Spleeter工具简单分析
源码地址:https://github.com/deezer/spleeter
pytorch版本:https://github.com/generalwave/spleeter.pytorch
前言
spleeter是一款基于深度学习的多音轨分离软件。其使用python3.7基于tensorflow1.15版本编写。本文给出了spleeter的pytorch版本,并将官方预训练模型转化为pytorch模型。该版本经验证效果与官方版本一致。
从功能上,目前预训练模型为2stems(分离出人声/伴奏),4stems(分离出人声/伴奏/鼓/贝斯/其他),5stems(人声/鼓/贝斯/钢琴/其他)。性能上,按照spleeter的官网解释,4stems在使用GPU加速的情况下可以达到100s长度的音乐1s分离完成。从效果上来看,spleeter的各项指标均优于目前的其他开源模型。笔者测试2stems的分离效果,人声和伴奏的分离结果都还不错,两者都比较干净。
本文将介绍spleeter的设计原理,模型结构以及预测和训练的方法和在阅读代码以及实际使用时笔者的一些理解,如有错误,希望读者批评指正。同时,读者需要注意,本文所介绍的代码级别的内容均基于2stems的模型,以及默认参数设定情况的调用到的代码,其余情况未解释,另外由于spleeter一直在更新,本文行号不一定正确,仅供参考。
设计原理
spleeter基于频域进行音轨分离。其网络结构中,每条音轨对应着一个unet网络结构。2stems对应着两个unet,4stems对应4个unet网络。unet的网络输入为音频幅度谱,输出为某条音轨的幅度谱。训练时损失函数为计算出音轨的幅度谱与标准幅度谱的L1距离。预测时稍有不同,通过多条音轨的幅度谱计算出每条音轨占据输入音频的能量比例,即每条音轨的mask,通过输入音频频谱乘以mask得到各个音轨的输出频谱,计算得到wav。
由于spleeter的训练和预测的方法有些差异,因此,笔者将分别叙述两者。
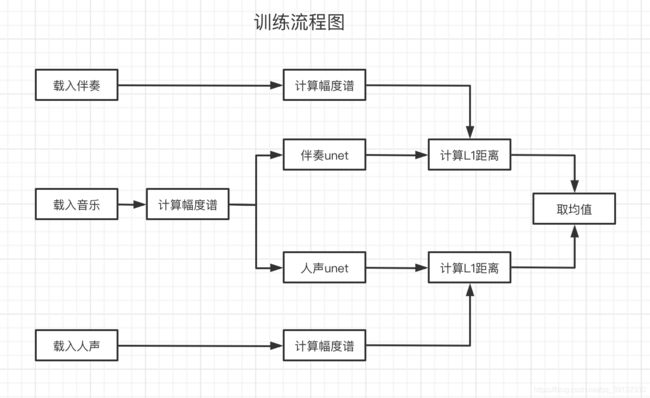
首先描述训练时的基本原理。如下图1,训练时的一组数据为(音乐,伴奏,人声),要求三者在时间轴上尽量完全一致.提取三者频谱并计算出幅度谱。将音乐幅度谱分别输入到人声unet和伴奏unet中,得到预测出的人声unet和伴奏unet,分别计算预测结果和标准结果的L1距离并取均值,作为损失函数,其中伴奏unet和人声unet内部参数会随着数据输入不断更新,此处不再赘述。
预测过程没有标准的人声和伴奏,只有音乐。在于预测出伴奏和人声的幅度谱之后,spleeter将两者分别进行平方,得到人声能量v_eng,和伴奏能量,a_eng,然后使用v_mask = v_eng/(v_eng+a_eng)计算出每个时刻人声在音乐的每个频带上的占比,以及使用a_mask=a_eng/(v_eng+a_eng)计算出伴奏每个时刻在音乐的每个频带上的占比。最后利用输入的音乐频谱分别乘以v_mask和a_mask得到人声和伴奏频谱,使用逆STFT得到人声和伴奏的语音。具体流程如下图:

此处需要介绍的一个地方为,本文的unet中,并不是存粹的一个unet结构,其中使用unet网络结构,并在最后一层使用sigmoid激活函数,计算出人声或者伴奏的mask系数,此时通过输入幅度谱乘以该系数得到了伴奏或人声的幅度谱。
笔者认为预测的时候直接获取每条音轨的mask系数乘以输入音频的频谱得到对应音轨的频谱。实验过够,从听觉来说效果还是不错的。这样的好处在于训练目标和预测目标一致,其次多条音轨之间互不影响,方便根据业务需求进行裁剪优化.
流程以及代码讲解
训练部分
训练部分在代码上的核心逻辑与上述流程图并不一致。上述流程图描述的是单个音乐的处理过程,由于在训练的时候需要大量的数据。因此,重点在于数据集的处理,其中模型的搭建以及训练过程和所用语言和框架强相关,本文不作为重点,只是简述一下。
本部分将分为两块叙述。第一为使用部分,讲解如何使用spleeter来进行训练。分为训练时需要的命令以及对应参数解析。第二部分为训练时的核心代码讲解。
第一部分,使用篇
python3 -m spleeter train -p configs/2stems/base_config.json -d example
-m: 这是python的写法,表示指定模块,在此处表示使用spleeter模块
-p: 指定配置文件位置,详细内容见附3
-d: 指定数据集位置
此处需要解释的是,该命令表示执行spleeter的训练模型,采用2stems的配置文件,数据集的位置为本项目目录的example。在运行之前,需要在example中准备好数据集,结构无要求。因为在配置文件中会指定训练数据集和测试数据集的索引文件。具体配置文件信息以及索引文件信息参考附3的解释即可。
第二部分,代码篇
本篇将首先解析训练时的代码整体结构,而后重点分析数据集的构建部分。
代码整体结构:
训练代码使用的是tensorflow的estimator的高级api接口。一共分为三部分,分别为构建模型,构建数据集,训练以及预测.
预备知识:
模型构建: tensorflow使用tf.estimator.Estimator来构建estimator,其中model_fn参数需要给定一个函数,包含了对于训练/验证/预测时的构建的模型。三者在model_fn中,通过mode参数来进行区分[mode参数是Estimator自动填充的]。其中训练模型需要包含,损失函数(loss)和优化器.验证模型[用来在测试集合上做验证]需要给出损失函数定义[一般会看测试集上的loss],预测模型则不需要包含损失函数和优化器。
数据处理: 使用tf.estimator.TrainSpec进行训练数据处理,其中input_fn参数需要给出一个函数,并且返回值是(features, labels)的格式,同理,对于验证集合,使用的是tf.estimator.EvalSpec.
模型训练:通过tf.estimator.train_and_evaluate将参数传入即可训练,并且可以在分布式机器上直接训练,无需改动代码
注意1: partial函数[https://wiki.jikexueyuan.com/project/explore-python/Functional/partial.html],在构建数据集的时候用到了。
注意2: 在构建数据集的时候spleeter大量使用了dataset.map函数,其效果与python中的map相近,都是对每一个元素做统一的操作,其中dataset.map函数还支持使用多线程处理。
注意3: 构建数据集的时候用到了dataset.cache()函数,其将数据集缓存到硬盘中,下次使用的时候可以直接调用.
注意4: tensorflow estimator的api训练时,遍历数据集,如果数据集被遍历完,则训练停止,所以数据集处理时要使用repeat进行重复。
训练模型构建综述
代码路线: spleeter/commands/main.py[line 43]->跳转到spleeter/commands/train.py[line 80]
audio_adapter = get_audio_adapter(arguments.audio_adapter) # 读取音频的工具,这里使用ffmpeg
audio_path = arguments.audio_path # 数据集文件夹
estimator = _create_estimator(params) # 创建estimator,上述模型构建部分
train_spec = _create_train_spec(params, audio_adapter, audio_path) # 上述数据处理的训练集部分
evaluation_spec = _create_evaluation_spec( # 上述数据处理的测试集部分
params,
audio_adapter,
audio_path)
get_logger().info('Start model training')
tf.estimator.train_and_evaluate( # 训练以及验证
estimator,
train_spec,
evaluation_spec)
训练时数据集构建
代码路线: spleeter/commands/train.py[line 55] -> train.py[line 71] -> train.py[line 380]
基本操作
读取数据集索引文件,原始数据分块,数据集乱序,拼接音频绝对路径,载入音频数据并提取幅度谱,转换为unit8存储,过滤掉异常值,重复数据集,规整每一组音频数据,过滤掉比较短的数据,随机截取数据,打乱数据,将数据重新映射为float32,检查shape,构造用于dataset输入的格式,分批次.
数据操作比较多,但是基本分为载入数据,乱序,提取频谱, 规整数据,缓存数据,构造符合框架需要的数据,这几个类别。
本文重点分析数据分块,提取幅度谱,缓存数据三部分。
数据分块[line: 381]
按照给定的n_chunks_per_song进行分块处理。分块规则如下:如果一块,则取中间部分20s,其余方式时,取末尾20s作为一块,然后从起始位置到最后20s部分进行平均切分,每块20s.其中n_chunks_per_song可以在配置文件中给出,默认是2.
提取幅度谱[line: 394]
载入音频,使用librosa提取频谱,提取出幅度谱。取前1024个频带,剩下的不要了,也就是高频部分不进行训练。
缓存数据[line: 403]
将幅度谱转为dB,选择出最大值,将转为出的dB限制在(maxdB-100,maxdB),将上述区间映射到0-256中,使用uint8进行存储。
预测部分
预测部分与上述预测流程图基本一致。接下来部分将按照上述预测流程图进行分析.本篇分为两部分,使用篇以及代码篇。
第一部分,使用篇
python3 -m spleeter separate -p spleeter/resources/2stems.json -i example/tt/1.m4a -o tmp
-m : 含义与训练时一致
-p: 含义与训练时一致
-i: 要进行分离的音频数据
-o: 分离出的音轨数据wav文件所在文件夹,2stems的输出为tmp/1/accompaniment.wav tmp/1/vocals.wav
上述命令是将1.m4a分离为伴奏和人声,并存放到tmp文件夹中,其伴奏为tmp/1/accompaniment.wav 人声文件为tmp/1/vocals.wav
在使用的时候,第一次会在项目目录/pretrained_models/ 下载需要的模型。可能比较大,耐心等待.
注意: 在使用的时候,最好提前安装好librosa,因为spleeter在系统安装librosa的情况下优先使用librosa进行特征提取,否则使用tensorflow进行特征提取,速度会慢很多。
第二部分,代码篇
本篇将分析预测时的具体流程以及代码。其中,spleeter在预测时采用了大量的@property 装饰器,此时在用到变量的时候才会进行初始化。读者需要注意,可以通过点击变量,查看变量的初始化方式。
spleeter预测部分,使用在代码级别构建好模型结构,然后使用tensorflow的Saver类将模型参数载入到session中的方式。其中模型构建可以通过 self._get_builder().outputs[spleeter/separator.py line: 160],点击outputs,一步一步进行观察,即可了解到。
处理流程如流程图,主要分为,载入音乐,计算频谱,计算幅度谱,分别预测出伴奏和人声的幅度谱,分别计算出伴奏和人声的mask系数,音乐频谱乘以mask,计算得到wav。
载入音乐
代码位置:spleeter/separator.py line: 223
通过调用系统的ffmpeg模块实现对音频的解码,载入。根据指定配置文件中的采样率(sample_rate)和通道数对音频进行重采样等处理,保证模型输入统一,要求采样率44100,双通道。
提取频谱特征
代码位置:spleeter/separator.py line: 193
通过stft_backend选择使用tensorflow提取还是使用librosa提取stft.其中stft的帧长和帧移由指定配置文件中frame_length和frame_step指定.
计算频谱以及幅度谱
代码位置:model/init.py line:269
此时会看到提取频谱的过程,但是如果选择使用librosa时,在计算的时候,是使用stft特征对会话中的mix_stft的tensor进行赋值,不会进行特征提取的流程。注意到幅度谱提取的时候,进行了特征转换,进行了padding和分块以及剔除了一部分特征。
特征shape由(-1, 2049, 2) -> (-1, 512, 1024, 2).此时操作按照512帧为单位进行分块,不是512倍数需要填充0进行补充,得到(-1,512, 2029,2),然后取频谱的前1024(采样率为44100时约为11kHz部分以下保留),得到(-1, 512, 1024, 2),然后利用tf.abs()计算得到幅度谱。
模型预测
代码位置:model/init.py line:203
具体实现:spleeter/model/functions/unet.py 函数: apply_unet
网络结构见附1
计算各个音轨mask
代码位置:model/init.py line:404
基本原理是: 对所有音轨的幅度谱做平方求和得到分母,然后每条音轨的幅度谱做平方做分子,得到每条音轨的系数。此时系数shape为(?,512,1024,2),此时对于1024->2049的操作,内部给出了两种方案,默认方案为通过补0,另一种则是通过取0-1024频段的均值作为1024-2049的参数。经过补充,以及去除分段,得到mask的shape为(?, 2049, 2),此时需要注意的是,在分块的时候进行了padding操作,所以mask的长度比频谱的长,因此需要按照频谱长度,进行截取。
通过实验发现,使用均值来进行高频补充的方案,效果不是很好,在频谱上会发现有明显的一行分隔,经过实现发现,如果取8k-11k的系数做平均,用来对11k以上做填充,其频谱比较平滑。
计算各个音轨的输出频谱
代码位置:model/init.py line:437
输入频谱乘以各个音轨的mask即可
计算wav
代码位置:spleeter/separator.py line: 182
使用逆STFT计算出wav
附1: Unet网络结构
CNN 卷积过程[padding=same,strides=(2,2)]
-> [(5*5卷积核,16个) -> BN -> LeakyRelu(0.2)] -conv1
-> [(5*5卷积核,32个) -> BN -> LeakyRelu(0.2)] -conv2
-> [(5*5卷积核,64个) -> BN -> LeakyRelu(0.2)] -conv3
-> [(5*5卷积核,128个) -> BN -> LeakyRelu(0.2)] -conv4
-> [(5*5卷积核,256个) -> BN -> LeakyRelu(0.2)] -conv5
-> [(5*5卷积核,512个) -> BN -> LeakyRelu(0.2)] -conv6
CNN 逆卷积过程[padding=same,strides=(2,2)]
-> [(5*5卷积核,256个)-> Relu() -> BN ->drop(0.5)->concat(conv5)]
-> [(5*5卷积核,128个)-> Relu() -> BN ->drop(0.5)->concat(conv4)]
-> [(5*5卷积核,64个)-> Relu() -> BN ->drop(0.5)->concat(conv3)]
-> [(5*5卷积核,32个)-> Relu() -> BN ->drop(0.5)->concat(conv2)]
-> [(5*5卷积核,16个)-> Relu() -> BN ->drop(0.5)->concat(conv1)]
-> [(5*5卷积核,1个)-> Relu() -> BN ->drop(0.5)]
-> (4*4卷积核 2个 步长->1*1,dilation_rate=(2, 2),activation='sigmoid',padding=same) // 计算出mask
-> tf.keras.layers.Multiply(input_tensor) // 计算出输出的幅度谱
附2: spleeter文件结构

最重要的两个文件是,标红的两个。在分析训练代码时通过spleeter/main.py作为入口文件及进行分析。在预测时,采用tests/test_separator.py进行分析。
附3: 配置文件参数解释
地址: configs/2stems/base_config.json
{
"train_csv": "path/to/train.csv", // 训练数据集的绝对路径
"validation_csv": "path/to/test.csv", // 测试数据集的绝对路径
"model_dir": "2stems", // 模型文件地址,在工程目录/pretrained_models/2stems
//注意:可以把预训练模型放到这里,就可以在预训练模型基础上进行训练
// 或者训练过程中意外情况停掉了,此时重新执行命令,会在原有基础上继续训练
"mix_name": "mix", // 输入特征的名称以及读取数据集时混合好的音乐文件的前缀
"instrument_list": ["vocals", "accompaniment"], // 读取数据集时人声和伴奏的前缀以及特征提取和预测时输出文件的前缀
"sample_rate":44100, // 特征提取时需要的采样率
"frame_length":4096, // 提取频谱时的帧长
"frame_step":1024, // 提取频谱时的帧移
"T":512, // 特征输入时分块长度
"F":1024, // 特征频谱取上限取(0-1024部分),高频部分不要了
"n_channels":2, // 通道数量
"separation_exponent":2, // 计算mask时,每个音轨幅度谱的次方系数
"mask_extension":"zeros", // mask高频部分的策略,此时为直接给0
"learning_rate": 1e-4, // 学习率,别改太大,容易拟合不了
"batch_size":4, // 批次大小
"training_cache":"training_cache", // 提取特征后的训练集缓存文件[用以多次训练不需要重复提取特征]
"validation_cache":"validation_cache", // 提取特征后的测试集缓存文件[用以多次训练不需要重复提取特征]
"train_max_steps": 1000000, // 最大训练步数
"throttle_secs":300, // 对测试集合进行预测的最短间隔,减少多个对测试集合进行预测浪费时间
"random_seed":0, // 随机种子,本人暂时没用到
"save_checkpoints_steps":150, // 每150步保存一次模型文件
"save_summary_steps":5, // 每5步保存一次sumary文件
"model":{
"type":"unet.unet", // 采取的模型结构为unet
"params":{
}
}
}
train.csv/test.csv的文件结构
csv结构:
mix_path,vocals_path,accompaniment_path,duration
列名解释:
mix_path: 音乐文件路径,会跟-d 所对应的路径进行拼接后得到绝对路径。
vocals_path: 人声文件路径,会跟-d 所对应的路径进行拼接后得到绝对路径。路径名称与instrumental_list中的名称一致
accompaniment_path: 伴奏文件路径,会跟-d 所对应的路径进行拼接后得到绝对路径。路径名称与instrumental_list中的名称一致
duration: 时长,单位是秒,并且必须写为浮点,比如20写为20.0