redis主从复制
单机部署
单机部署,如果机器发生故障,redis服务挂掉我们可以通过迅速重启服务解决,但是如果是机器宕机可能机器无法启动或者硬盘损坏会造成数据丢失,那么这对部分数据要求较高的线上业务的影响将是灾难性的;
解决单点问题
主从复制:
通过主从复制,一主一从或一主多从进行数据备份,保证如果机器宕机或服务挂掉,备份数据立即顶上,保证线上业务平稳运行。同时可以借助主从复制进行读写分离,进行分流,减小master节点的负载。
实现方式
1. slaveof命令(异步)
复制:
![]()
该命令会清除当前节点的所有数据,异步复制master节点的数据。
取消复制:
该命令并不会清除当前节点的数据
2. 通过配置文件
在redis.conf中添加
#成为某个节点的从节点
slaveof ip port
#从节点只读
slave-read-only yes
3.简单比较
| 方式 | 命令 | 配置 |
|---|---|---|
| 优点 | 无需重启 | 统一配置 |
| 缺点 | 不便于管理 | 需要重启 |
相对来说,我们第一次搭建可以使用配置,统一管理,在日常如果需要运维可以使用命令,避免redis重启。
4.奇葩问题
在redis5.0的时候做测试的时候,发现slaveof命令使用没问题,但在测试配置的时候你会发现redis的默认配置文件中找不到slaveof命令了。这他么就很尴尬了!
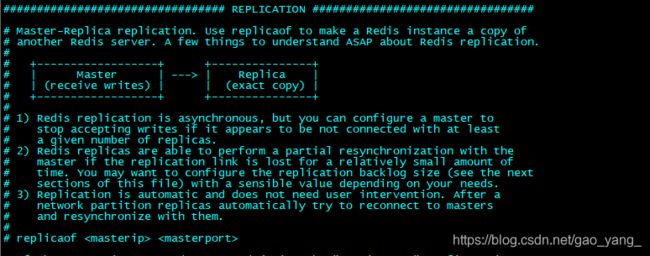
于是你仔细再一看,上面这段代码贼眼熟,没错,这就是你要的主从配置,master-slave 架构的描述改为 master-replica。SLAVEOF 提供别名 REPLICAOF,所以仍然可以使用 SLAVEOF,但多了一个选项。你这时候肯定想骂娘,好端端的改这个搞毛啊?
据说是一帮闲得蛋疼的老外抗议这个slave暗示奴隶制度,政治方向有问题,要求redis作者修改,作者迫于无奈,于是就有了这么一个东西。
一个纯开源技术性的东西,主观上并没有任何讽刺意味,想不通这帮老外脑袋里都是怎么想的?

redis5.0实验
配置:
replicaof 127.0.0.1 6380
#从节点只读
slave-read-only yes
启动redis 6380服务(master)
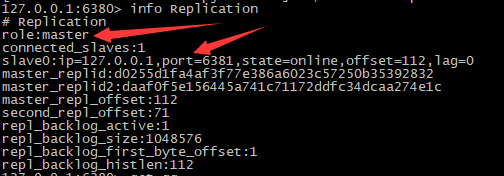
启动redis 6381服务(slave)
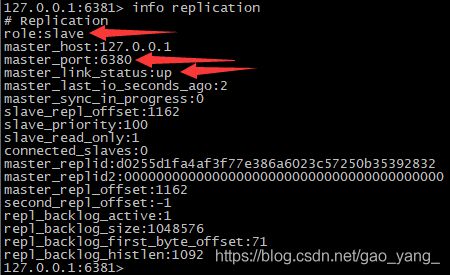
- 测试从节点只读

在从节点执行set命令,从实验中可以看出,从节点不能执行写操作。 - 测试主从复制,延迟很低




- 查看master日志

请求同步->bgsave->success - 查看slave日志

请求全量复制->接收master传递的数据->清空本地旧数据->loading到内存中->success
复制
runid和全量复制
redis每次启动都会生成一个标识,重启后会变换
./redis-cli -p 6380 info Server | grep run

在第一次启动,slave节点并不知道主节点的runid,那么会申请全量复制,或者slave发现主节点的runid发生变化,就会进行全量复制。
偏移量
./redis-cli -p 6381 info replication | grep master_repl_
SLAVE节点
![]()
MASTER节点
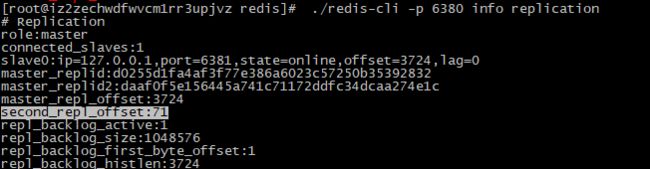
主节点和从节点的偏移量是同步更新状态,从节点会不断上报自己的状况。一般在做监控的时候才会观察这个偏移量,如果差别太大,证明主从复制发生问题。
使用psync命令,包含两个参数,runid和偏移量,slave节点向master节点汇报偏移量,master通过偏移量对比完成数据同步。
全量复制
第一次复制
slave并不知道master的runid
(1)会发送psync ? -1,master接收到后可以感知slave需要做全量复制
(2)master会将runid和偏移量告诉slave节点
(3)slave保存master的基本信息
(4)master会做bgsave,同时将bgsave期间数据写入复制缓冲区repl_back_buffer中。
(5)master send RDB
(6)master send buffer
(7)slave 清空旧数据,加载RDB文件和buffer数据
全量复制开销
(1)master 的bgsave时间(做RDB文件),对CPU,内存,硬盘都会有很大开销
(2)master节点send RDB的网络传输时间
(3) slave 清空数据的时间
(4)slave加载RDB文件的时间
(5)slave可能做AOF重写
问题
在redis2.8之前,master和slave之间发生网络抖动,那么master在这段时间内的数据,slave并不能同步到,这就需要再次进行全量复制,这就会造成很大的开销。
部分复制
(1)connection 丢失
(2)master在工作期间会将数据写入复制缓冲区
(3)connection 成功
(4)slave节点发送psync {offset}{runid}到master
(5)master发现偏移量在buffer之内,master会将offset开始到结束的数据发送给slave
在网络发生抖动时,在很大程度上我们并不需要全量复制,而部分复制就很好的解决了这个问题,避免全量复制,减少消耗服务器资源,但是如果偏移量超出master的复制缓冲区的范围,全量复制不可避免。
主从复制
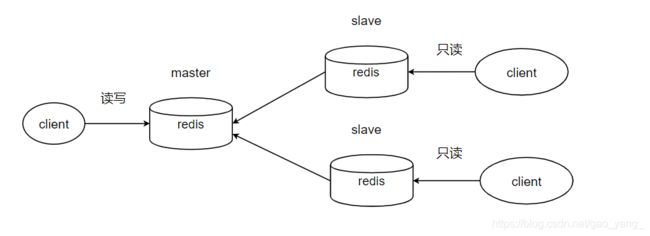
上图是最常见的主从复制,做了一个读写分离。
- 如果其中一个slave节点宕机,我们可以将client转移到另一个slave上,将服务器配置进行修改,重启即可完成故障的转移。
- master发生故障,那么redis的写服务不能正常使用,而从节点的读不受影响。寻找一个slave,执行slaveof no one ,成为master,另外的slave节点执行slave of newmaster,这个过程需要一定的时间和经验来处理。
事实上上述的问题并没有得到一个较好的解决,发生手动转移依旧需要花费很多时间,特别是线上发生故障手动故障转移并不是一个好的解决办法。
读写分离
- 读写分离:度流量分摊到从节点
- 问题:
(1) 复制数据延迟
(2)读到过期数据
redis是如何删除过期数据?
第一种是懒惰性策略在操作key的时候会判断key是否过期,
第二种是一个定时任务每次批量去采样一些key看是否过期,如果过期数据太多,采样速度太低就会有大量过期数据。
如果client不能及时将过期
(3)从节点故障
配置不一致
1. 主从maxmemory不一致:
丢失数据,进行全量复制,从节点加载RDB发现文件过大,还会触发maxmemory策略,将数据进行淘汰,甚至当slave节点晋升为主节点后,你会发现数据丢失,这时已经无法在挽回。
2.数据结构优化参数设置不一致:
例如list-max-ziplist-entries或hash-max-zipmap-entries等等,会导致内存不一致。
规避全量复制
1.第一次全量复制
(1)第一次无法避免
(2)小主节点(maxmemory不要过大)、低峰处理
2.节点runId不匹配
(1)主节点重启,会导致runId变化,slave会保存master的runId,如果runId发生变化,slave就会做全量复制;(Redis4.0的新特性PSYNC2)
PSYNC2: 新的一种主从复制同步机制。
PSYNC1:2.8~4.0之前版本的同步为PSYNC1
psync1因为网络中断或者阻塞导致主从中断,恢复后必须重新到主节点dump一份全量数据同步到从节点。psync2再中断恢复后只需要同步复制延迟的那部分数据。
psync1在重启从节点需要重新全量同步数据。psync2只部分同步增量数据。
在PSYNC1 当复制为链式复制的时候,如 A>B>C 主节点为A。当A出现问题,C节点不能正常复制B节点的数据。当提升B为主节点,C需要全量同步B的数据。在PSYNC2:PSYNC2解决了链式复制之间的关联性。A出现问题不影响C节点,B提升为主C不需要全量同步。
在使用星形复制。如一主两从。A>B , A>C 主节点为A。当A出现问题,B提升为主节点,C 重新指向主节点B。使用同步机制PSYNC2,C节点只做增量同步即可。在使用sentinel故障转移可以减少数据重新同步的延迟时间,避免大redis同步出现的网络带宽占满。
3.复制缓冲区不足
如果发生网络抖动,只要偏移量在一定范围内,可以进行部分复制,一旦超出,就需要进行全量复制。我们可以通过增大复制缓冲区配置rel_backlog_size
复制风暴
1.单主节点复制风暴
主节点重启,多个从节点复制(要复制多个RDB传输给slave,master压力骤升)。

可以将星型结构更换为链式架构,但是链式架构问题较多,做读写分离时或高可用,slave1发生问题,故障转移比星型结构要复杂很多。
2.单机器复制风暴
如果master节点都部署在同一台主机,一旦机器发生重启,所有slave都要和master进行全量复制,那么这台主机的带宽,内存,CPU都会有极大的压力。为了规避这种情况,master要避免部署在同一台主机上。
当然,做故障转移,让slave晋升为master也是一种非常好的解决方案。