Cortex-M3异常和中断(NVIC)
Cortex-M3支持大量异常,包括16-4-1=11个系统异常,和最多240个外部中断——简称IRQ。具体使用了这240个中断源中的多少个,则由芯片制造商决定。由外设产生的中断信号,除了SysTick的之外,全都连接到NVIC的中断输入信号线。典型情况下,处理器一般支持16到32个中断,当然也有在此之外的。
作为中断功能的强化,NVIC还有一条NMI输入信号线。NMI究竟被拿去做什么,还要视处理器的设计而定。在多数情况下,NMI会被连接到一个看门狗定时器,有时也会是电压监视功能块,以便在电压掉至危险级别后警告处理器。NMI可以在任何时间被激活,甚至是在处理器刚刚复位之后。

当CM3内核响应了一个发生的异常后,对应的异常服务例程(ESR)就会执行。为了决定ESR的入口地址,CM3使用了“向量表查表机制”。这里使用一张向量表。向量表其实是一个WORD(32位整数)数组,每个下标对应一种异常,该下标元素的值则是该ESR的入口地址。向量表在地址空间中的位置是可以设置的,通过NVIC中的一个重定位寄存器来指出向量表的地址。在复位后,该寄存器的值为0。因此,在地址0处必须包含一张向量表,用于初始时的异常分配。

异常向量表
在STM32中异常向量表在启动文件中已经写好的了,我们只需要在对应的中断函数中写自己的处理函数就行了。
向量中断控制器,简称NVIC,是Cortex-M3不可分离的一部分,它与CM3内核的逻辑紧密耦合,有一部分甚至水乳交融在一起。NVIC与CM3内核同声相应,同气相求,相辅相成,里应外合,共同完成对中断的响应。NVIC的寄存器以存储器映射的方式来访问,除了包含控制寄存器和中断处理的控制逻辑之外,NVIC还包含了MPU、SysTick定时器以及调试控制相关的寄存器。
NVIC共支持1至240个外部中断输入(通常外部中断写作IRQs)。具体的数值由芯片厂商在设计芯片时决定。此外,NVIC还支持一个“永垂不朽”的不可屏蔽中断(NMI)输入。NMI的实际功能亦由芯片制造商决定。在某些情况下,NMI无法由外部中断源控制。
NVIC的访问地址是0xE000_E000。所有NVIC的中断控制/状态寄存器都只能在特权级下访问。不过有一个例外——软件触发中断寄存器可以在用户级下访问以产生软件中断。所有的中断控制/状态寄存器均可按字/半字/字节的方式访问。此外,还有几个中断掩蔽寄存器也与中断控制密切相关。
中断配置基础
每个外部中断都在NVIC的下列寄存器中“挂号”:
使能与除能寄存器
悬起与“解悬”寄存器
优先级寄存器
活动状态寄存器
另外,下列寄存器也对中断处理有重大影响
异常掩蔽寄存器(PRIMASK, FAULTMASK以及BASEPRI)
向量表偏移量寄存器
软件触发中断寄存器
优先级分组位段
使能与除能寄存器
中断的使能与除能分别使用各自的寄存器来控制——这与传统的,使用单一比特的两个状态来表达使能与除能是不同的。CM3中可以有240对使能位/除能位(SETENA位/CLRENA位),每个中断拥有一对。这240个对子分布在8对32位寄存器中(最后一对没有用完)。欲使能一个中断,我们需要写1到对应SETENA的位中;欲除能一个中断,你需要写1到对应的CLRENA位中。如果往它们中写0,则不会有任何效果。写零无效是个很关键的设计理念:通过这种方式,使能/除能中断时只需把“当事位”写成1,其它的位可以全部为零。
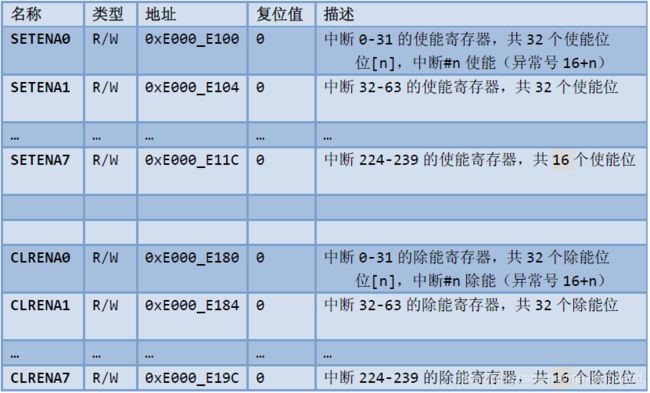
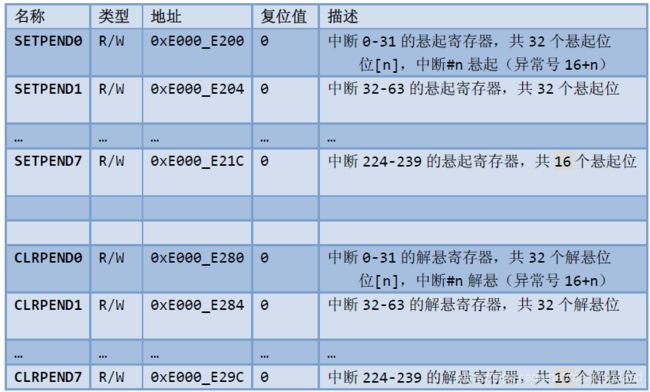
悬起与“解悬”寄存器
如果中断发生时,正在处理同级或高优先级异常,或者被掩蔽,则中断不能立即得到响应。此时中断被悬起。中断的悬起状态可以通过“中断设置悬起寄存器(SETPEND)”和“中断悬起清除寄存器(CLRPEND)”来读取,还可以写它们来手工悬起中断。
悬起寄存器和“解悬”寄存器也可以有8对,其用法和用量都与前面介绍的使能/除能寄存器相同。
优先级
每个外部中断都有一个对应的优先级寄存器,每个寄存器占用8位,但是CM3允许在最“粗线条”的情况下,只使用最高3位。4个相临的优先级寄存器拼成一个32位寄存器。如前所述,根据优先级组的设置,优先级可以被分为高低两个位段,分别是抢占优先级和亚优先级。优先级寄存器都可以按字节访问,当然也可以按半字/字来访问。有意义的优先级寄存器数目由芯片厂商实现的中断数目决定。
活动状态
每个外部中断都有一个活动状态位。在处理器执行了其ISR的第一条指令后,它的活动位就被置1,并且直到ISR返回时才硬件清零。由于支持嵌套,允许高优先级异常抢占某个ISR。然而,哪怕中断被抢占,其活动状态也依然为1(请仔细琢磨前文讲到的“直到ISR返回时才清零)。活动状态寄存器的定义,与前面讲的使能/除能和悬起/解悬寄存器相同,只是不再成对出现。
PRIMASK用于除能在NMI和硬fault之外的所有异常,它有效地把当前优先级改为0(可编程优先级中的最高优先级)。该寄存器可以通过MRS和MSR方式访问。
软件中断,包括手工产生的普通中断,能以多种方式产生。最简单的就是使用相应的SETPEND寄存器;而更专业更快捷的作法,则是通过使用软件触发中断寄存器STIR。
当CM3开始响应一个中断时,会在它小小的体内奔涌起三股暗流:
入栈: 把8个寄存器的值压入栈
取向量:从向量表中找出对应的服务程序入口地址
选择堆栈指针MSP/PSP,更新堆栈指针SP,更新连接寄存器LR,更新程序计数器PC
响应异常的第一个行动,就是自动保存现场的必要部分:依次把xPSR, PC, LR, R12以及R3-R0由硬件自动压入适当的堆栈中:如果当响应异常时,当前的代码正在使用PSP,则压入PSP,也就是使用进程堆栈;否则就压入MSP,使用主堆栈。一旦进入了服务例程,就将一直使用主堆栈。
嵌套的中断
在CM3内核以及NVIC的深处,就已经内建了对中断嵌套的全力支持,根本无需使用汇编去写封皮代码(wrapper code)。事实上,我们要做的就只是为每个中断适当地建立优先级,不用再操心别的。表现在:
第一、 NVIC和CM3处理器会根据优先级的设置来控制抢占与嵌套行为。因此,在某个异常正在响应时,所有优先级不高于它的异常都不能抢占之,而且它自己也不能抢占自己。
第二、 有了自动入栈和出栈,就不用担心在中断发生嵌套时,会使寄存器的数据损毁,从而可以放心地执行服务例程。
然而,有一件事情却必须更加一丝不苟地处理了,否则有功能紊乱甚至死机的危险。这就是计算主堆栈容量的最小安全值。我们已经知道,所有服务例程都只使用主堆栈。所以当中断嵌套加深时,对主堆栈的压力会增大:每嵌套一级,就至少再需要8个字,即32字节的堆栈空间——而且这还没算上ISR对堆栈的额外需求,并且何时嵌套多少级也是不可预料的。如果主堆栈的容量本来就已经所剩无几了,中断嵌套又突然加深,则主堆栈有被用穿的凶险。这就好像已经表现出了高血压危象的时候,情绪又一激动,就容易中风一般。中风是一大杀手,而堆栈溢出同样是很致命的,它会使入栈数据与主堆栈前面的数据区发生混迭,使这些数据被破坏;若在服务例程返回前混迭区的数据又被更改了,则堆栈内容被破坏。这么一来在执行中断返回后,系统极可能功能紊乱,甚至当场被一击秒杀——程序跑飞/死机!
另一个要注意的,是相同的异常是不允许重入的。因为每个异常都有自己的优先级,并且在异常处理期间,同级或低优先级的异常是要阻塞的。因此对于同一个异常,只有在上次实例的服务例程执行完毕后,方可继续响应新的请求。由此可知,在SVC服务例程中,就不得再使用SVC指令,否则将fault伺候。
咬尾中断
CM3为缩短中断延迟做了很多努力,第一个要提的,就是新增的“咬尾中断”(Tail-Chaining)机制。
当处理器在响应某异常时,如果又发生其它异常,但它们优先级不够高,则被阻塞——这个我们已经知道。那么在当前的异常执行返回后,系统处理悬起的异常时,倘若还是先POP,然后又把POP出来的内容PUSH回去,这不成了砸锅炼铁再铸锅,白白浪费CPU时间吗,可知还有多少紧急的事件悬而未决呀!正因此,CM3不会傻乎乎地POP这些寄存器,而是继续使用上一个异常已经PUSH好的成果,消灭了这种铺张浪费。这么一来,看上去好像后一个异常把前一个的尾巴咬掉了,前前后后只执行了一次入栈/出栈操作。于是,这两个异常之间的“时间沟”变窄了很多
晚到(的高优先级)异常
CM3的中断处理还有另一个机制,它强调了优先级的作用,这就是“晚到的异常处理”。当CM3对某异常的响应序列还处在早期:入栈的阶段,尚未执行其服务例程时,如果此时收到了高优先级异常的请求,则本次入栈就成了为高优先级中断所做的了——入栈后,将执行高优先级异常的服务例程。