Spark UDF Java 示例
在这篇文章中提到了用Spark做用户昵称文本聚类分析,聚类需要选定K个中心点,然后迭代计算其他样本点到中心点的距离。由于中文文字分词之后(n-gram)再加上昵称允许各个特殊字符(数字、字母、各种符号……),如果直接在原来的文本数据上进行聚类,由于文本的“多样性”,聚类效果并不一定好。因此准确对昵称先进行一个预分类的过程,这里的分类不是机器学习里面的分类算法(逻辑回归、线性回归),而是根据昵称文本的特征进行分类:给定一个文本昵称字符串,分类方法逐个地将每个字符转换成定义好的模式:
即将所有汉字替换成H、所有大写字母替换成U、小写字母替换成L、数字替换成N,其他各种符号替换成O,然后系统将每一个字符串表示成能标识其组成的字符串模式。
例如用户名:“你好abc123”会被表示成HHLLLNNN,而“你好aaa456”也会被标识成HHLLLNNN。
这样相同的字符串模式的字符将获得相同的表示。
而这里采用Spark 用户自定义函数来实现这种转换。然后再在每个预分类下,进行聚类。
Spark 用户自定义函数介绍
在Java里面通过实现接口UDF(一共定义了22个吧,根据不同参数个数进行选择)来定义一个Spark UDF,简单一点的UDF可以使用Lambda表达式。具体介绍可参考官方文档。如下的NickFormatterUDF接收一个字符串作为输入,将该字符串转换成 由 HLUNWO 组成的字符串模式。
import org.apache.spark.sql.api.java.UDF1;
/**
* @author psj
* @date 2018/11/16
*/
public class NickFormatterUDF implements UDF1 {
@Override
public String call(String nick) throws Exception {
StringBuilder pattern = new StringBuilder();
for (int i = 0; i < nick.length(); i++) {
char ch = nick.charAt(i);
if (ParseChar.isChinese(ch)) {
pattern.append('H');
} else if (ParseChar.isLowerCase(ch)) {
pattern.append('L');
} else if (ParseChar.isUpperCase(ch)) {
pattern.append('U');
} else if (ParseChar.isNumber(ch)) {
pattern.append('N');
} else if (ParseChar.isWhiteSpace(ch)) {
pattern.append('W');
}else{
pattern.append('O');
}
}//END FOR
return pattern.toString();
}
} ParseChar.java就是一个简单地判断某个字符是中文字符、还是数字、还是大写字母、还是小写字母的工具类。
public class ParseChar {
public static boolean isChinese(char ch) {
//获取此字符的UniCodeBlock
Character.UnicodeBlock ub = Character.UnicodeBlock.of(ch);
// GENERAL_PUNCTUATION 判断中文的“号
// CJK_SYMBOLS_AND_PUNCTUATION 判断中文的。号
// HALFWIDTH_AND_FULLWIDTH_FORMS 判断中文的,号
if (ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS || ub == Character.UnicodeBlock.CJK_COMPATIBILITY_IDEOGRAPHS
|| ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS_EXTENSION_A || ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS_EXTENSION_B
|| ub == Character.UnicodeBlock.CJK_SYMBOLS_AND_PUNCTUATION || ub == Character.UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS
|| ub == Character.UnicodeBlock.GENERAL_PUNCTUATION) {
// System.out.println(ch + " 是中文");
return true;
}
return false;
}
public static boolean isNumber(char ch) {
return ch >= '0' && ch <= '9';
}
public static boolean isLowerCase(char ch) {
return ch >= 'a' && ch <= 'z';
}
public static boolean isUpperCase(char ch) {
return Character.isUpperCase(ch);
}
public static boolean isWhiteSpace(char ch) {
return Character.isWhitespace(ch);
}
}写完了自定义函数,接下来看看在Spark中如何调用自己定义的函数。在这里我碰到了很多奇怪的问题。我们的样本数据如下:
{"created":1542020126816,"nick":"a357410","uid":123456}
{"created":1542020138522,"nick":"alichao","signature":"┌?┐?┊雨┊?┊蒙┊?┊蒙┊?└?┘","uid":123456}
{"created":1542020127633,"details":"走过了之后才明白,往事是用来回忆的,幸福是用来感受的,伤痛是用来成长的。。。。","nick":"菲儿","signature":"游戏有你更精彩","uid":123456}
可以看出,样本数据中即有昵称字符、又有签名字段、还有created 字段……而我们只针对昵称字段进行预分类。
首先将样本数据nick_class.json上传到HDFS:
./bin/hdfs dfs -put ~/data_spark/nick_class.json /user/xxx/
然后程序中加载数据:
Dataset dataset = spark.read().format("json").option("header", "false")
.load("hdfs://localhost:9000/user/xxx/nick_class.json");
dataset.show(10);
对样本中昵称为空的字段进行过滤,并只选取昵称字段应用到Spark UDF上:
Dataset nickDataset = dataset.filter(col("nick").isNotNull()).select(col("nick"));
nickDataset.show();
nickDataset.printSchema();
先来一个简单一点的Spark中内置的UDF函数:小写字母转换成大写,哈哈。
UserDefinedFunction mode = udf(
(String nick) -> nick.toUpperCase(), DataTypes.StringType);
Dataset upperNickDataFrame = nickDataset.select(mode.apply(col("nick")));
System.out.println(upperNickDataFrame.count());
upperNickDataFrame.show();对昵称字符串进行分类的用户自定义函数NickFormatterUDF.java。创建对象注册到SparkSession中即可,创建临时视图就是方便后面可通过SQL形式对nickDataFrame进行调用。
UDF1 nickPreClassificationUDF = new NickFormatterUDF();
spark.udf().register("nick_classifier", nickPreClassificationUDF, DataTypes.StringType);
nickDataset.createOrReplaceTempView("nickDataFrame"); 通过functions.callUDF调用UDF:
Dataset nickClassifyDF = nickDataset.select(functions.callUDF("nick_classifier", col("nick")));
System.out.println(nickClassifyDF.count());
nickClassifyDF.show();Spark作业提交运行
在这篇文章中介绍搭建Spark远程调试开发环境,本以为能够在远程调试环境中运行,但每次执行到 upperNickDataFrame.show();或者 nickClassifyDF.show();就抛出异常:
java.lang.ClassCastException: cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD
at java.io.ObjectStreamClass$FieldReflector.setObjFieldValues一直以为是自定义函数的bug,找了好久没有找到原因,后来在SPARK-18075发现:原来是Spark提交作业的方式有问题。
在自己的Intellij 开发环境下以debug调试运行Spark应用程序固然方便,但这不符合官方推荐的以打成jar包的方式运行Spark作业这种方式。
It is very convenient to write Spark code in an IDE as part of a larger application framework and test it in development by simply running the main function, instead of packaging it into a jar for every single change and submitting this jar to a cluster. Often you have to run it on a remote cluster even for development, especially when handling large quantities of data.
于是:mvn package 将这种工程打成nick_classifier.jar包,上传到服务器上。以命令:./spark-2.3.1-bin-hadoop2.7/bin/spark-submit --class net.hapjin.spark.nick.SparkNickPreClassification nick_classifier.jar
结果还是报同样的错误,或者连接拒绝错误。出现这个问题,主要是环境配置不一致的问题:
- 程序代码里面创建SparkSession时,需要指定Spark Master地址,这个地址是填
spark://ip:port,还是填spark://master_name:port,还是填spark://localhost:port这个要视集群配置而定了。 - 第二个是:
/etc/hosts里面配置的主机名到ip地址的映射 - 第三个是
conf/spark-env.sh里面的参数:SPARK_LOCAL_IP的设置。
记录一下我在实验环境下运行的结果:
spark-2.3.1-bin-hadoop2.7、hadoop-2.7.7、按hadoop官网的Standalone Operation方式配置启动HDFS。
以./spark-2.3.1-bin-hadoop2.7/bin/spark-submit --class net.hapjin.spark.nick.SparkNickPreClassification nick_classifier.jar提交运行。
源码如下:
package net.hapjin.spark.nick;
import org.apache.spark.sql.*;
import org.apache.spark.sql.api.java.UDF1;
import org.apache.spark.sql.expressions.UserDefinedFunction;
import org.apache.spark.sql.types.DataTypes;
import static org.apache.spark.sql.functions.col;
import static org.apache.spark.sql.functions.udf;
/**
* @author psj
* @date 2018/11/16
*/
public class SparkNickPreClassification {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder().appName("nick_classification")
.master("local[*]")
.getOrCreate();
Dataset dataset = spark.read().format("json").option("header", "false")
.load("hdfs://localhost:9000/user/xxx/nick_class.json");
dataset.show(10);
Dataset nickDataset = dataset.filter(col("nick").isNotNull()).select(col("nick"), col("uid"));
nickDataset.show();
nickDataset.printSchema();
//https://stackoverflow.com/questions/28186607/java-lang-classcastexception-using-lambda-expressions-in-spark-job-on-remote-ser
// spark.udf().register("udfUpperCase", (String string) -> string.toUpperCase(), DataTypes.StringType);
// Dataset df = nickDataset.withColumn("upper", callUDF("udfUpperCase", nickDataset.col("nick")));
// System.out.println(df.count());
// df.show();
//https://issues.apache.org/jira/browse/SPARK-18075
//没有按标准来运行spark app jar
UserDefinedFunction mode = udf(
(String nick) -> nick.toUpperCase(), DataTypes.StringType);
Dataset upperNickDataFrame = nickDataset.select(mode.apply(col("nick")));
System.out.println(upperNickDataFrame.count());
upperNickDataFrame.show();
UDF1 nickPreClassificationUDF = new NickFormatterUDF();
spark.udf().register("nick_classifier", nickPreClassificationUDF, DataTypes.StringType);
nickDataset.createOrReplaceTempView("nickDataFrame");
// spark.sql("select uid, nick_classifier(nick) from nickDataFrame").show();
Dataset nickClassifyDF = nickDataset.select(functions.callUDF("nick_classifier", col("nick")), col("nick"), col("uid"));
System.out.println(nickClassifyDF.count());
//https://stackoverflow.com/questions/39953245/how-to-fix-java-lang-classcastexception-cannot-assign-instance-of-scala-collect
nickClassifyDF.show();
}
}
最终运行出来的结果:可以看出已经成功地将昵称转换成 自定义的 字符模式。左边列就是每个昵称的模式,右边列是实际的昵称。比如第一行:UU 代表两个大写的英文字符,而左边的nick是"JX"(意味着将所有 两个大写字母 的昵称 转换成类别 UU 了)
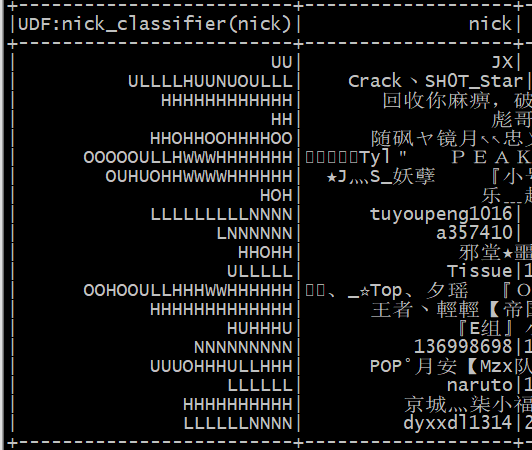
后面会将 这些自定义的字符模式 归为几个类别,然后在每个类别上进行聚类分析。
参考资料:
[基于层次聚类的虚假用户检测]
Spark Java API 计算 Levenshtein 距离
Spark Java API 之 CountVectorizer
spark JAVA 开发环境搭建及远程调试