运行Hadoop自带的MapReduce程序WordCount
Hadoop自带了个单词计数的MapReduce程序WordCount,下面用三种方法运行该程序
在开始前先在hdfs上面创建输入和输出路径:
1、使用hdfs dfs -mkdir /input命令创建一个input文件夹
2、使用hdfs dfs -put /home/kingssm/input/data.dat /input命令将需要执行的文件上传到hdfs上的输入文件夹
3、使用hdfs dfs -mkdir /output命令创建输出文件夹,因为hadoop要求输出文件夹不能存在,所以这只是空文件夹,在执行时再确定输出文件夹,如、output/output1
一、Linux系统上直接运行jar包
进入文件查看,最后一个就是我们要执行的程序
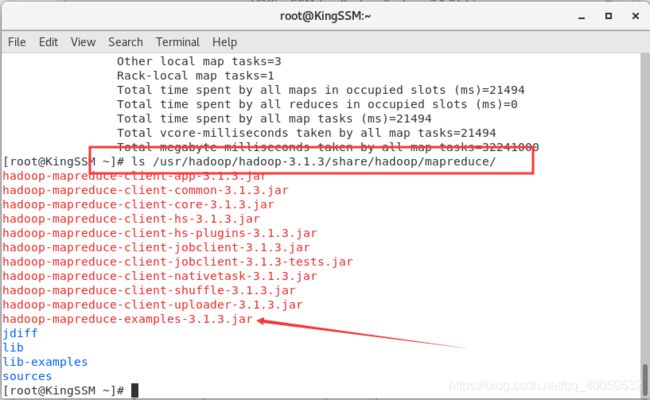
运行程序:输入命令进行执行hadoop jar /usr/hadoop/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output/output222
如果觉得太长了可以先进入到mapreduce目录再执行。
解释:hadoop jar是hadoop执行jar文件必须写的命令,中间很长的是jar包的路径,wordcount是启动类,/input是输入路径,/output/output222是输出路径,输出路径不能已经存在,前面创建文件夹已说。

到页面上查看,创建出了输出文件

使用命令查看输出文件内容:hdfs dfs -cat /output/output222/part-r-00000

常见问题
问题一:
启动类写成WordCount,虽然代码的真实的类名就是WordCount,但是可能是官方打包是限定了启动类是wordcount,也就是说启动类只能小写
问题二:
运行报错:Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
问题原因:配置问题,在进行集群配置时没有添加该配置(可能是有些没有该配置也可以运行)
解决方案:打开mapred-site.xml文件,添加下面代码
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.map.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.reduce.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
问题三:
运行报错:Container killed on request. Exit code is 143 yarn.nodemanager.resource.
问题原因:使用默认内存,内存往往不够用
解决方案:修改下边文件配置(如果是多台虚拟机,那其他虚拟机最好也跟着改一下)
首先在yarn-site.xml中添加下面内容:
yarn.nodemanager.resource.memory-mb
22528
每个节点可用内存,单位MB
yarn.scheduler.minimum-allocation-mb
1500
单个任务可申请最少内存,默认1024MB
yarn.scheduler.maximum-allocation-mb
16384
单个任务可申请最大内存,默认8192MB
然后在mapred-site.xml中添加下面内容:
mapreduce.map.memory.mb
1500
每个Map任务的物理内存限制
mapreduce.reduce.memory.mb
3000
每个Reduce任务的物理内存限制
mapreduce.map.java.opts
-Xmx1200m
mapreduce.reduce.java.opts
-Xmx2600m
mapreduce.framework.name
yarn
二、在window上使用idea运行、远程连接hdfs
下面是WordCount的源程序:
package test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* @Classname WordCount
* @Description TODO
* @Date 2019/12/6 22:12
* @Created by KingSSM
*/
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// FileInputFormat.addInputPath(job, new Path(args[0]));
// FileOutputFormat.setOutputPath(job, new Path(args[1]));
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.33.131:9000/input"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.33.131:9000/output/output5"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
该程序依旧需要有输入路径和输出路径,有两种方式,一是给main方法传参数,二是直接指定路径(我这里是连接虚拟机上面的hdfs系统,路径也可以是本地的)
给main传参:
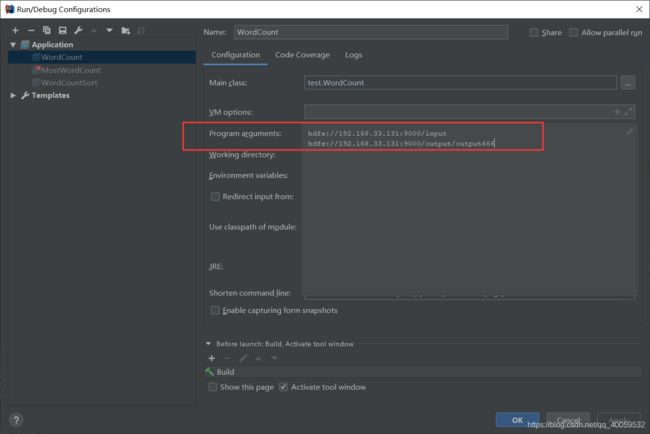
这里采用第二种方式,然后直接运行,到虚拟机里面查看结果,结果如下

常见问题
无法连接到虚拟机、没有输出目录等
解决方法:
1、确保虚拟机的hadoop已经启动
2、确保没有防火墙阻止,可以试着虚拟机和window互ping一下
3、最重要一点:hadoop的配置文件core-site.xml中,fs.defaultFS的值hdfs://ip:port中的ip是不是127.0.0.1或localhost,如果是,则改为虚拟机ip(或者添加/etc/hosts文件),port没有特别要求
三、修改程序实现排序并打包jar放到Linux运行
hadoop对于统计的单词默认按照单词进行排序,修改程序使得单词按照出现次数降序排序
代码如下:
package test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.map.InverseMapper;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* @Classname WordCount
* @Description TODO
* @Date 2019/12/6 22:12
* @Created by KingSSM
*/
public class WordCountSort {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString(), " \t\n\f\".,:;?![]'-");
while (itr.hasMoreTokens()) {
word.set(itr.nextToken().toLowerCase());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static class DecreasingComparator extends IntWritable.Comparator {
@SuppressWarnings("rawtypes")
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.33.131:9000"); //此处先配置一下,否则临时文件无法删除
Path tempDir = new Path("hdfs://192.168.33.131:9000/output/temp");
//获取所有单词个数
Job job = Job.getInstance(conf,"word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.33.131:9000/input"));
//FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job,tempDir); //输出存放在临时文件
job.waitForCompletion(true);
//对单词进行按照个数降序排序
Job sortJob = Job.getInstance(conf,"sort");
sortJob.setJarByClass(WordCount.class);
sortJob.setMapperClass(InverseMapper.class);
sortJob.setNumReduceTasks(1);
sortJob.setOutputKeyClass(IntWritable.class);
sortJob.setOutputValueClass(Text.class);
sortJob.setSortComparatorClass(DecreasingComparator.class);
sortJob.setInputFormatClass(SequenceFileInputFormat.class);
FileInputFormat.addInputPath(sortJob, tempDir); //从临时文件输入
FileOutputFormat.setOutputPath(sortJob, new Path("hdfs://192.168.33.131:9000/output/output999"));
//FileOutputFormat.setOutputPath(sortJob, new Path(args[1]));
sortJob.waitForCompletion(true);
//删除临时存放的文件
FileSystem fs = FileSystem.get(conf);
fs.delete(new Path("/output/temp"),true);
fs.close();
System.exit(0);
}
}
打包后放到Linux,如下:
执行程序hadoop jar /home/kingssm/wordCountSort-1.2.jar test.WordCountSort
这里没有输入路径和输出路径,那是因为我在程序里面已经通过远程连接的方式确定了路径

执行结果如下:

查看结果是否已经排序:
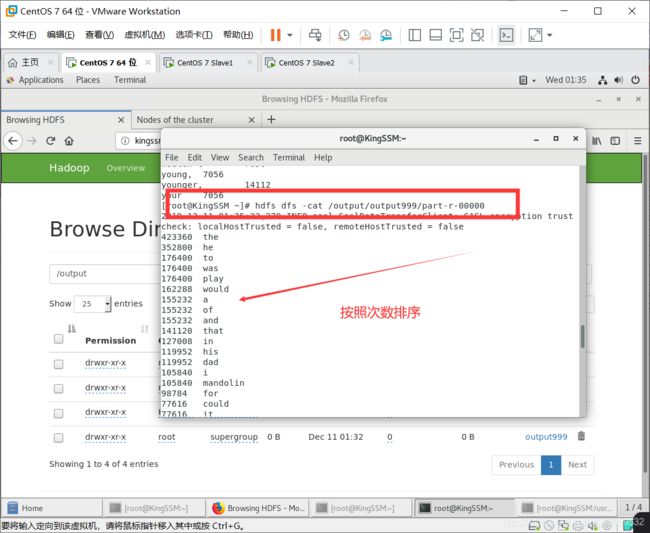
常见问题
问题一:找不到主类,因为这是我们自己创建的类,打包的时候也没有指定主类,所以在运行时不能像运行官方例子那样只输入类名,我们要在类名前面加上包名
问题二:运行时有些类找不到,查看是不是创建多个Job的原因,像本例中创建了两个Job,一个用于实现统计,一个用于实现排序,每个Job都要添加job.setJarByClass(WordCount.class);
