要定义一个自己写的Dataset类来读取数据, 生成数据集, 实现逻辑依然是__getitem__里面可以拿到某个索引对应的数据, 注意这个函数接收的参数是一个索引, 我们返回的是这个索引对应的数据。class RMBDataset(Dataset): def __init__(self, data_dir, transform=None): """ rmb面额分类任务的Dataset :param data_dir: str, 数据集所在路径 :param transform: torch.transform,数据预处理 """ self.label_name = { "1": 0, "100": 1} self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本 self.transform = transform def __getitem__(self, index): path_img, label = self.data_info[index] img = Image.open(path_img).convert('RGB') # 0~255 if self.transform is not None: img = self.transform(img) # 在这里做transform,转为tensor等等 return img, label def __len__(self): return len(self.data_info) @staticmethod def get_img_info(data_dir): data_info = list() for root, dirs, _ in os.walk(data_dir): # 遍历类别 for sub_dir in dirs: img_names = os.listdir(os.path.join(root, sub_dir)) img_names = list(filter(lambda x: x.endswith('.jpg'), img_names)) # 遍历图片 for i in range(len(img_names)): img_name = img_names[i] path_img = os.path.join(root, sub_dir, img_name) label = rmb_label[sub_dir] data_info.append((path_img, int(label))) return data_info下面就使用自定义的Datasets, 构建数据管道:
## transforms模块,进行数据预处理 norm_mean = [0.485, 0.456, 0.406] norm_std = [0.229, 0.224, 0.225] train_transform = transforms.Compose([ transforms.Resize((32, 32)), transforms.RandomCrop(32, padding=4), transforms.ToTensor(), transforms.Normalize(norm_mean, norm_std), ]) valid_transform = transforms.Compose([ transforms.Resize((32, 32)), transforms.ToTensor(), transforms.Normalize(norm_mean, norm_std), ]) ## 构建MyDataset实例 train_data = RMBDataset(data_dir=train_dir, transform=train_transform) valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform) # 构建DataLoader train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
图像数据比较简单的是第一种方式, 比较灵活的是第二种方式。
6. 文本数据建模
文本数据预处理较为繁琐,包括中文切词(本示例不涉及),构建词典,编码转换,序列填充,构建数据管道等等。Pytorch中对文本数据建模一般使用两种方式:
torchtext包, 这个包功能非常强大, 可以构建文本分类,序列标注,问答模型,机器翻译等NLP任务的数据集。- 自定义Dataset, 这个处理起来就比较繁琐
依然是和图片一样, 第一种方式比较简单, 大部分工作包里面都实现了, 第二个方式得需要自己实现, 所以能用第一个还是用第一个。
下面用IMDB数据集来演示一下这两种情况的建模方式, imdb数据集的目标是根据电影评论的文本内容预测评论的情感标签。
训练集有20000条电影评论文本,测试集有5000条电影评论文本,其中正面评论和负面评论都各占一半。数据长这样:

下面分别来演示一下:
-
torchtext包进行文本分类数据建模
这个包同样的, 使用之前需要安装, 具体使用可以参考这篇文章, 这里只看一下torchtext常见的API:torchtext.data.Example: 用来表示一个样本,数据和标签torchtext.vocab.Vocab: 词汇表,可以导入一些预训练词向量torchtext.data.Datasets: 数据集类,__getitem__返回 Example实例,torchtext.data.TabularDataset是其子类。torchtext.data.Field: 用来定义字段的处理方法(文本字段,标签字段)创建 Example时的预处理,batch 时的一些处理操作。torchtext.data.Iterator: 迭代器,用来生成 batchtorchtext.datasets: 包含了常见的数据集.
这里的操作逻辑一般是先从Field里面定义一些字段预处理的方式, 然后用Datasets里面的子类来构建数据集,然后构建词典, 把数据用Iterator封装成数据迭代器。
MAX_WORDS = 10000 MAX_LEN = 200 BATCH_SIZE = 20 # string.punctuation表示所有的标点字符, 下面这句话就是把每个句子里面的所有标点符号都替换成空字符, 然后按照空格进行分词 tokenize = lambda x: re.sub('[%s]' % string.punctuation, "", x).split(" ") # 字符串的替换 def filterLowFreqWords(arr, vocab): arr = [[x if x<MAX_WORDS else 0 for x in example] for example in arr] return arr # 定义各个字段的预处理方法 # sequential告诉它输入是序列的形式, lower等于True, 转成小写 postprocessing=False这块不知道啥意思 TEXT = torchtext.data.Field(sequential=True, tokenize=tokenize, lower=True, fix_length=MAX_LEN, postprocessing=filterLowFreqWords) LABEL = torchtext.data.Field(sequential=False, use_vocab=False) #field在默认的情况下都期望一个输入是一组单词的序列,并且将单词映射成整数。这个映射被称为vocab。 #如果一个field已经被数字化了并且不需要被序列化,可以将参数设置为use_vocab=False以及sequential=False。 # 构建表格型dataset # torchtext.data.TabularDataset可读取csv, tsv, json等格式 ds_train, ds_test = torchtext.data.TabularDataset.splits( path='./data/imdb', train='train.tsv', test='test.tsv', format='tsv', fields=[('label', LABEL), ('text', TEXT)], skip_header=False ) # 构建词典 TEXT.build_vocab(ds_train) # 构建数据管道迭代器 train_iter, test_iter = torchtext.data.Iterator.splits( (ds_train, ds_test), sort_within_batch=True, sort_key=lambda x: len(x.text), batch_sizes=(BATCH_SIZE, BATCH_SIZE) ) # 查看数据 for batch in train_iter: features = batch.text labels = batch.label print(features) print(features.shape) print(labels) break这个包在第二个系列Pytorch入门+实战系列四: Pytorch语言模型里面也用到过, 那里面也对这个逻辑做了更加详细的解释。
-
自定义文本数据集
这个就有点麻烦了, 大概思路如下:首先,对训练集文本分词构建词典。然后将训练集文本和测试集文本数据转换成token单词编码。接着将转换成单词编码的训练集数据和测试集数据按样本分割成多个文件,一个文件代表一个样本。最后,我们可以根据文件名列表获取对应序号的样本内容,从而构建Dataset数据集。# 定义一些变量 MAX_WORDS = 10000 # 仅考虑最高频的10000个词 MAX_LEN = 200 # 每个样本保留200个词的长度 BATCH_SIZE = 20 train_data_path = 'data/imdb/train.tsv' test_data_path = 'data/imdb/test.tsv' train_token_path = 'data/imdb/train_token.tsv' test_token_path = 'data/imdb/test_token.tsv' train_samples_path = 'data/imdb/train_samples/' test_samples_path = 'data/imdb/test_samples/'首先, 我们构建词典, 并保留最高频个词:
##构建词典 word_count_dict = { } #清洗文本 def clean_text(text): lowercase = text.lower().replace("\n"," ") # 转成小写 stripped_html = re.sub('
', ' ',lowercase) # 正则修改 cleaned_punctuation = re.sub('[%s]'%re.escape(string.punctuation),'',stripped_html) # 去掉其他符号 return cleaned_punctuation with open(train_data_path,"r",encoding = 'utf-8') as f: for line in f: label,text = line.split("\t") # label和句子分开 cleaned_text = clean_text(text) # 清洗文本 for word in cleaned_text.split(" "): word_count_dict[word] = word_count_dict.get(word,0)+1 # 统计单词频数 df_word_dict = pd.DataFrame(pd.Series(word_count_dict,name = "count")) df_word_dict = df_word_dict.sort_values(by = "count",ascending =False) df_word_dict = df_word_dict[0:MAX_WORDS-2] # df_word_dict["word_id"] = range(2,MAX_WORDS) #编号0和1分别留给未知词和填充 word_id_dict = df_word_dict["word_id"].to_dict()利用构建好的词典, 将文本转成token序号
#转换token # 填充文本 def pad(data_list,pad_length): padded_list = data_list.copy() if len(data_list)> pad_length: # 如果句子里面的单词个数比字典长度大, 那就取后面字典长度个大小 padded_list = data_list[-pad_length:] if len(data_list)< pad_length: # 如果句子小, 前面填充1, 弄到字典长度大小 padded_list = [1]*(pad_length-len(data_list))+data_list return padded_list def text_to_token(text_file,token_file): with open(text_file,"r",encoding = 'utf-8') as fin,\ open(token_file,"w",encoding = 'utf-8') as fout: for line in fin: label,text = line.split("\t") cleaned_text = clean_text(text) word_token_list = [word_id_dict.get(word, 0) for word in cleaned_text.split(" ")] # 把单词转换成词典中的位置 pad_list = pad(word_token_list,MAX_LEN) out_line = label+"\t"+" ".join([str(x) for x in pad_list]) fout.write(out_line+"\n") text_to_token(train_data_path,train_token_path) text_to_token(test_data_path,test_token_path)接着将token文本按照样本分割, 每个文件存放一个样本的数据
# 分割样本 import os if not os.path.exists(train_samples_path): os.mkdir(train_samples_path) if not os.path.exists(test_samples_path): os.mkdir(test_samples_path) def split_samples(token_path,samples_dir): with open(token_path,"r",encoding = 'utf-8') as fin: i = 0 for line in fin: with open(samples_dir+"%d.txt"%i,"w",encoding = "utf-8") as fout: fout.write(line) i = i+1 split_samples(train_token_path,train_samples_path) split_samples(test_token_path,test_samples_path)一切准备就绪,我们可以创建数据集Dataset, 从文件名称列表中读取文件内容了。
class imdbDataset(Dataset): def __init__(self,samples_dir): self.samples_dir = samples_dir self.samples_paths = os.listdir(samples_dir) def __len__(self): return len(self.samples_paths) def __getitem__(self,index): path = self.samples_dir + self.samples_paths[index] with open(path,"r",encoding = "utf-8") as f: line = f.readline() label,tokens = line.split("\t") label = torch.tensor([float(label)],dtype = torch.float) feature = torch.tensor([int(x) for x in tokens.split(" ")],dtype = torch.long) return (feature,label) ds_train = imdbDataset(train_samples_path) ds_test = imdbDataset(test_samples_path) dl_train = DataLoader(ds_train,batch_size = BATCH_SIZE,shuffle = True,num_workers=4) dl_test = DataLoader(ds_test,batch_size = BATCH_SIZE,num_workers=4) for features,labels in dl_train: print(features) print(labels) break这里的这种数据长这样:
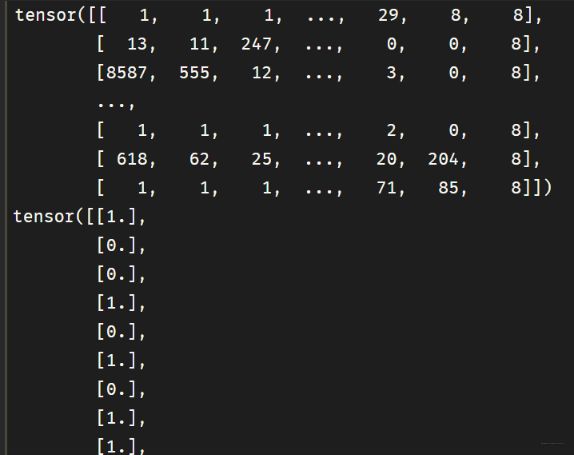
features里面的每一行是一个句子, 只不过这里都转成了单词的索引表示, 而labell里面的每一个就是句子对应的分类, 好评和差评。 这种方式比较麻烦的就是前面的预处理部分, 就是把数据进行切割, 然后构建词典, 存到文件等很繁琐, 并且对于不同的数据处理方式也不一样。 所以能用第一种尽量用第一种, 第二种做个参考。
7. 总结
终于完事了, 这篇文章的篇幅很长, 但自我感觉还是挺有条理的, 不信? 带你梳理一下, 首先这篇文章是围绕着数据准备进行的, 因为Pytorch里面, 一般是先把数据构建成数据管道迭代器的方式, 然后为模型的训练调用数据所服务, 而把数据构建成管道迭代器又应该视具体的数据类型而论, 不同的数据类型构建方式不同。 所以一开始, 首先回顾了一下Pytorch里面的Datasets和DataLoader类的原理和联系, 因为Pytorch里面准备数据一般用到的就是这两个东西, 所以非常非常重要。如果不明白原理, 就看这一块。 而下面就是针对不同的数据, 整理了一下构建数据管道的方式并给出了实例, 分别从结构化数据, 时序数据,图像数据, 文本数据四个方面。 这几类数据基本上包括了我们现在处理的大部分数据了吧, 反正目前我还没有见过在这四类之外的。 这几块都是相互独立, 互不影响。
整理最后这几篇是为了在具体用的时候方便查阅, 所以尽管文章比较长, 但是不需要整篇文章的进行浏览, 最后这几篇文章都是一些类似模板一样的东西, 只要经过前面的系统学习Pytorch的10篇文章把Pytorch的原理弄懂, 然后就可以很轻松的把这些模板迁移到自己的数据集上去, 所以只需要知道我们面临的数据是什么类型的, 然后查相应的版块即可。 当然我也没有一下子把这些东西都记住, 所以我才整理到一块方便日后回看回练, 也希望这些内容能帮助到你, 那就巧了哈哈
这篇文章里面的数据和代码, 可以参考下面的第一篇链接, 我基本上是参考的这个, 只不过把里面的知识进行了抽取和整合, 方便我自己日后查阅。 如果想系统的学一遍, 可以跟着走一遍, 只需20天。
参考:
- https://github.com/lyhue1991/eat_pytorch_in_20_days
- 系统学习Pytorch笔记三:Pytorch数据读取机制(DataLoader)与图像预处理模块(transforms)