【基础算法】(11)树的概念及相关算法(一)
【基础算法】(11)树的概念及相关算法
Auther: Thomas Shen
E-mail: [email protected]
Date: 2017/12/21
All Copyrights reserved !
-
-
- 基础算法11树的概念及相关算法
- 基本概念
- 二叉树
- 1 二叉树基本概念
- 2 满二叉树
- 3 完全二叉树
- 4 二叉树的性质
- 5 二叉树的存储方式
- 51 顺序存储
- 52 链式存储
- 6 二叉树的遍历
- 二叉排序树B树
- 平衡二叉树
- 霍夫曼编码
- References
- 基础算法11树的概念及相关算法
-
1. 基本概念:
树(tree)是n(n>=0)个结点的有穷集。n=0时称为空树。在任意一个非空树中:(1)每个元素称为结点(node);(2)仅有一个特定的结点被称为根结点或树根(root)。(3)当n>1时,其余结点可分为m(m≥0)个互不相交的集合T1,T2,……Tm,其中每一个集合Ti(1<=i<=m)本身也是一棵树,被称作根的子树(subtree)。
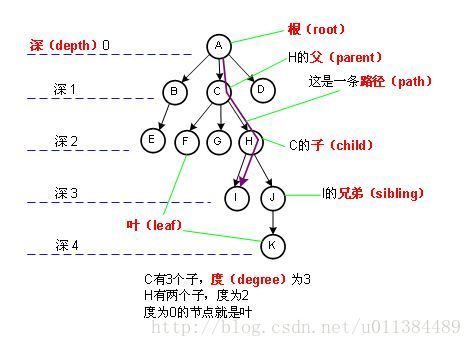
2. 二叉树:
2.1 二叉树基本概念:
二叉树(Binary Tree)是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。
二叉树的特点:
1. 二叉树不存在度大于2的结点。
2. 二叉树的子树有左右之分,次序不能颠倒。斜树:
所有的结点都只有左子树的二叉树叫左斜树。所有的结点都只有右子树的二叉树叫右斜树。这两者统称为斜树。
斜树每一层只有一个结点,结点的个数与二叉树的深度相同。其实斜树就是线性表结构。

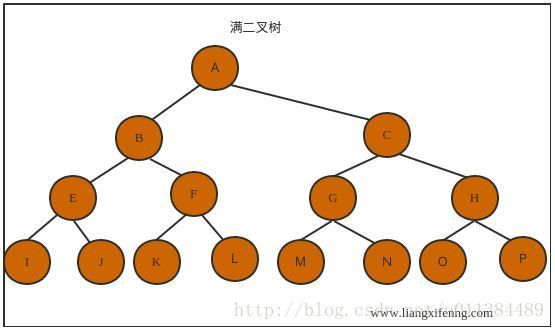
2.2 满二叉树:
在一棵二叉树中,如果所有分支结点都存在左子树和右子树,并且所有叶子都在同一层上,这样的二叉树称为满二叉树。
满二叉树具有如下特点:
1. 叶子只能出现在最下一层
2. 非叶子结点的度一定是2
3. 同样深度的二叉树中,满二叉树的结点个数最多,叶子数最多。
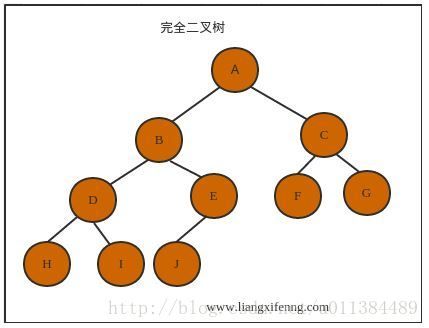
2.3 完全二叉树:
若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
完全二叉树的特点:
1. 叶子结点只能出现在最下两层
2. 最下层叶子在左部并且连续
3. 同样结点数的二叉树,完全二叉树的深度最小
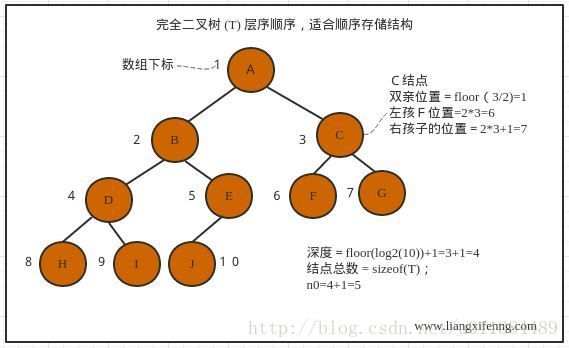
2.4 二叉树的性质:
- 每层结点数:二叉树的第i层上最多有 (n=2^i-1)个结点,(i>=1);
- 所有结点数:深度为K的二叉树最多有(n=2^K-1)个结点,(K>=1) ;
- 对于任意一棵二叉树,n0 =叶子结点总数、n1=度为1的结点总数、n2=度为2的结点总数、n=总结点数:n0=n2+1
- 分支线总数=n-1=n1+2n2;
- n=n0+n1+n2;
- n0+n1+n2-1 = n1+2n2 => n0=n2+1;
- 满二叉树的深度:log2(n+1);
完全二叉树的深度:向下取整数(log2n)+1;
因为完全二叉树的所有叶子结点只能出现在最下两层,并且倒数第二层是满的情况,所以倒数第二层所在深度+1也是完全二叉树的深度;
- 层序遍历二叉树的顺序,对于任意一个结点编号 i(1<=i<=n),i可以理解为数组下标+1,因为数组下标是从0开始的:
- 双亲结点编号:向下取整(i/2);
- 如果2i>n,则该结点无左孩子,否则左孩子结点是 2i;
- 如果2i+1>n,则该结点无右孩子,否则右孩子结点是2i+1;
2.5 二叉树的存储方式:
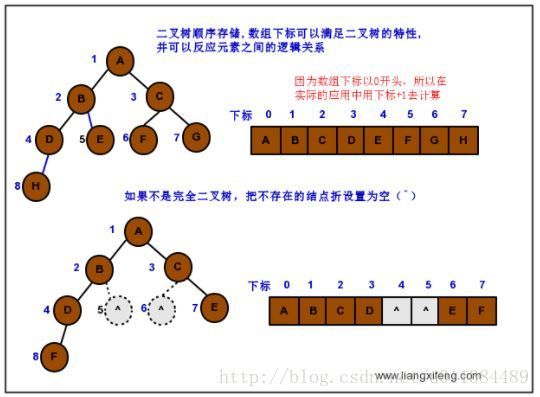
2.5.1 顺序存储:
顺序存储,方便查询操作,并且可以根据层序遍历,合理的利用以上特性;
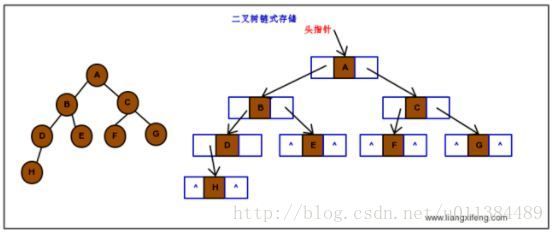
2.5.2 链式存储:
链式存储,方便新增,删除操作;结构为数据域+左孩子指针+右孩子指针 (二叉链表),如果有必要的情况下可以添加双亲指针,指向结点的双亲(三叉链表),这都是根据业务需求灵活控制的;
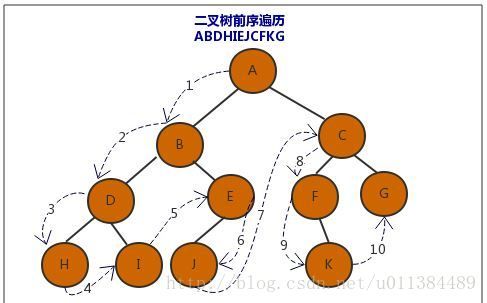
2.6 二叉树的遍历:
主要针对链式存储,按着一定顺序访问各个结点,保证每个结点仅被访问 一次,以下是根据结点访问顺序定义的;
前序:先访问根结点 -> 遍历左子树 -> 遍历右子树;先访问根结点
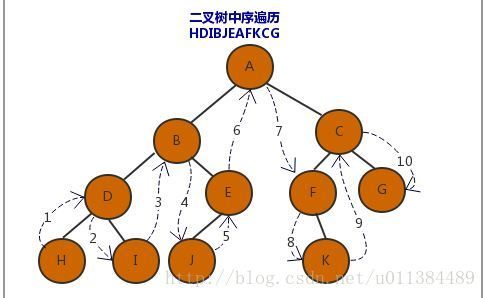
中序:遍历左子树 -> 访问根结点 -> 遍历右子树;中间访问根结点
后序:遍历左子树 -> 遍历右子树 -> 后访问根结点;后访问根结点
层序:自上而下,从左到右逐层访问结点;

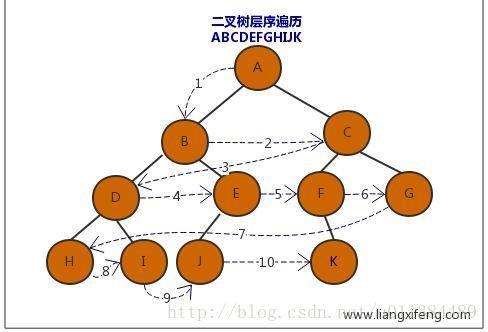
推导:
1. 已知前序、中序,可以唯一确定一个二叉树;
2. 已知后序、中序,可以唯一确定一个二叉树;
3. 但是已知前序、后序却不能确定一棵二叉树;
3 二叉排序树(B树):
http://blog.csdn.net/sup_heaven/article/details/39313731
二叉排序树(二叉搜索树,BST树):二叉树中,每个节点都不比它左子树的任意元素小,而且不比它的右子树的任意元素大。又叫二叉搜索树。
特性:
1. 所有非叶子结点至多拥有两个儿子(Left和Right);
2. 所有结点存储一个关键字;
3. 非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
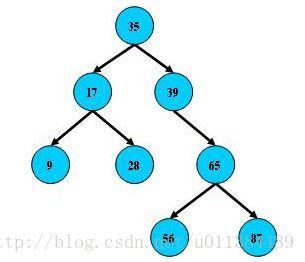
BST树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
如果BST树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变BST树结构(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:

但BST树在经过多次插入与删除后,有可能导致不同的结构:

右边也是一个BST树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的树结构索引;所以,使用BST树还要考虑尽可能让BST树保持左图的结构,和避免右图的结构,也就是所谓的“平衡”问题;
4. 平衡二叉树:
http://www.cnblogs.com/suimeng/p/4560056.html
平衡二叉树(Balanced Binary Tree)是二叉查找树的一个进化体,也是第一个引入平衡概念的二叉树。1962年,G.M. Adelson-Velsky 和 E.M. Landis发明了这棵树,所以它又叫AVL树。
平衡二叉树要求对于每一个节点来说,它的左右子树的高度之差不能超过1,如果插入或者删除一个节点使得高度之差大于1,就要进行节点之间的旋转,将二叉树重新维持在一个平衡状态。
这个方案很好的解决了二叉查找树退化成链表的问题,把插入,查找,删除的时间复杂度最好情况和最坏情况都维持在O(logN)。但是频繁旋转会使插入和删除牺牲掉O(logN)左右的时间,不过相对二叉查找树来说,时间上稳定了很多。
当AVL树插入、删除时失衡的调整主要是通过旋转最小失衡子树来实现的。
5. 霍夫曼编码:
http://blog.csdn.net/xgf415/article/details/52628073
霍夫曼编码(Huffman Coding)使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
霍夫曼编码的具体步骤如下:
1.将信源符号的概率按减小的顺序排队。
2. 把两个最小的概率相加,并继续这一步骤,始终将较高的概率分支放在右边,直到最后变成概率1。
3. 画出由概率1处到每个信源符号的路径,顺序记下沿路径的0和1,所得就是该符号的霍夫曼码字。
4. 将每对组合的左边一个指定为0,右边一个指定为1(或相反)
例:现有一个由5个不同符号组成的30个符号的字符串:
BABACAC ADADABB CBABEBE DDABEEEBB
1. 首先计算出每个字符出现的次数(概率);
2. 把出现次数(概率)最小的两个相加,并作为左右子树,重复此过程,直到概率值为1;
3. 将每个二叉树的左边指定为0,右边指定为1;
4. 沿二叉树顶部到每个字符路径,获得每个符号的编码.
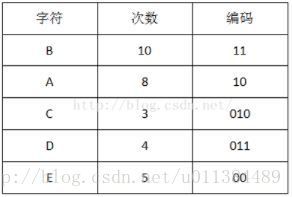

我们可以看到出现次数(概率)越多的会越在上层,编码也越短,出现频率越少的就越在下层,编码也越长。当我们编码的时候,我们是按“bit”来编码的,解码也是通过bit来完成,如果我们有这样的bitset “10111101100″ 那么其解码后就是 “ABBDE”。所以,我们需要通过这个二叉树建立我们Huffman编码和解码的字典表。
这里需要注意的是,Huffman编码使得每一个字符的编码都与另一个字符编码的前一部分不同,不会出现像’A’:00, ’B’:001,这样的情况,解码也不会出现冲突。
霍夫曼编码知识点:
- 路径:结点之间的分支构成两个结点之间的路径;
- 路径长度:两个结点之间的分支数量;
- 树的路径长度:从树根到每一结点的路径长度之和;
- 叶子结点带权路径长度:叶子结点到根结点的路径长度*叶子结点权值;
- 树的带权路径长度 WPL: 所有叶子结点带权路径长度之和;
- 赫夫曼树 : WPL 最小的二叉树。也称最优二叉树;霍夫曼编码的局限性:
利用霍夫曼编码,每个符号的编码长度只能为整数,所以如果源符号集的概率分布不是2负n次方的形式,则无法达到熵极限;输入符号数受限于可实现的码表尺寸;译码复杂;需要实现知道输入符号集的概率分布;没有错误保护功能。
References. :
- [ 1 ]. https://www.cnblogs.com/wangyingli/p/5933257.html
- [ 2 ]. 二叉树
- [ 3 ]. B树、B-树、B+树、B*树
- [ 4 ]. 平衡二叉树,AVL树之图解篇
- [ 5 ]. 红黑树(一)之 原理和算法详细介绍
- [ 6 ]. 霍夫曼编码(Huffman Coding)
- [ 7 ]. 数据结构中常见的树(BST二叉搜索树、AVL平衡二叉树、RBT红黑树、B-树、B+树、B*树)
- [ 8 ]. 二叉树,完全二叉树,满二叉树,二叉排序树,平衡二叉树,红黑树,B数,B-树,B+树,B*树(一)