2020.8.15课堂笔记(sql执行流程)
一条更新语句是如何执行的?
在数据库里,update是包括了更新,删除,插入
更新的流程和查询的流程有什么不同,
前面的基本流程是一致的,经过解析器 优化器 最终交给执行器,后面不同,拿到了一个符合条件的数据之后。
update user_innodb set name=’pengyuyan’ where id=1;
在InnoDB里面,数据都是放在磁盘上的,把磁盘的数据加载到内存的最小单位叫做页page
对于数据的操作并不是每一次都直接操作磁盘,把磁盘读到的页的信息放到了内存的区域,叫做bufferpool缓冲池,先去判断是不是在缓冲池里,如果在的话就会直接修改缓冲池里的页。在内存里修改了数据,内存与磁盘数据不一致的时候,我们就把这个数据叫做脏页,dirty page
内存的数据是怎样同步到磁盘的?后台工作的线程隔一段时间就把buffer pool的数据写入到磁盘里,把这个过程叫做刷脏。一个页在InnoDB里是16k的大小
buffer pool内部结构: buffer pool本身和一个自适应hash索引

把一部分的索引的数据也放到了内存,数据页和索引页
show status like ‘%innodb_buffer_pool%’;
buffer pool默认的大小是128M 内存
show VARIABLES like ‘%innodb_buffer_pool%’;
划分的内存的区域写满了怎么办 LRU 最近最少使用的算法
把buffer pool分成 young old两块 留下来热点的数据
对提升读写性能有非常大的作用
优化的方案?
如果不在内存里,至少要发生一次IO 如果不是唯一索引,在修改数据的时候并不需要对磁盘已经存在的数据做对比来判断唯一性,这种情况,记录在change buffer里,在5.5版本前叫做insert buffer现在改名叫change buffer 以前只能缓冲插入的数据,是同一个概念,现在也支持delete 和 update了
同步记录的数据页的过程叫做merge
1、 访问这个数据页的时候,如果还在change buffer里
2、 有后台线程定时把内存区域的数据同步到磁盘,减少不一致性
3、 正常关机的时候会把内存数据同步到磁盘
4、 redo log写满的时候
show variables like ‘%change_buffer%’ 占buffer pool的大小,默认是25%,写多读少的时候可以调高比例,提升修改数据的效率而设置的区域
log buffer脏页还没有刷入到磁盘,机器宕机了,是逐步进行的,如果只写入了一半,对于页面的修改操作 从日志文件尝试恢复操作
crash-safe 这个日志叫做redo log ib_logfile0 ib_logfile1 一个文件默认是48M
先写日志再把数据同步到磁盘的操作叫做WAL的技术,write ahade logging
写日志和写磁盘有区别么?
什么叫做随机I/O 顺序I/O
随机IO磁盘一个最小组成的单元叫做扇区,通常是512个字节,操作系统和内存打交道,最小的单位叫做页,操作系统和磁盘打交道,最小的单位叫做块,block ,内存到磁盘文件刷盘的操作是随机IO
顺序I/O数据都是相邻的,不需要寻址了,依次去拿到数据,比随机IO效率高得多,记录日志的操作是顺序IO,先把修改写入日志文件,延迟磁盘的刷盘的时机,来提升系统的吞吐量
写入到redo log也不是每一次都要去操作磁盘,有一块内存区域是用来保存即将要写入磁盘里的数据,log buffer大小是16M
redo log主要用来做崩溃恢复的,写入的时候还是从内存缓冲区buffer pool刷盘到磁盘的
刷盘:操作系统缓存 OS Cache/buffer 到磁盘文件 每秒钟执行一次
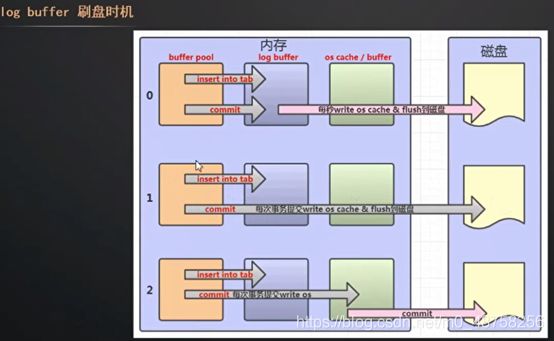
log buffer是什么时候写入的
redo log特点:
1、 InnoDB
2、 物理日志,记录的不是数据页更新之后的状态,而是记录这个页做了什么改动
3、 redo log大小是固定的48M 写入到后面的时候会把前面的覆盖
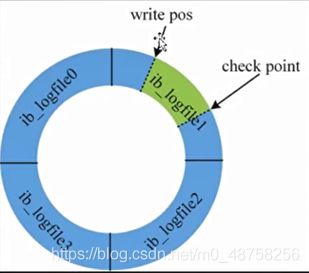
4、 写满了触发一个刷盘的操作
5、 redo log默认是2个,也可以设置成4个
表空间分成了5大类
1、 系统的表空间 System Tablespace 共享的表空间
2、 数据字典(InnoDB Data Dictionary)定义了一些表和索引的元数据
3、 双写缓冲(InnoDB重要的特性 双写)
4、 Change buffer
5、 Undo logs撤销/回滚的日志,记录的事物发生之前的状态,只要修改才会出现undo,select是没有的,从逻辑上恢复到事物之前的状态,逻辑的日志
Undo log+Redo log=事务日志
有一个参数innodb_file_per_table
更新的流程:
set name =’pengyuyan’ where id=1;
1、 从内存或磁盘取到数据
2、 执行器 pengyuyan
3、 undo log redo log
4、 buffer pool 把name=’pengyuyan’
5、 后台线程写入磁盘
服务层也有一个日志文件:binlog
可以被所有的存储引擎共用的,以事件的形式去记录了所有的DDL DML 逻辑的日志
用来做主从:
数据的恢复:找到某一个节点的sql语句去重新执行一遍
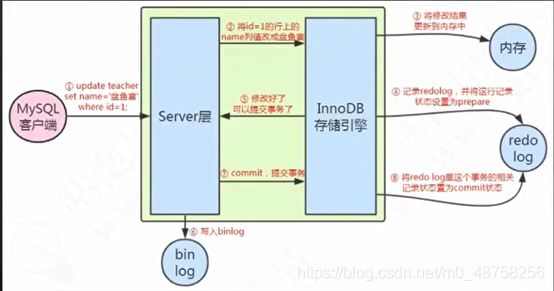
重点:
1、 更新的语句是先记录到内存再写日志文件的
2、 记录redo log分成两个阶段 prepare commit
3、 先在存储引擎层记录redo log 和 undo log 再在server层记录bin log
33、查询各个课程及相应的选修人数;
SELECT corse_id,COUNT(corse_id)
FROM tb_score
GROUP BY corse_id;
35、查询每门课程成绩最好的前两名;
SELECT a.corse_id,a.scores FROM tb_score a
WHERE (
SELECT COUNT(scores) FROM tb_score b
WHERE a.scores
ORDER BY a.corse_id,scores DESC;
36、检索至少选修两门课程的学生学号;
SELECT stu_id
FROM tb_score
GROUP BY stu_id
HAVING COUNT(corse_id)>2;
37、查询全部学生都选修的课程的课程号和课程名;
SELECT corse_id,cname FROM tb_score
JOIN tb_course ON cid=corse_id
GROUP BY corse_id
HAVING COUNT(stu_id)=9;
38、查询没学过“罗鑫”老师讲授的任一门课程的学生姓名;
SELECT sname FROM tb_student s WHERE s.sid NOT IN(
SELECT sc.stu_id FROM tb_score sc
JOIN tb_course c ON c.cid=sc.corse_id
JOIN tb_teacher t ON t.tid=c.teacher_id
WHERE t.tname=‘罗鑫’
GROUP BY stu_id
);
38、查询两门以上不及格课程的同学的学号及其平均成绩;
SELECT sc.stu_id,AVG(sc.scores) FROM tb_score sc
WHERE scores<92
GROUP BY stu_id
HAVING COUNT(corse_id)>2;
39、检索“004”课程分数小于60,按分数降序排列的同学学号;
SELECT stu_id,scores FROM tb_score
WHERE scores<95 AND corse_id=4
ORDER BY scores DESC;
42、查询“kb03”班的学生人数
SELECT COUNT(sid) FROM tb_student
WHERE class_id=(SELECT cid FROM tb_class WHERE cname=‘KB03’)
GROUP BY class_id;
43、查询“罗鑫“教师任课的学生平均成绩
SELECT AVG(scores) FROM tb_score
WHERE corse_id IN(SELECT cid FROM tb_course WHERE teacher_id=(SELECT tid FROM tb_teacher WHERE tname=‘罗鑫’)
);
45、查询成绩比该课程平均成绩低的同学的成绩表
SELECT * FROM tb_score sc
JOIN
(SELECT corse_id,AVG(scores) avg_s FROM tb_score GROUP BY corse_id
) sc1 ON sc.corse_id=sc1.corse_id
WHERE sc.scores < sc1.avg_s;
46、查询至少有3名女生的班号
SELECT class_id FROM tb_student
WHERE gender=‘女’
GROUP BY class_id,gender
HAVING COUNT(gender)>1;
48、查询分别展示男,女学员的平均成绩
SELECT gender,AVG(scores) FROM tb_score sc
JOIN tb_student s ON s.sid=sc.stu_id
GROUP BY s.gender;
49、查询选修某课程的同学人数多于5人的教师姓名
SELECT c.cname,t.tname FROM tb_score sc
JOIN tb_course c ON c.cid=sc.corse_id
JOIN tb_teacher t ON t.tid=c.teacher_id
GROUP BY corse_id
HAVING COUNT(corse_id)>5;
50、查询课程表中至少有5名学生选修的并以java开头的课程的平均分数
SELECT AVG(scores) FROM tb_score
WHERE corse_id IN (SELECT cid FROM tb_course WHERE cname LIKE ‘java%’)
GROUP BY corse_id
HAVING COUNT(stu_id)>5;