剑指数据仓库-Hadoop四
一、上次课程回顾
二、Hadoop四(一)
- 2.1、hdfs副本放置策略
- 2.2、hdfs的文件写流程
- 2.3、hdfs的文件读流程
- 2.4、hdfs上的datanode
- 2.5、hdfs上关于数据修复
- 2.6、hdfs上的SecondaryNameNode
- 2.7、fsimage+editlog详解
- 2.8、校验文件是否损坏
三、Hadoop四(二)
- 3.1、hdfs集群上各个节点数据如何实现均衡
一、上次课程回顾
- https://blog.csdn.net/SparkOnYarn/article/details/105098427
1、block块和副本数的关系,面试题须知
2、HDFS的设计是为了小文件,数据上传hdfs前就需要合并,上传hdfs后也可以使用服务合并
3、namenode维护了哪些数据信息、datanode发送心跳和块报告、secondarynamenode上checkpoint要知道它的详细流程
4、修改hdfs的存储目录
二、Hadoop四
- hdfs课程上涉及更多的是原理性的东西,真正对于我们生产上用到的其实一些hdfs的命令,涉及到hdfs上小文件的处理,以及后续API的开发。
- 数据能够存储进hdfs及数据能够从hdfs取出就是涉及生产
2.1、hdfs副本放置策略
eg:有两个机架:rack1和rack2,在机架1上client进行提交:
- 第一个副本:假如上传节点为DN节点,优先放置本节点,否则就随机挑选一台磁盘不太慢,CPU不太繁忙的节点,未来我们在提交文件到hdfs节点上的时候;
- 第二个副本:放置在与第一个副本不同的机架的节点(机架与机架是独立的,避免因机架断电出现问题)
- 第三个副本:放置在与第二个副本相同机架的不同节点上
J总公司会选择一台机器做DataNode节点,直接get和put很方便;正常的公司会单独选择一个Client node:单独一台机器,没有datanode、datanode的角色,仅仅只有hdfs-site.xml文件,有xml文件就能进行通信;
正常公司中都使用CDH,CDH中有一个默认机架,这是一个虚拟的概念,它把机架1和机架2会看作一个整体的机架,在CDH中一般不调整默认的机架(较为麻烦)
2.2、hdfs的文件写流程
对应的hadoop命令:hdfs dfs -put xxx.log /wordcount,这是一个无感知的命令;
1、当我们执行hdfs dfs -put命令的时候,首先调用hdfs client客户端,它调用了分布式文件系统的一个方法,通过rpc协议去跟namenode进行通信,namenode接到请求后客户端去查看是否已经有这个文件,文件已经存在就返回已存在,还要查看是否有权限;一切检查okay就会在namenode创建一个新文件,这个新文件不会关联任何block块,仅仅是返回一个DFSData OutputSTream对象;
面试题目:FSDataOutputStream和FSDataInputStream到底谁是谁?
- FSDataOutputStream是往外出,文件读流程FSDatainputStream
简述流程:
1、Client调用FileSystem.create(filepath)方法,与NameNode进行rpc通信,check是否存在及是否有权限创建,假如不ok,就返回错误信息;假如ok,就创建一个新文件,不关联任何的block块,返回一个FSDataOutputStream对象;
2、Client调用FSDataOutputStream对象的write()方法,
先将第一块的第一个副本写到第一个DN,
第一个副本写完;就传输给第二个DN,
第二个副本写完;就传输给第三个DN,第三个副本写完。
就返回一个ack packet(确认包)给第二个DN,第二个DN接收到第三个的ack packet(确认包)+自身ok,就返回一个ack packet
给第一个DN,第一个DN接收到
第二个DN的ack packet确认包 + 自身ok,就返回ack packet(确认包)给FSDataOutputStream对象,这标志第一个块的3个副本写完。
然后余下的块这样写:
2.3、当向文件写入数据完成后,Client调用FSDataOutputStream.close() 方法,关闭输出流。
2.4、再调用分布式的文件系统FileSystem.complete()方法,告诉NN该文件写入成功。
2.3、hdfs的文件读流程
- hdfs文件读流程调用的是FSDataInputStream对象
简述hdfs文件的读流程:
1、Client调用FileSystem.open(filePath)方法,与NN进行【RPC】协议通信,返回该文件的部分或者全部的block块的列表,也就是返回FSDataInputStream对象。
2、Client调用FSDataInputStream对象的read()方法
a. 与第一个块最近的DN进行read,判断这个块与哪个dn最近,读取完成后,会进行check;
假如ok,就关闭与当前DN的通信;假如失败,会记录失败块+DN信息(会记录节点上块是否损坏,下次再进行请求读取,就会跳过这个块了);下次不会再进行读取;会去该块的第二个DN地址读取
block1 dn5
block1 dn15
block1 dn25
b.然后去第二个块的最近的DN上通信读取,check后,关闭通信;
c.假如block列表读取完成后,文件还未结束,就再次调用FileSystem方法从NN获取该文件的下一批次的block列表。(感觉就是连续的数据流,对于客户端操作是透明的无感知的)
3、Client调用FSDataInputStream.close()方法,关闭输入流。
2.4、迁移pid文件存储路径&&迁移hdfs的存储目录
1、迁移pid的存储路径:
- 修改/tmp下hdfs的pid存储路径,因为之前它是存放在/tmp目录下的,而它有定期清理机制,所以需要移到新的文件目录下:
1、我们首先需要知道启动hdfs进程的pid文件存储目录,如下:
[hadoop@hadoop001 hsperfdata_hadoop]$ pwd
/tmp/hsperfdata_hadoop
[hadoop@hadoop001 hsperfdata_hadoop]$ ll
total 160
-rw------- 1 hadoop hadoop 32768 Mar 26 13:45 11501
-rw------- 1 hadoop hadoop 32768 Mar 26 13:45 14940
-rw------- 1 hadoop hadoop 32768 Mar 26 13:44 15046
-rw------- 1 hadoop hadoop 32768 Mar 26 13:45 15247
-rw------- 1 hadoop hadoop 32768 Mar 26 13:45 1881
2、因为pid文件是存储在/tmp目录的,进入到hadoop的config目录,编辑hadoop-env.sh文件,修改HADOOP_PID_DIR的目录:
[hadoop@hadoop001 hadoop]$ pwd
/home/hadoop/app/hadoop/etc/hadoop
[hadoop@hadoop001 hadoop]$ vi hadoop-env.sh
# The directory where pid files are stored. /tmp by default.
# NOTE: this should be set to a directory that can only be written to by
# the user that will run the hadoop daemons. Otherwise there is the
# potential for a symlink attack.
export HADOOP_PID_DIR=${HADOOP_PID_DIR}
-->修改如下:export HADOOP_PID_DIR=/home/hadoop/tmp
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
3、同样编辑yarn的pid文件:
export YARN_PID_DIR=/home/hadoop/tmp
4、修改好后stop-all.sh,关闭所有进程,然后再重新启动,进入到目录中,发现如下就是okay的:
[hadoop@hadoop001 hadoop]$ cd /home/hadoop/tmp
[hadoop@hadoop001 tmp]$ ll
total 20
-rw-rw-r-- 1 hadoop hadoop 6 Mar 26 14:01 hadoop-hadoop-datanode.pid
-rw-rw-r-- 1 hadoop hadoop 6 Mar 26 14:01 hadoop-hadoop-namenode.pid
-rw-rw-r-- 1 hadoop hadoop 6 Mar 26 14:01 hadoop-hadoop-secondarynamenode.pid
-rw-rw-r-- 1 hadoop hadoop 6 Mar 26 14:01 yarn-hadoop-nodemanager.pid
-rw-rw-r-- 1 hadoop hadoop 6 Mar 26 14:01 yarn-hadoop-resourcemanager.pid
迁移hdfs的存储目录:
1、在我们未进行调整前,hdfs的存储目录如下:
[hadoop@hadoop001 dfs]$ pwd
/tmp/hadoop-hadoop/dfs
[hadoop@hadoop001 dfs]$ ll
total 12
drwx------ 3 hadoop hadoop 4096 Mar 26 14:01 data
drwxrwxr-x 3 hadoop hadoop 4096 Mar 26 14:01 name
drwxrwxr-x 3 hadoop hadoop 4096 Mar 26 14:01 namesecondary
2、因为该目录下存在定期清理规则,所以需要将此目录迁移至/home/hadoop/tmp下:
1、stop-dfs.sh
2、chmod -R 777 /home/hadoop/tmp
3、mv /tmp/hadoop-hadoop/dfs /home/hadoop/tmp/
4、vi core-site.xml,修改hadoop.tmp.dir
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
hadoop.tmp.dir这个配置参数在core-default.xml中可以进行找到:
| name | value | description |
|---|---|---|
| hadoop.tmp.dir | /tmp/hadoop-${user.name} | A base for other temporary directories. |
插曲:
1、普通用户无密码使用sudo权限,使用root用户编辑/etc/sudoers文件,增加一行:
1、vi /etc/sudoers
90 ## Allow root to run any commands anywhere
91 root ALL=(ALL) ALL
92 hadoop ALL=(ALL) NOPASSWD:ALL
2、这样普通用户也就能使用sudo命令了:
[hadoop@hadoop001 tmp]$ sudo mv /tmp/hadoop-hadoop/dfs /home/hadoop/tmp/
sudo: >>> /etc/sudoers: syntax error near line 92 <<<
sudo: parse error in /etc/sudoers near line 92
sudo: no valid sudoers sources found, quitting
sudo: unable to initialize policy plugin
[hadoop@hadoop001 tmp]$ sudo mv /tmp/hadoop-hadoop/dfs /home/hadoop/tmp/
2.5、hadoop常规命令使用
1、hdfs dfs底层调用的是hadoop fs,而hadoop fs底层调用的还是hadoop fs
[hadoop@hadoop001 hadoop]$ hdfs dfs
Usage: hadoop fs [generic options]
[hadoop@hadoop001 hadoop]$ hadoop fs
Usage: hadoop fs [generic options]
2、上传、下载:
-
通常使用的是put和get命令,语法如下:
[-get [-p] [-ignoreCrc] [-crc]... ] [-put [-f] [-p] [-l] ... ] 1、把文件进行上传至/wordcount/input/这个目录: [hadoop@hadoop001 ~]$ hdfs dfs -put /home/hadoop/data/wordcount.log /wordcount/input/ 20/03/26 15:30:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2、查看是否已经上传上去了: [hadoop@hadoop001 ~]$ hdfs dfs -ls /wordcount/input 20/03/26 15:30:46 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 1 items -rw-r--r-- 1 hadoop supergroup 35 2020-03-26 15:30 /wordcount/input/wordcount.log 3、使用get把hdfs上的文件下载至linux目录,建议使用绝对路径: [hadoop@hadoop001 ~]$ hdfs dfs -get /wordcount/input/wordcount.log /home/hadoop/ 20/03/26 15:31:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [hadoop@hadoop001 ~]$ ll total 32 drwxrwxr-x 3 hadoop hadoop 4096 Mar 24 15:36 app drwxrwxr-x 2 hadoop hadoop 4096 Mar 25 00:08 data drwxrwxr-x 2 hadoop hadoop 4096 Mar 20 16:23 lib drwxrwxr-x 2 hadoop hadoop 4096 Mar 20 16:23 log drwxrwxr-x 2 hadoop hadoop 4096 Mar 20 17:12 software drwxrwxr-x 2 hadoop hadoop 4096 Mar 20 16:23 sourcecode drwxrwxrwx 4 hadoop hadoop 4096 Mar 26 15:03 tmp -rw-r--r-- 1 hadoop hadoop 35 Mar 26 15:31 wordcount.log -
上传下载除了有put和get以外,还有一对命令就是:
[-copyFromLocal [-f] [-p] [-l]... ] [-copyToLocal [-p] [-ignoreCrc] [-crc] ... ] 1、见名知意,从linux系统上传至hdfs目录: [hadoop@hadoop001 ~]$ hdfs dfs -copyFromLocal /home/hadoop/data/wordcount.log /ruozedata [hadoop@hadoop001 ~]$ hdfs dfs -ls /ruozedata -rw-r--r-- 1 hadoop supergroup 434354462 2020-03-25 21:27 /ruozedata/hadoop-2.6.0-cdh5.16.2.tar.gz -rw-r--r-- 1 hadoop supergroup 35 2020-03-26 15:41 /ruozedata/wordcount.log 2、再从hdfs目录download到linux目录: [hadoop@hadoop001 ~]$ hdfs dfs -copyToLocal /ruozedata/wordcount.log /home/hadoop/app/ 20/03/26 15:47:37 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [hadoop@hadoop001 ~]$ ll /home/hadoop/app/ total 8 lrwxrwxrwx 1 hadoop hadoop 22 Mar 20 16:43 hadoop -> hadoop-2.6.0-cdh5.16.2 drwxr-xr-x 15 hadoop hadoop 4096 Mar 24 15:50 hadoop-2.6.0-cdh5.16.2 -rw-r--r-- 1 hadoop hadoop 35 Mar 26 15:47 wordcount.log 3、拷贝到本地目录如果已经名称相同会提示:file exists 4、拷贝到linux目录的时候可以进行重命名: [hadoop@hadoop001 app]$ hdfs dfs -copyToLocal /ruozedata/wordcount.log /home/hadoop/app/wordcount1.log 20/03/26 15:56:27 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [hadoop@hadoop001 app]$ ll total 12 lrwxrwxrwx 1 hadoop hadoop 22 Mar 20 16:43 hadoop -> hadoop-2.6.0-cdh5.16.2 drwxr-xr-x 15 hadoop hadoop 4096 Mar 24 15:50 hadoop-2.6.0-cdh5.16.2 -rw-r--r-- 1 hadoop hadoop 35 Mar 26 15:56 wordcount1.log -rw-r--r-- 1 hadoop hadoop 35 Mar 26 15:47 wordcount.log
3、修改权限用户、用户组权限:
1、原始的hdfs上的/wordcount/input目录下的文件内容:
[hadoop@hadoop001 app]$ hdfs dfs -ls /wordcount/input
20/03/26 15:59:54 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 1 hadoop supergroup 35 2020-03-26 15:30 /wordcount/input/wordcount.log
2、修改hdfs上的文件权限:
[hadoop@hadoop001 app]$ hdfs dfs -chmod -R 755 /wordcount/input/wordcount.log
20/03/26 16:00:47 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
3、查看权限是否已经修改过了:
[hadoop@hadoop001 app]$ hdfs dfs -ls /wordcount/input
20/03/26 16:00:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rwxr-xr-x 1 hadoop supergroup 35 2020-03-26 15:30 /wordcount/input/wordcount.log
4、修改hdfs上文件的用户、用户组
[hadoop@hadoop001 app]$ hdfs dfs -chown -R root:supergroup /wordcount/input/wordcount.log
20/03/26 16:01:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
5、验证查看:
[hadoop@hadoop001 app]$ hdfs dfs -ls /wordcount/input
20/03/26 16:01:32 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rwxr-xr-x 1 root supergroup 35 2020-03-26 15:30 /wordcount/input/wordcount.log
2.6、启动hdfs上的回收站机制&&跳过回收站机制直接删除
1、修改core-default.xml
| name | value | description |
|---|---|---|
| fs.trash.interval | 10 | Number of minutes after which the checkpoint gets deleted. If zero, the trash feature is disabled. This option may be configured both on the server and the client. If trash is disabled server side then the client side configuration is checked. If trash is enabled on the server side then the value configured on the server is used and the client configuration value is ignored. |
<property>
<name>fs.trash.interval</name>
<value>100</value> //意思是经过删除操作后,回收站的内容保留100分钟
</property>
需要重新启动hdfs,测试删除结果如下:
1、查看hdfs上的目录如下:
[hadoop@hadoop001 hadoop]$ hdfs dfs -ls /wordcount/input
20/03/26 15:04:32 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 1 hadoop supergroup 35 2020-03-24 23:24 /wordcount/input/wordcount.log
2、尝试删除:
[hadoop@hadoop001 hadoop]$ hdfs dfs -rm /wordcount/input/wordcount.log
20/03/26 15:04:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
20/03/26 15:04:49 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop001:9000/wordcount/input/wordcount.log' to trash at: hdfs://hadoop001:9000/user/hadoop/.Trash/Current/wordcount/input/wordcount.log
//会把文件迁移到回收站目录,验证:
[hadoop@hadoop001 hadoop]$ hdfs dfs -ls hdfs://hadoop001:9000/user/hadoop/.Trash/Current/wordcount/input/
20/03/26 15:08:17 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 1 hadoop supergroup 35 2020-03-24 23:24 hdfs://hadoop001:9000/user/hadoop/.Trash/Current/wordcount/input/wordcount.log
好处:未来在工作当中:切记检查生产环境是否开启回收站,在CDH中是默认开启的,
2、跳过系统的回收站机制直接删除:
[hadoop@hadoop001 data]$ hdfs dfs -put wordcount.log /wordcount/input/
20/03/26 15:10:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop001 data]$ hdfs dfs -rm -skipTrash /wordcount/input/wordcount.log
20/03/26 15:11:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Deleted /wordcount/input/wordcount.log
[hadoop@hadoop001 data]$ hdfs dfs -ls /wordcount/input/
20/03/26 15:11:46 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop001 data]$
注意:我们生产上如果开了回收站机制的话,删除文件的时候尽量少使用-skipTrash参数;然后回收站保留时间通过自行修改core-site.xml中的参数即可。正常fs.trash.interval设置都是7天。
2.7、hdfs上的安全模式
-
如何进入安全模式:hdfs dfsadmin -safemode enter
[hadoop@hadoop001 app]$ hdfs dfsadmin -safemode enter 20/03/26 16:07:30 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Safe mode is ON
思考:我们的hdfs进入安全模式后,测试能否上传文件、测试能否查看hdfs的目录、测试查看hdfs文件内容:
测试结果如下:
1、测试上传文件至hdfs目录:提示进入安全模式,无法上传
[hadoop@hadoop001 app]$ hdfs dfs -put wordcount1.log /wordcount/input/
20/03/26 16:09:45 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
put: Cannot create file/wordcount/input/wordcount1.log._COPYING_. Name node is in safe mode.
2、测试查看hdfs的文件目录,没问题:
[hadoop@hadoop001 app]$ hdfs dfs -ls /
20/03/26 16:36:49 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 4 items
drwxr-xr-x - hadoop supergroup 0 2020-03-26 15:41 /ruozedata
drwx------ - hadoop supergroup 0 2020-03-24 23:26 /tmp
drwx------ - hadoop supergroup 0 2020-03-26 15:04 /user
drwxr-xr-x - hadoop supergroup 0 2020-03-24 23:26 /wordcount
3、测试查看文件的内容,没问题:
[hadoop@hadoop001 app]$ hdfs dfs -cat /ruozedata/wordcount.log
20/03/26 16:37:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
hello world john
hello world
hello
拓展:
- 一般手动去离开安全模式的可能性是非常小的,如果我们是在下游关闭写操作,那各种各养的组件会抛出各种错误,应该在上游做一个开关(保障数据零丢失)

生产上集群故障是很正常的,HDFS集群故障启动NN Log,会抛出安全模式的一个问题,safemode安全模式不会自动离开,如果故障已经排除的话,使用hdfs dfsadmin -safemode leave进行离开安全模式。
2.8、hdfs的fsck
- hdfs fsck /,从hdfs的根目录/开始检查健康状态:
[hadoop@hadoop001 app]$ hdfs fsck /
20/03/26 16:51:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Connecting to namenode via http://hadoop001:50070/fsck?ugi=hadoop&path=%2F
FSCK started by hadoop (auth:SIMPLE) from /172.17.0.5 for path / at Thu Mar 26 16:51:11 CST 2020
.........Status: HEALTHY
Total size: 434529610 B
Total dirs: 19
Total files: 9
Total symlinks: 0
Total blocks (validated): 11 (avg. block size 39502691 B)
Minimally replicated blocks: 11 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 1
Average block replication: 1.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 1
Number of racks: 1
FSCK ended at Thu Mar 26 16:51:11 CST 2020 in 21 milliseconds
The filesystem under path '/' is HEALTHY
主要查看哪几个指标:
Corrupt blocks: 0 //表示损坏的块
Missing replicas: 0 (0.0 %) //丢失的副本
后期如果hdfs上的块有损坏,如何进行修复?
三、Hadoop四(二)
3.1、hdfs的各节点的数据均衡如何实现?
在hdfs-default.xml中的balancer参数设置:
- dfs.datanode.balance.bandwidthPerSec:这个参数控制的是数据在传输中的时候占用的带宽,比如数据正在写入,不做限制的话,占据带宽很大影响DN。
| name | value | description |
|---|---|---|
| dfs.datanode.balance.bandwidthPerSec | 10m | Specifies the maximum amount of bandwidth that each datanode can utilize for the balancing purpose in term of the number of bytes per second. You can use the following suffix (case insensitive): k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa)to specify the size (such as 128k, 512m, 1g, etc.). Or provide complete size in bytes (such as 134217728 for 128 MB). |
参数二:阈值(集群中各个节点的数据均衡):
- threshold = 10% --> 集群中所有节点的磁盘used与集群的平均used之差要小于这个阈值。
- 解析:我们所有节点的磁盘平均使用率是76%;DN1大于平均使用率14%,第二胎机器小于平均使用率16%,如下图:DN1节点的数据会迁移部分到DN2;
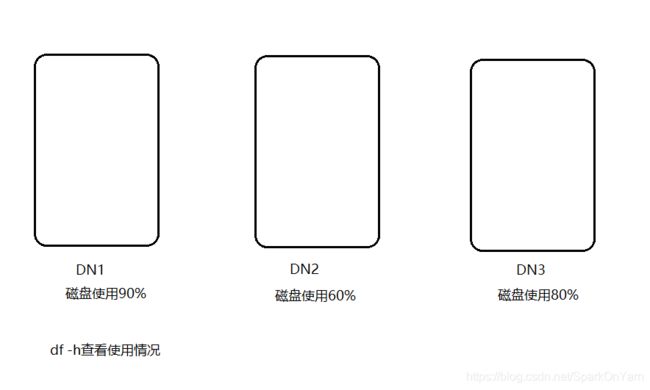
生产上的数据均衡如何实现?
- 每晚写一个shell脚本,执行:./start-balancer.sh,最不济使用crontab调度。
为什么生产上有的机器的数据多呢?
- 取决于副本放置策略,生产上不止3台,比如某台机器负载低,性能好,数据量写入就大;或者某台机器做的是提交操作,数据也会多。
J总公司每晚12点20分做的shell调度。
1、就是查看命令帮助:
[hadoop@hadoop001 sbin]$ ./start-balancer.sh --help
starting balancer, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.16.2/logs/hadoop-hadoop-balancer-hadoop001.out
Usage: hdfs balancer
[-policy ] the balancing policy: datanode or blockpool
[-threshold ] Percentage of disk capacity
[-exclude [-f | ]] Excludes the specified datanodes.
[-include [-f | ]] Includes only the specified datanodes.
[-source [-f | ]] Pick only the specified datanodes as source nodes.
[-idleiterations ] Number of consecutive idle iterations (-1 for Infinite) before exit.
[-runDuringUpgrade] Whether to run the balancer during an ongoing HDFS upgrade.This is usually not desired since it will not affect used space on over-utilized machines.
Generic options supported are
2、语法使用:
[hadoop@hadoop001 sbin]$ ./start-balancer.sh -threshold 5
starting balancer, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.16.2/logs/hadoop-hadoop-balancer-hadoop001.out
每天晚上进行调度,数据平衡,也叫做毛刺修正
一个DN节点的多个磁盘的数据均衡如何做:
df -h
/data01 90%
/data02 80%
/data03 60%
此时又新增一块磁盘:/data04 0%
地址:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSDiskbalancer.html
1、生成hadoop001节点的json文件 --> hadoop001.plan.json
- hdfs diskbalancer -plan hadoop001
2、执行计划(耗时):
- hdfs diskblancer -execute hadoop001.plan.json
3、执行完了之后需要去查看状态:
- hdfs diskblancer -query hadoop001
什么时候手动或调度执行?
a. 新盘加入时(这台机器加了一块磁盘)
b.监控服务器的磁盘剩余空间小于【阈值】10%时,发邮件预警,去手动执行。
新加磁盘在CDH中如何被识别?
- 只需要搜索一个参数:dfs.datanode.data.dir /data01,/data02,/data03,/data04;按逗号生效,重启集群生效。
为什么DataNode在生产上要挂载物理的多个磁盘?
/data01 disk1
/data02 disk2
/data03 disk3
/data04 disk4
-
主要原因是为了高效率的读和写,提前规划好项目周期:未来2-3年的数据存储量;J总公司集群148个节点,每个节点都是10块1万转1T的硬盘,一台服务器就是10T,没有做raid;
-
生动的解析:300M的文件对于1块100M/S的数据盘来说,需要写3秒;但是300M的文件对于3块100M/S的数据盘来说,只要3秒就能完成。
避免了后期加磁盘维护的工作量,可能会存在加磁盘关机重启导致服务器损坏

四、本次课程作业
1、整理副本放置策略
2、整理HDFS的读写流程
3、整理pid文件(从/tmp目录进行迁移)
4、整理hdfs dfs的常用命令
5、整理多节点,单节点的磁盘均衡的操作
6、整理安全模式(上游的数据会源源不断的写到下游,堆积在Kafka,一定要在上游做开关,记录数据流出了多少,保证数据0丢失,不能因为hdfs safemode的进入使得数据全部抛错)